






1.pytorch 基础练习
此部分为pytorch的一些基础操作,较为简单所以在自己电脑上运行。
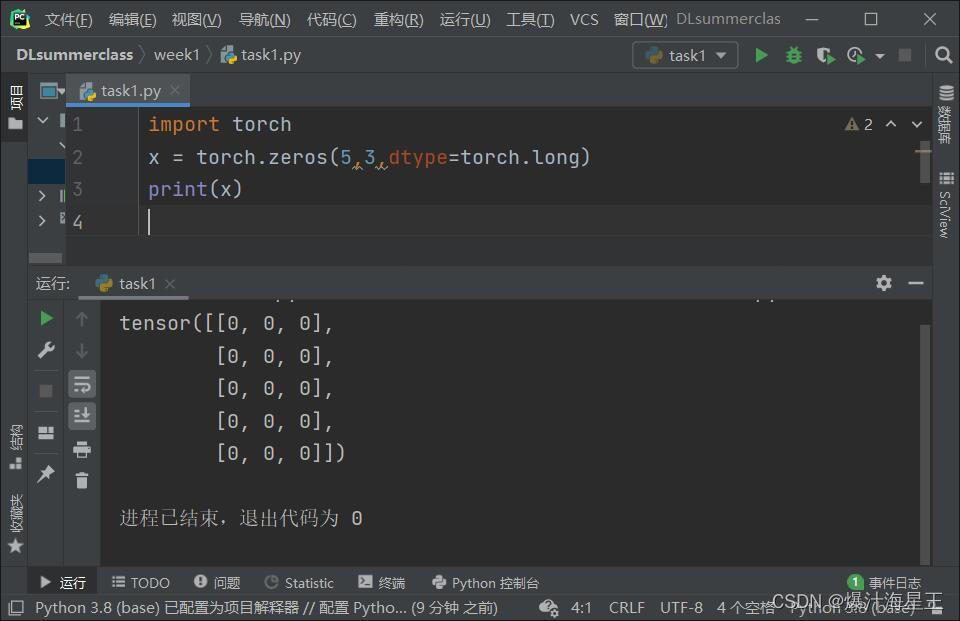
torch.zeros():生成指定大小的全零张量
torch.arange():生成一个左闭右开区间连续元素的张量。
使用@计算两个张量的标量积,注意两个张量的元素都应是float类型。
使用plt画图展示产生的随机数

torch.cat():将两个张量进行拼接
2.螺旋数据分类
此部分在colab上进行,先展示一下如何解决无法注册谷歌账号的问题。
首先需要翻墙,这个就同学们各显神通吧。进入谷歌云盘进行注册。可能会出现手机号无法验证的问题。

需要对浏览器进行设置,将浏览器的语言改为英语,删除中文,重启浏览器。

此时进入谷歌网盘应该是英文界面,如果不是将语言选择为英语。即可完成注册。

首先是一个只有两层全连接没有激活函数的网络,由于没有激活函数所以只能进行线性的分类,最终的分类结果也是不太理想的。
在全连接层中间加入relu激活函数,给网络引入非线性,此时网络可以较好的完成分类任务。
3.问题总结
1、AlexNet有哪些特点?为什么可以比LeNet取得更好的性能?
首先AlexNet比LeNet更深更宽,将激活函数由sigmoid改为更简单的ReLU,并通过dropout来控制模型复杂度,同时AlexNet引入了图像增广。ReLU可以提供一个稳定的梯度提高收敛速度,通过丢弃法可以抑制过拟合提高模型的泛化性,图像增广提高了数据的丰富性,所以AlexNet可以取得比LeNet更好的性能。
2、激活函数有哪些作用?
激活函数给模型引入了非线性,如果没有激活函数只通过卷积和全连接的组合是无法拟合非线性函数的,所以再深再大的网络都不会有更好的性能,加入激活函数后让“深度”学习成为可能。
3、梯度消失现象是什么?
梯度消失是指在梯度传递的过程中趋近于0,而导致权重几乎不改变的现象,这使得权重几乎不更新,而无法收敛到更好的解。这一般是由于网络太深,小梯度叠加而趋于0,或者激活函数不合适,在靠近最优点时梯度过小导致的。
4、神经网络是更宽好还是更深好?
我猜是更深好,哈哈哈哈。其实过于宽和深都不会有很好的效果,网络的构造还是和数据大小、复杂程度、任务的复杂度等有关,构造适合数据和任务的模型。但其实在残差引入卷积网络之前模型并做不了太深,几十层的网络就已经难以训练也没有很好的性能了,在残差结构引入后深度学习才真正快速发展起来。
5、为什么要使用Softmax?
Softmax函数可以将多个输出转为概率,在多分类任务中,多个输出值对于我们是没有意义的,我们想要的是这个样本属于每个类别的概率,所以通过Softmax将输出值转为概率值。
6、SGD 和 Adam 哪个更有效?
按照我的经验来看SGD更有效,SGD可以最终收敛到一个更好的水平。但是Adam收敛会更快,且对超参数不那么敏感,且在大部分情况下也不会差SGD太多,所以Adam还是更常用的优化器。















 104
104











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









