






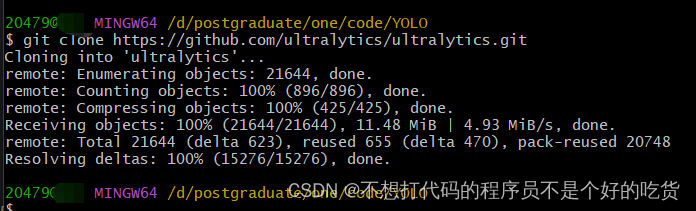
拉取源代码
git clone https://github.com/ultralytics/ultralytics.git
安装依赖
我是使用pycharm打开项目,如果重新创建一个虚拟环境,就需要重新下载pytorch等包。
我为了方便就给项目配置了之前装好的虚拟环境(建议如果之前有配置好虚拟环境,把配好的虚拟环境复制一个新的,给项目配新的虚拟环境,这样方便后续跑别的项目)
pip install ultralytics
pip install yolo
两个都要安装。安装好ultralytics包之后才可以使用要使用yoloCLI。
推理
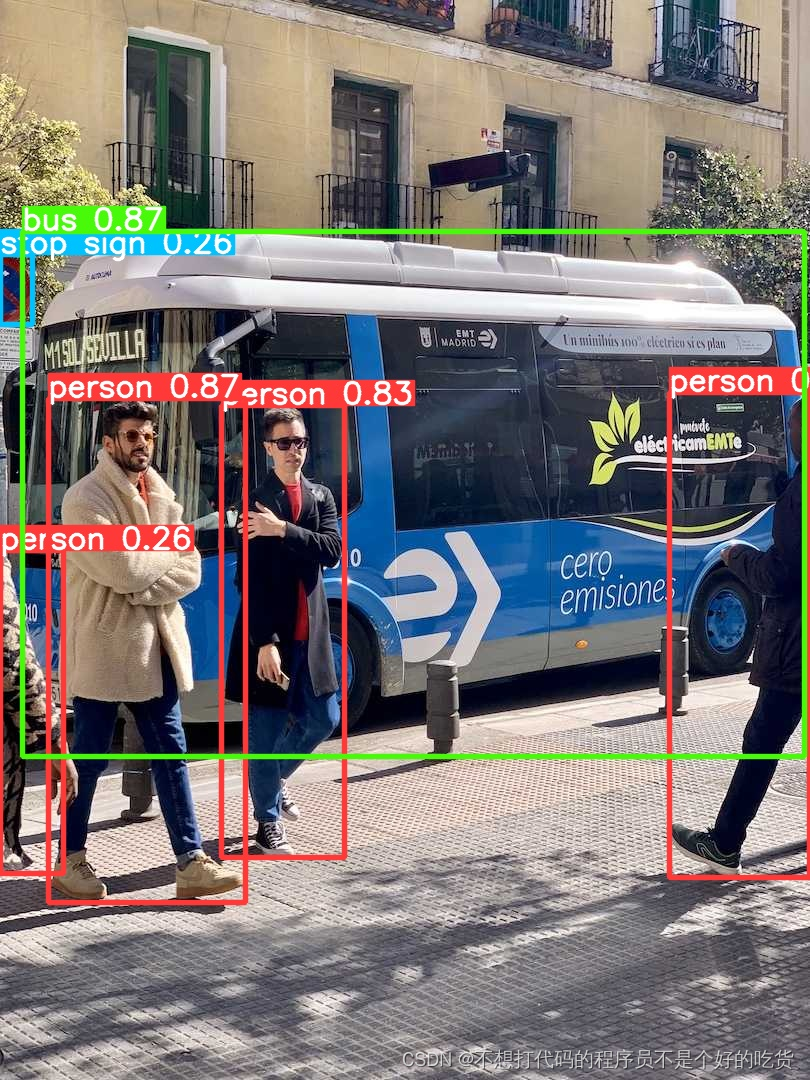
yolo task=detect mode=predict model=yolov8n.pt source='ultralytics/assets/bus.jpg' show=True
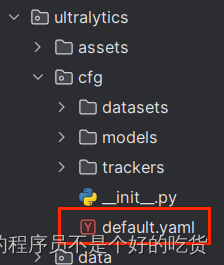
关于参数的解释在default.yaml中,文件位置可能会不一样(yolo v8更新很快)
!!!报错来了
ImportError: cannot import name 'COMMON_SAFE_ASCII_CHARACTERS' from 'charset_normalizer.constant'
参考博客:已解决ImportError: cannot import name COMMON_SAFE_ASCII_CHARACTERS‘ from charset-normalizerconstant‘
本人解决办法:
pip install --upgrade charset-normalizer
再次运行推理命令依旧报错

参考博客:YOLOv8报错Error: No such command ‘predict‘.
本人解决办法:
python setup.py install
再次运行推理命令就成功了
使用自己的数据集训练
在项目下面新建一个datasets文件夹,里面存放数据集。
data.yaml:
train: D:/postgraduate/one/code/YOLO/ultralytics/datasets/train/images
val: D:/postgraduate/one/code/YOLO/ultralytics/datasets/valid/images
test: D:/postgraduate/one/code/YOLO/ultralytics/datasets/test/images
nc: 1
names: ['crack']
nc是分类数,我的数据集全是裂缝,所以nc为1.
最好使用绝对路径,因为相对路径容易出错(正是本人)
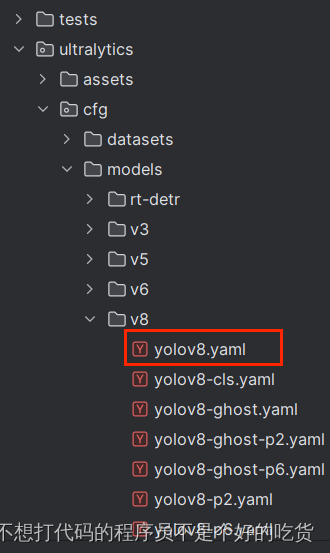
yolov8.yaml:只需要将源代码中的文件粘贴过来,修改nc值。
OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.
OMP: Hint This means that multiple copies of the OpenMP runtime have been linked into the program. That is dangerous, since it can degrade performance or cause incorrect results. The best thing to do is to ensure that only a single OpenMP runti
me is linked into the process, e.g. by avoiding static linking of the OpenMP runtime in any library. As an unsafe, unsupported, undocumented workaround you can set the environment variable KMP_DUPLICATE_LIB_OK=TRUE to allow the program to continue to execute, but that may cause crashes or silently produce incorrect results. For more information, please see http://www.intel.com/software/products/support/.
参考:关于OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.错误解决方法
数据集处理
.json格式标注文件转换为yolo格式
我的建议是让chat写
import json
import os
def convert_to_yolo(json_file, yolo_file):
with open(json_file, 'r') as f:
data = json.load(f)
labels = data['labels']
image_width = data['labels'][0]['size']['width']
image_height = data['labels'][0]['size']['height']
yolo_labels = []
for label in labels:
class_name = 0 if label['name'] == 'crack' else label['name']
x1 = label['x1']
y1 = label['y1']
x2 = label['x2']
y2 = label['y2']
# Convert coordinates to YOLO format
x_center = (x1 + x2) / 2 / image_width
y_center = (y1 + y2) / 2 / image_height
width = abs(x2 - x1) / image_width
height = abs(y2 - y1) / image_height
# Append YOLO format annotation to the list
yolo_labels.append(f"{class_name} {x_center} {y_center} {width} {height}")
# Create the output directory if it doesn't exist
os.makedirs(os.path.dirname(yolo_file), exist_ok=True)
# Write YOLO format annotations to file
with open(yolo_file, 'w') as f:
f.write('\n'.join(yolo_labels))
print(f"Conversion completed. YOLO format annotations saved to '{yolo_file}'.")
# 使用示例
json_dir = 'D:/postgraduate/one/data/data500/labels/'
yolo_dir = 'D:/postgraduate/one/data/data500/labelsyolo/'
# 遍历JSON文件夹中的所有文件
for filename in os.listdir(json_dir):
if filename.endswith('.json'):
json_file = os.path.join(json_dir, filename)
yolo_file = os.path.join(yolo_dir, filename.replace('.json', '.txt'))
convert_to_yolo(json_file, yolo_file)
将数据集分为训练,测试,验证集
参考B站视频:【yolov8】从0开始搭建部署YOLOv8,环境安装+推理+自定义数据集搭建与训练,一小时掌握
import os
import random
from tqdm import tqdm
# 指定 images 文件夹路径
image_dir = "D:/postgraduate/one/data/data500/images"
# 指定 labels 文件夹路径
label_dir = "D:/postgraduate/one/data/data500/labelsyolo"
# 创建一个空列表来存储有效图片的路径
valid_images = []
# 创建一个空列表来存储有效 label 的路径
valid_labels = []
# 遍历 images 文件夹下的所有图片
for image_name in os.listdir(image_dir):
# 获取图片的完整路径
image_path = os.path.join(image_dir, image_name)
# 获取图片文件的扩展名
ext = os.path.splitext(image_name)[-1]
# 根据扩展名替换成对应的 label 文件名
label_name = image_name.replace(ext, ".txt")
# 获取对应 label 的完整路径
label_path = os.path.join(label_dir, label_name)
# 判断 label 是否存在
if not os.path.exists(label_path):
# 删除图片
os.remove(image_path)
print("deleted:", image_path)
else:
# 将图片路径添加到列表中
valid_images.append(image_path)
# 将label路径添加到列表中
valid_labels.append(label_path)
# print("valid:", image_path, label_path)
# 遍历每个有效图片路径
for i in tqdm(range(len(valid_images))):
image_path = valid_images[i]
label_path = valid_labels[i]
# 随机生成一个概率
r = random.random()
# 判断图片应该移动到哪个文件夹
# train:valid:test = 7:3:1
if r < 0.1:
# 移动到 test 文件夹
destination = "D:/postgraduate/one/code/YOLO/ultralytics/datasets/test"
elif r < 0.2:
# 移动到 valid 文件夹
destination = "D:/postgraduate/one/code/YOLO/ultralytics/datasets/valid"
else:
# 移动到 train 文件夹
destination = "D:/postgraduate/one/code/YOLO/ultralytics/datasets/train"
# 生成目标文件夹中图片的新路径
image_destination_path = os.path.join(destination, "images", os.path.basename(image_path))
# 移动图片到目标文件夹
os.rename(image_path, image_destination_path)
# 生成目标文件夹中 label 的新路径
label_destination_path = os.path.join(destination, "labels", os.path.basename(label_path))
# 移动 label 到目标文件夹
os.rename(label_path, label_destination_path)
print("valid images:", valid_images)
#输出有效label路径列表
print("valid labels:", valid_labels)















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









