







 PCT是基于Transformer的点云处理框架,通过顺序不变性和优化的offset-attention模块,适应点云数据无序和局部几何信息的需求。实验表明,PCT在点云分类、分割和法线估计任务上达到最新水平。
PCT是基于Transformer的点云处理框架,通过顺序不变性和优化的offset-attention模块,适应点云数据无序和局部几何信息的需求。实验表明,PCT在点云分类、分割和法线估计任务上达到最新水平。
PCT: Point Cloud Transformer
1. Introduction
transformer是一种 encoder-decoder结构,包含了三个模块:输入词嵌入,位置(顺序)编码和self-attention 。其中self-attention是核心组件,基于全局上下文的输入特征,生成精确的 attention 特征。
首先,self-attention 将输入词嵌入和位置编码的总和作为输入,通过训练有素的线性层为每个单词计算三个向量:query,key 和 value。然后,可以通过匹配(点积)查询和 key 向量来获取任意两个 word 之间的 attention 权重。最后,attention feature 定义为所有 value 向量与 attention 权重的加权和。
显然每个 word 的输入 attention feature 与所有的输入特征都有关,因此能够学习全局上下文。transformer 的所有操作均可并行执行与顺序无关。理论上讲,可以代替卷积神经网络计算中的卷积运算,并且有更好的通用性。
PCT 的主要思想是通过使用 transformer 固有的顺序不变性来避免定义点云数据的顺序和通过 attention 机制来进行特征学习。如图 1 所示,attention 权重的分布与部分语义高度相关,并且不会随着空间距离而严重衰减。
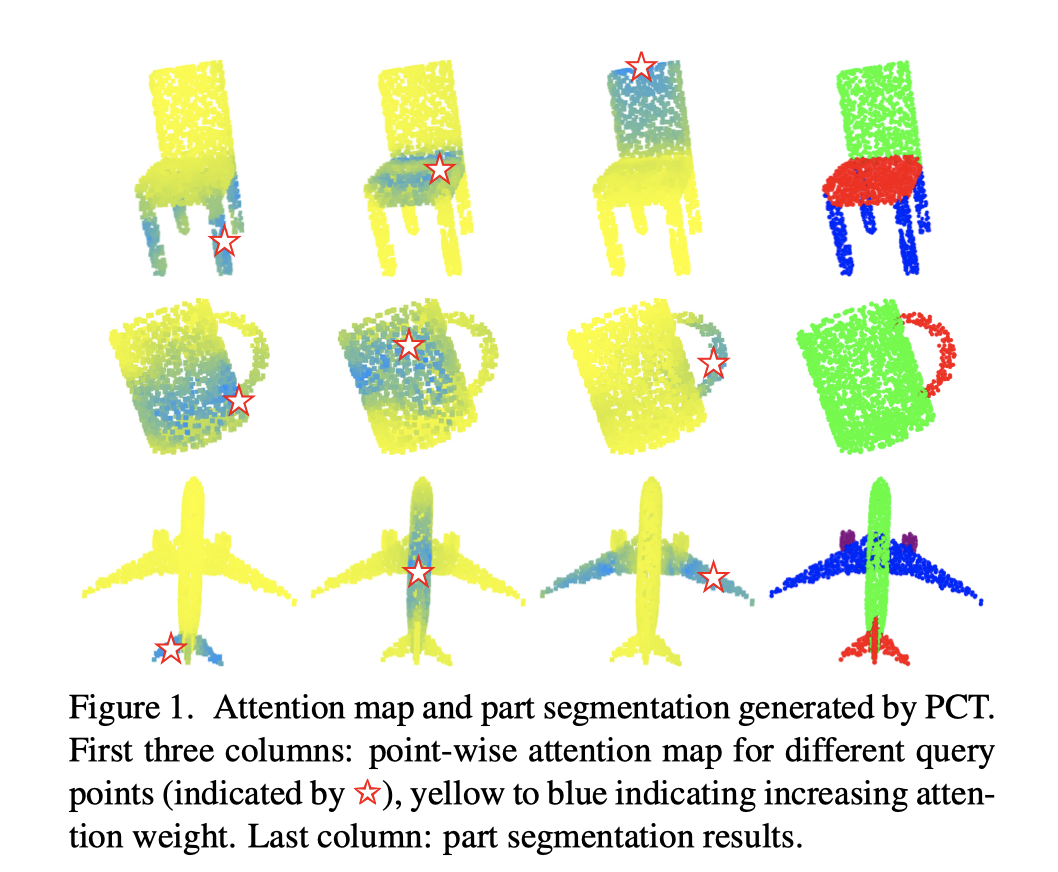
由于点云数据和自然语言数据截然不同,PCT 对其进行了一系列调整。
- 基于坐标的输入嵌入模块。在 transformer中使用了位置编码模块来表示自然语言中的单词顺序,这样可以区分在不同位置的同一单词并且反映出单词间的位置关系。但是,点云无固定顺序。因此在PCT 框架中,我们将原始的位置编码和输入嵌入合并到基于坐标的输入嵌入模块。可以生成可区分的特征,因为每个点都有代表其空间位置的唯一坐标。
- 优化的偏移 attention 模块。PCT 对原始的 self-attention 进行升级。它通过使用self-attention模块的输入和 attention feature 之间的偏移来替代 attention feature。首先,绝对坐标可以通过刚性转换变成相对坐标,能够增强鲁棒性。其次,拉普拉斯矩阵在图卷积学习中十分有效。从这个角度看可以将点云看做一个图形,将“float”邻接矩阵作为attention graph。同样,我们将每行的总和缩放为 1。因此度矩阵可以被看做为恒等矩阵。因此,偏移 attention 优化过程可以理解成一个拉普拉斯过程(3.3)。此外,我们对第四节中介绍的偏移 attention 和 self-attention做了大量的对比实验来证明其有效性。
- 邻近嵌入模块(neighbor embedding)。显然句子中每个单词都包含基本的语义信息。但是这些点的独立输入坐标与语义内容之间的关系很小。attention 机制在捕获全局特征方面很有效,但是它可能会忽略局部几何信息,然而这点对于点云的学习是必不可少的。为了解决这个问题,我们使用邻近嵌入策略来改进点嵌入(point embedding)。它还通过考虑包含语义信息的局部点组而不是单个点之间的 attention 来辅助 attention 模块。
PCT 变得更适合点云特征学习,并在形状分类,零件分割和法线估计任务方面达到了最新水平。
Contributions:
- 提出了基于 transformer 的 PCT框架。
- 提出了带有隐式拉普拉斯算子和归一化修正的偏移 attention,与 self-attention 相比,更加适合点云学习。
- 大量实验表现,具有局部上下文增强效果的 PCT 在形状分类,零件分割和法线估计任务方面达到了 sota。
2. Related work
2.1 Transformer in NLP
Bahdanau等人最早提出带有attention机制 的神经机器翻译方法,attention 权重通过 RNN的隐藏层计算的。LIn 等人提出 self-attention,用来可视化和解释句子嵌入。在这之后出现了用于机器翻译的 transformer,它完全是基于 self-attention的,无任何重复和卷积运算符。之后又出现了 BERT(双向 transformer),这是 NLP 领域中最强大的模型之一。最近,诸如 XLNet,Transformer-XL 和 BioBERT 之类的语言学习网络进一步扩展了 Transformer 框架。
但是,在自然语言处理中输入是有序的,单个的单词有基本的语义,点云中的点是无序的并且单个点无语义信息。
2.2 Transformer for vision
受 ViT 使用的局部补丁结构和单词中的基本语义信息启发,我们提出了一个邻近嵌入模块,该模块可以聚合来自点的局部邻域的特征,从而捕获局部信息获取语义信息。
2.3. Point-based deep learning
一些其他方法也使用了 attention 机制和 transformer。PointASNL 用来处理点云处理中的噪声吗,它使用一种 self-attention 机制来更新局部点组的特征。PointGMM 用于具有 MLP 分割和 attentional splits 的形状插值。
PCT 基于 transformer,而不是使用 self-attention 作为辅助模块。我们的 PCT 是一个更加通用的框架,可以用于各种点云任务。
3. Transformer for Point Cloud Representation
在本节中,我们首先展示如何将PCT学到的点云表示形式应用于点云处理的各种任务,包括点云分类,零件分割和法线估计。我们首先介绍了 PCT 的naive 版本——直接使用原始的 transformer。然后介绍了具有特殊attention 机制的 PCT和近邻聚合(neighbor aggregation)用来提供增强的局部信息。
3.1. Point Cloud Processing with PCT
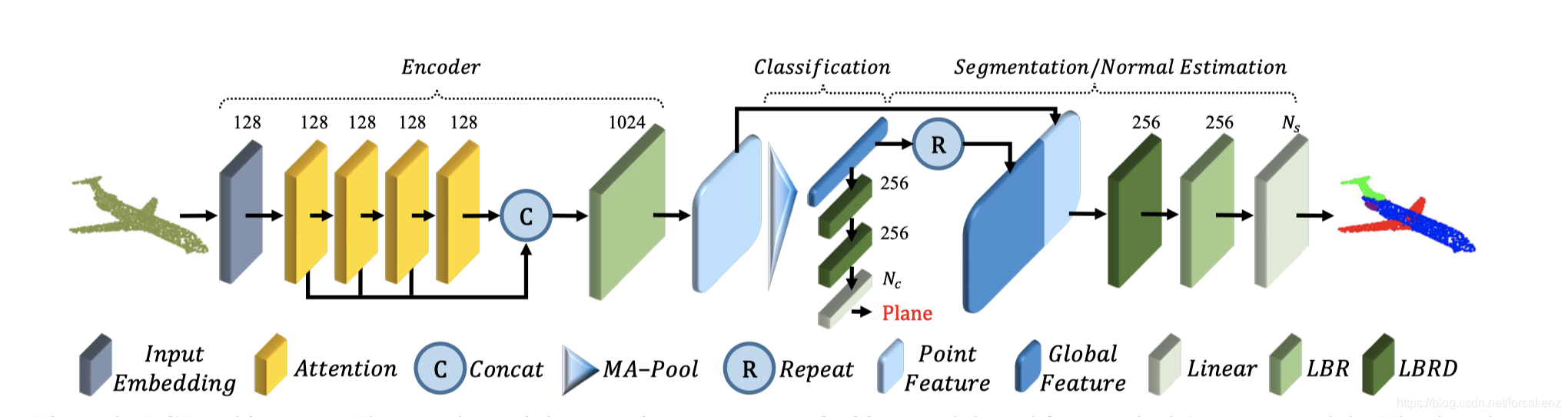
Encoder。PCT 旨在将输入点转化到新的高维特征空间,这个高维特征空间能够表征点之间的语义亲和力,以此作为各种点云处理任务的基础。PCT 的encoder 首先把输入坐标嵌入到新的特征空间中。嵌入的特征随后被馈入 4 个堆叠的 attention 模块来学习每个点的语义性的丰富且具有区别性的表示形式,紧接着是经过线性层生成输入特征。总体而言,PCT decoder 与原始的 transformer 有着几乎一样的设计理念,除了位置嵌入被舍弃外,因为该点的坐标已经包含这个信息。
输入点云( N × d N\times{d} N×d, N个点,每个点有d 维特征描述)。首先通过 Input Embedding 模块学习 d e d_e de维嵌入特征 F e ∈ R N × d e F_e\in{R^{N\times{d_e}}} Fe∈RN×de。然后通过每个 attention layer ,进行级联,然后进行线性变换来形成 d o d_o do维特征 F o ∈ R N × d o F_o\in{R^{N\times{d_o}}} Fo∈RN×do,
F 1 = A T 1 ( F e ) , F_1 = AT^1 (F_e), F1=AT1(Fe),
F i = A T i ( F i − 1 ) , i = 2 , 3 , 4 , F_i = AT^i (F_{i−1} ), i = 2, 3, 4, Fi=ATi(Fi−1),i=2,3,4,
F o = c o n c a t ( F 1 , F 2 , F 3 , F 4 ) ⋅ W o , F_o = concat(F_1 , F_2 , F_3 , F_4 ) · W_o , Fo=concat(F1,F2,F3,F4)⋅Wo,
W o W_o Wo代表线性层的权重。
要想获得高效的表示点云的全局特征向量 F g F_g F
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3148
3148

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









