







项目 | 内容 |
这个作业属于哪个课程 | |
这个作业的要求在哪里 | |
我在这个课程的目标是 | 通过结对编程完成项目 |
这个作业在哪个具体方面帮助我实现目标 | 在实践中体会、理解结对编程的优缺点 |
一、课程信息
教学班级:周四班
[独立]二、PSP表格记录估计开发时间
PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) |
Planning | 计划 | 60 |
· Estimate | · 估计这个任务需要多少时间 | 60 |
Development | 开发 | 1390 |
· Analysis | · 需求分析 (包括学习新技术) | 40 |
· Design Spec | · 生成设计文档 | 30 |
· Design Review | · 设计复审 (和同事审核设计文档) | 30 |
· Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 |
· Design | · 具体设计 | 90 |
· Coding | · 具体编码 | 840 |
· Code Review | · 代码复审 | 50 |
· Test | · 测试(自我测试,修改代码,提交修改) | 300 |
Reporting | 报告 | 180 |
· Test Report | · 测试报告 | 150 |
· Size Measurement | · 计算工作量 | 15 |
· Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 15 |
合计 | 1630 |
[独立]三、接口设计方法
Information Hiding
对于输入输出与计算功能的实现,我将其实现的子功能封装成各个函数(如下表),相互之间仅通过函数接口进行交互,不设置起交互作用的全局变量,以此实现了多个函数间的信息隐藏;对于封装的异常类,对其存储的异常信息设为private,仅通过public string print_exception()函数交互。
// declare func
boolis_end_word(charc);
stringget_next_word(FILE*file);
boolcheck_circle();
vector<Record>get_all_records(charhead_letter, chartail_letter, charhead_not_letter, boolis_circle);
vector<Record>get_main_records(charhead_letter, charhead_not_letter, boolis_circle);
vector<Record>get_first_letter_main_records(inthead, boolis_circle);
vector<Record>get_all_child_records(vector<Record>main_records, chartail_letter);
vector<Record>get_child_records(Recordrecord, chartail_letter);
vector<string>get_chain_by_record(Recordrecord);
stringget_one_max_length_letter_chain_by_record(Recordrecord, boolis_circle);
voidprint_records(vector<Record>records);
stringprint_chains(vector<string>chains);
stringprint_max_chain(stringchain);Interface Design
在接口设计中,做到单一职责原则和接口隔离原则。每个接口仅完成了希望完成的任务,而没有进行额外的性能消耗,功能单一,不可再分。
Loose Coupling
在step2的接口设计中,将功能分为输入、计算、输出三个模块。三个模块间不存在数据直接交互(如需交互需要上层函数在三个模块间分别传递words和result变量),可以分别独自调用;并且各模块内部实现了众多功能(甚至输入模块完全可以用于其他项目的输入),实现了高内聚低耦合的目标。
四、接口设计与实现
模块间接口设计
在step2中,考虑到进一步功能切分,将功能分为输入、计算与输出三个模块。
输入模块模块(在lib.dll中)考虑到了输入的多样性,如CLI读入、文件读入、字符串读入、数组读入等。需要注意的是,为松耦合,模块之间不存在调用关系,即调用输入模块接口的主函数需自行存储处理所需参数(如head),但为便于CLI读入,输入接口提供处理CLI的接口。
intget_words_from_file_path(char*words[], char*file_path);
intget_words_from_file_path(char*words[], stringfile_path);
// 需要自行分配内存
intget_words_from_cmd(char*words[], intargc, char*argv[], int*type_p, char*head_p, char*tail_p, char*reject_p, bool*enable_loop);
intget_words_from_char(char*words[], char*words_char);
intget_words_from_string(char*words[], stringwords_string);
intget_words_from_string_array(char*words[], stringword_string[], intword_string_num);计算模块(在core.dll中)主要用于完成计算数据,提供以下五个接口。分别用于求解所有链、求解所有满足条件的最长单词链、求解所有满足条件的最长字母链、求解一条满足条件的最长单词链、求解一条满足条件的最长字母链。
intgen_chains_all(char*words[], intlen, char*result[]);
intgen_chains_word(char*words[], intlen, char*result[], charhead, chartail, charreject, boolenable_loop);
intgen_chains_char(char*words[], intlen, char*result[], charhead, chartail, charreject, boolenable_loop);
intgen_chain_word(char*words[], intlen, char*result[], charhead, chartail, charreject, boolenable_loop);
intgen_chain_char(char*words[], intlen, char*result[], charhead, chartail, charreject, boolenable_loop);
输出模块(在lib.dll中)提供了标准输出(cout)以及输出到文件两种方式。并且默认输出文件夹为\solution.txt。
voidstd_out_result(char*result[], intlen);
voidfile_write_result(char*result[], intlen, stringfile_path="solution.txt");另外,三个模块中均可能出现各种异常,模块与异常间的接口便是对异常类的调用。以FileContentException异常为例,异常构造函数读入造成异常的信息c,并为保证信息隐藏将其作为私有变量存储。模块通过公共函数string print_exception();获取异常提示信息。异常类仅存储信息,并不直接进行异常信息输出。为便于提示,在各模块中以cout << e.print_exception() << endl;的方式输出异常信息,但完全可以支持将异常信息输出到文件中等行为。
classFileContentException : publiclogic_error {
public:
explicitFileContentException(stringc): logic_error("file contains unexpected character: ") {
this->c=std::move(c);
}
stringprint_exception() {
strings=this->what();
s+=c;
returns;
}
private:
stringc;
};计算模块设计
核心思想
可以发现,对于一条链,我们只关注其每个单词首位两个字母,而中间的字母仅起到增加单词长度的作用。我们进行如下定义记录Record:一个元素为字母,长度至少为3的链表,如a->b->c。很明显,一个Record代表了很多条链,这取决于words的分布,如a->b->d可以代表链aab->bbd,也可以代表链acdb->bdafd。但是我们完全可以根据一个Record,得到最合适的链。
另外,我们称所有以head_letter为首元素的所有最长Record(允许loop)的集合为head_letter的主Record集。主Record集中的每一个Record称为以head_letter为首元素的主Record。很明显,主Record代表能从head_letter沿着words能走到的(各种)最远路径。对于每条主Record,可以递归地求到以head_letter为首元素的子Record集(如a->b->c->d的子Record集为a->b->c, a->b->c->d)。主Record集中所有Record的子Record集的集合,就是以head_letter为首元素的所有Record。
Record是算法的核心。它可以很好地简化算法,并降低复杂度。
因此,对于所有功能,一般的,我们首先将words转化成图中的有向边。对于找到合适的链,首先转化为找到合适的Record,再根据Record找到合适的链。
这样的优点是,首先对问题起到了很好地抽象作用,便于思考,也有利于函数的单一功能实现。另外,对于求所有链的问题,得到主Record集就可以递归得到所有链;对于求最长链问题,由于最长Record一定大于子Record,完全可以先求最长主Record,再只判断主Record对应链长度得到最长链(仅对于不限制尾元素)。
数据结构
Vertex
用于图的拓扑排序,判断是否成环。
typedefstructvertex {
set<int>in_degrees;
set<int>out_degrees;
} Vertex;
Vertexvertexes[26];Edge
structcmp_words {
booloperator() (stringword1, stringword2) {
returnword1.length() <word2.length();
}
};
structedge {
vector<string>words;
priority_queue<string, vector<string>, cmp_words>words_priority_queue;
intnum;
boolis_free;
};
typedefstructedgeEdge;
Edgegraph[26][26];需要注意的是,Edge有一个成员变量为优先级队列,便于在从Record到chain时获取最长word。
Record
虽然Record仅有一个成员变量,但作为算法实现核心,封装起来便于使用。
structrecord {
vector<int>nodes;
};
typedefstructrecordRecord;函数功能
intgen_chains_all(char*words[], intlen, char*result[]);
intgen_chains_word(char*words[], intlen, char*result[], charhead, chartail, charreject, boolenable_loop);
intgen_chains_char(char*words[], intlen, char*result[], charhead, chartail, charreject, boolenable_loop);
intgen_chain_word(char*words[], intlen, char*result[], charhead, chartail, charreject, boolenable_loop);
intgen_chain_char(char*words[], intlen, char*result[], charhead, chartail, charreject, boolenable_loop);上面五个接口是计算模块与外界交互的接口,但在模块内部,其主要起到异常处理作用,在模块内部均调度int solution(char* words[], int len, char* result[], int type, char head_letter, char tail_letter, char head_not_letter, bool is_circle=true, bool is_all_chains=false)函数。该函数进行图初始化、loop检测、异常判断、调用子函数等功能。可以说该函数的作用是初始化与任务分发,而非具体实现算法。
初始化与Circle判断
void init_graph(char* words[], int len):读入words,将word转化为图,并存入数据结构中。注意的是,单词自环并不能作为loop,如eye
bool check_circle():根据图的拓扑排序算法判断是否成环。以及需要特判单独字母自环,如aba, abba成环
Record
vector<Record> get_first_letter_main_records(int head, bool is_circle):根据首元素得到其所有主Record集
vector<Record> get_main_records(char head_letter, char head_not_letter, bool is_circle):调用get_first_letter_main_records函数,并同时根据首元素可以、禁止字母进行筛选,获取所有主Record集
vector<Record> get_child_records(Record record, char tail_letter):根据Record得到子Record集
vector<Record> get_all_child_records(vector<Record> main_records, char tail_letter):调用get_child_records,获得主Record集的子Record集集合
vector<Record> get_all_records(char head_letter, char tail_letter, char head_not_letter, bool is_circle):调用get_all_child_records和get_main_records,获得所有Record,并对尾元素进行筛选
因此如果要判断尾元素,不论是否是最长链,必须要进行get_all_records
内在逻辑是,有可能主Record(不满足条件)的子Record满足尾元素条件,该子Record是最长链
如极端情况a->b->c->d,尾元素要求为c,那么最长Record为a->b->c
而对于不作尾元素要求的最长链,就可以进行优化,仅获取主Record
链获取与存储
vector<string> get_chain_by_record(Record record):获得所有Record满足的链
int print_chains(char* result[], vector<string> chains):将链集合存储到result中
int print_chain(char* result[], string chain):将满足的一条链存储到result中
所有链
int get_all_chain(char* result[], char head_letter, char tail_letter, char head_not_letter, bool is_circle):实现获取所有链的算法。先调用all_records获得所有Record,再调用get_chain_by_record和print_chains将记录转变为链并存储输出
最长所有链
int get_max_length_chains(char* result[], bool is_word, char head_letter, char tail_letter, char head_not_letter, bool is_circle):对满足条件的Record,遍历判断。区别在于,最长单词链可以先判断出最长Record再获取链,而最长字母链则需要先获取链再判断。
子函数:
vector<string> get_max_length_word_chains_by_record(Record record):根据Record获取所有链
vector<string> get_max_length_letter_chains_by_record(Record record):根据Record获取最长字母,本质上是对get_max_length_word_chains_by_record所得所有链进行进一步筛选
最长任意链
int get_max_length_chain(char* result[], bool is_word, char head_letter, char tail_letter, char head_not_letter, bool is_circle):与最长所有链思路一致,但仅需要存储一条最长链
子函数:
string get_one_max_length_letter_chain_by_record(Record record, bool is_circle):根据Record获取一条最长链。由于相同Record下,最长字母链是最长单词链的特例,所以我们仅得到最长单词链即可
五、编译无警告图
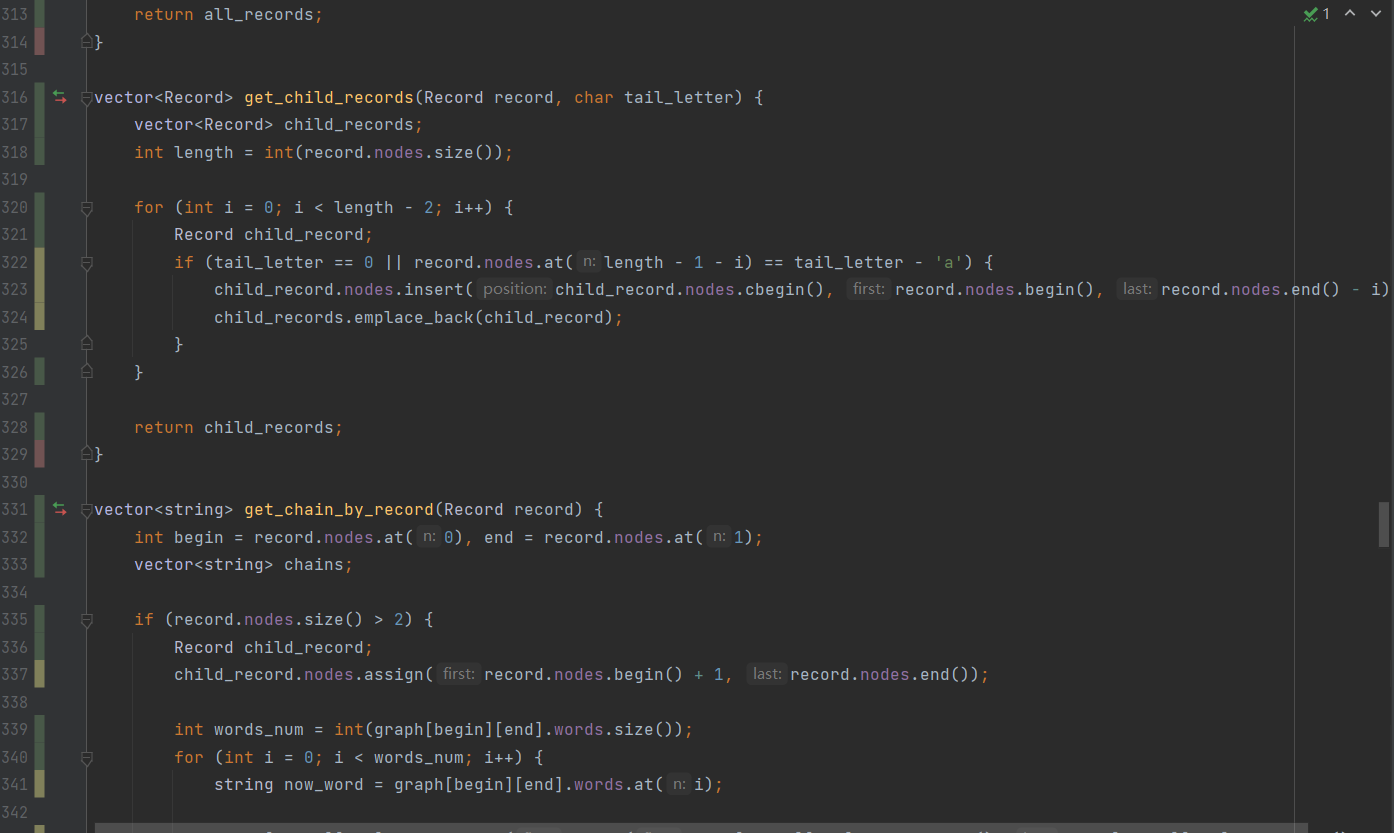

[独立]六、计算模块UML图
七、性能改进
时间:100min
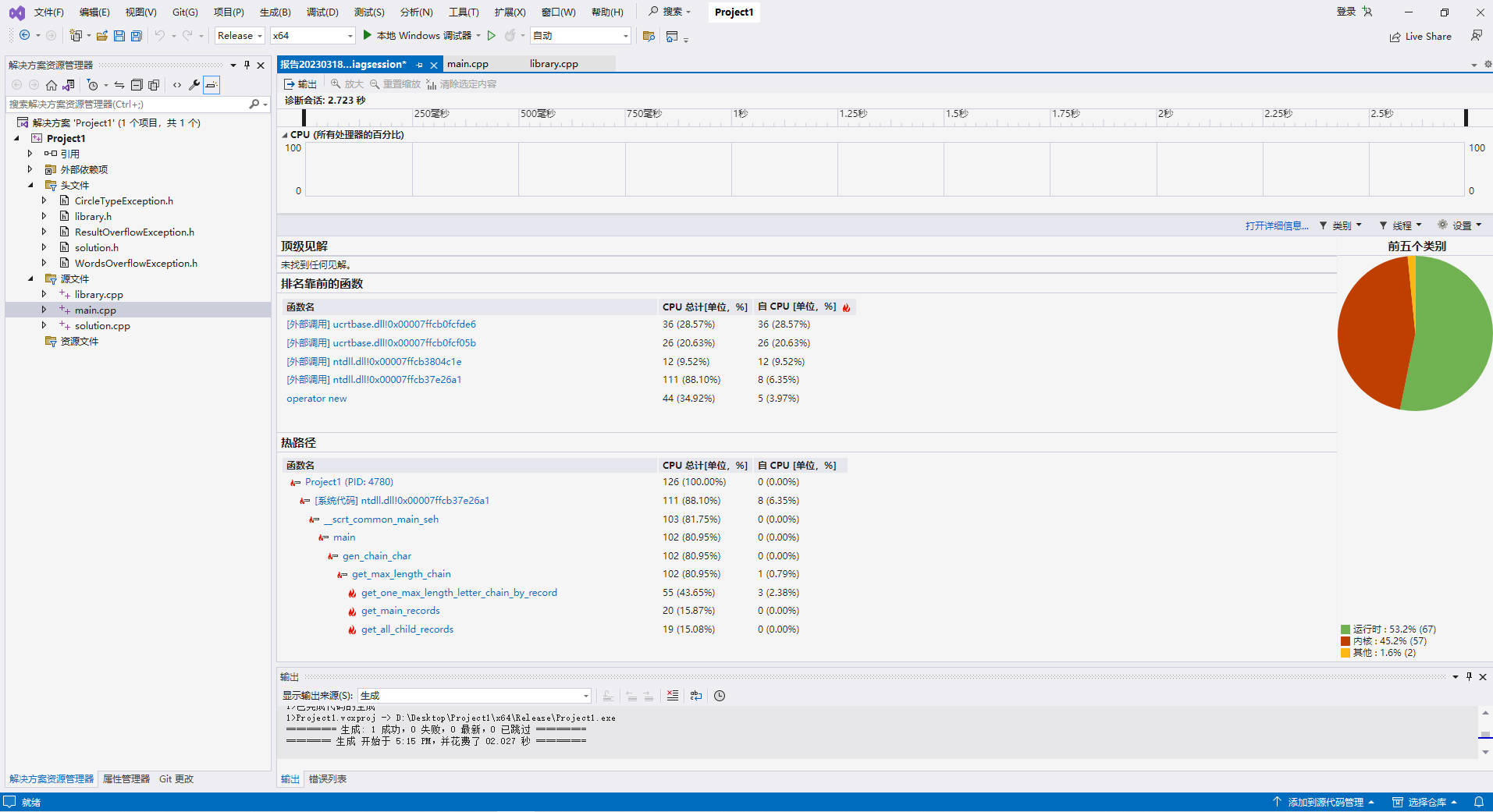
对于本项目算法,各函数的功能都和Record的数量相关。如一部分函数的功能是求解Record,另一部分是根据Record得到一定条件的chain。根据上图中,get_one_max_length_letter_chain_by_record函数(即根据Record找到最长字母链)占用资源最多。
根据调查,如果输出对tail不做要求,那么就不需要传入所有Record,而是只需要传入main Records。因此通过对tail==0条件进行特判,将该情况传入Record更改为传入main Record。结果如下图。可以说性能得到了极大的增强。这是因为一条main Record可以递归地生成许多sub Record,并且每条sub Record又对应许多chains。
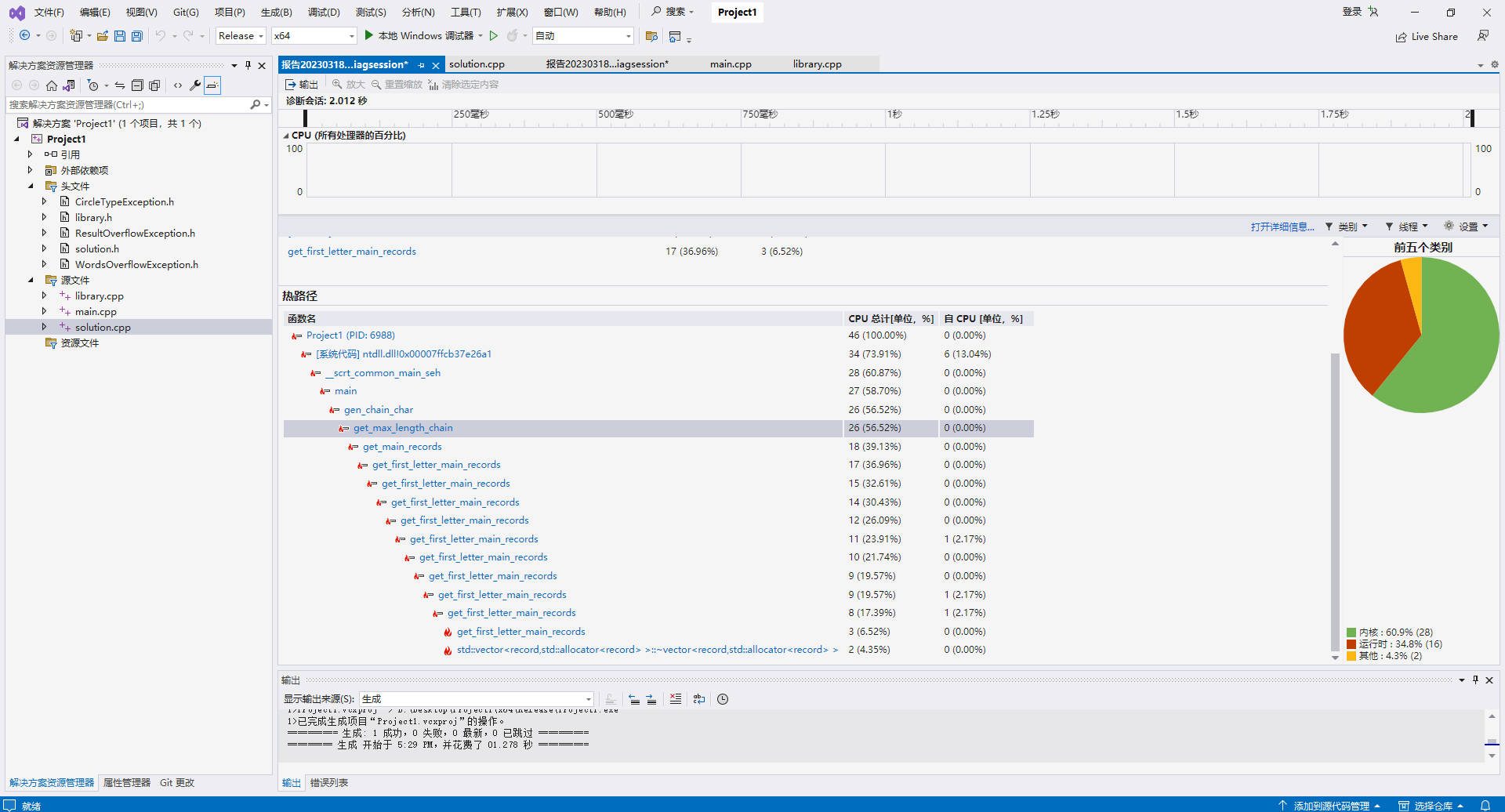
[独立]八、Contract编程
Design by contract:规定软件设计者应该为软件组件定义形式化的、精确的和可验证的接口规范,它为抽象数据类型扩展了前置条件、后置条件和不变量条件。
优点:
通过对接口进行前置条件、后置条件、不变量条件的预先设计,更加精细化接口,避免了不同人员可能对接口产生的误解
单元测试时,前置条件、后置条件、不变量条件正是测试的边界。前置条件不满足可以测试其鲁棒性或错误处理,后置条件与不变量条件则是必须要满足的
在考虑接口的前置条件时,可以同时做好异常的设计
出现bug时,分工明确便于差错
缺点:
接口设计过于精细的话,容易考虑过深,造成时间浪费,降低效率
过于细致的规范可能会限制算法的优化
融入项目:
对于项目整体,并没有根据DbC方法进行项目的开展。但是在计算模块内部,对于各个函数的功能约束近似应用了该方法,如对于每一个函数,我们都会作出如下规范
确保输入满足的条件(例:init_graph函数的输入head_letter仅可能为0或字母)
函数内部应处理的异常(例:init_graph函数处理WordsOverflowException,CircleTypeException)
输出应确保满足的条件(例:init_graph函数完成graph的构建)
保持的不变量(例:get_max_length_chains函数应保证运行前后graph不改变,但允许中途改变)
九、计算模块部分单元测试展示
计算模块代码展示
#include <iostream>
#include "gtest/gtest.h"
intgen_chains_all(char*words[], intlen, char*result[]);
intread_file(char*words[], std::stringfile_path);
intgen_chain_word(char*words[], intlen, char*result[], charhead, chartail, charreject, boolenable_loop);
intgen_chain_char(char*words[], intlen, char*result[], charhead, chartail, charreject, boolenable_loop);
intgen_chains_word(char*words[], intlen, char*result[], charhead, chartail, charreject, boolenable_loop);
intgen_chains_char(char*words[], intlen, char*result[], charhead, chartail, charreject, boolenable_loop);
char*words1[100];
char*words2[200];
char*words3[100];
char*words4[100];
char*words5[100];
char*words6[100];
char*words7[100];
char*words8[100];
char*words9[100];
char*words10[100];
TEST(read_file, r_f1) {
EXPECT_EQ(20, read_file(words1, "word1.txt"));
}
TEST(read_file, r_f2) {
EXPECT_EQ(100, read_file(words2, "word2.txt"));
}
TEST(gen_chains_all, gca1) {
char*result[100];
read_file(words3, "word3.txt");
EXPECT_EQ(48, gen_chains_all(words3, 10, result));
}
TEST(gen_chains_all, gca2) {
char*result[2000];
read_file(words4, "word4.txt");
EXPECT_EQ(1837, gen_chains_all(words4, 10, result));
}
TEST(gen_chain_word, gcw1) {
char*result[100];
read_file(words5, "word5.txt");
EXPECT_EQ(10, gen_chain_word(words5, 10, result, 'n', 'h', 'o', false));
}
TEST(gen_chains_word, gcw2) {
char*result[100];
read_file(words6, "word6.txt");
EXPECT_EQ(8, gen_chain_word(words6, 10, result, 's', 'x', 't', true));
}
TEST(gen_chains_word, gcw3) {
char*result[100];
read_file(words7, "word7.txt");
EXPECT_EQ(10, gen_chain_word(words7, 10, result, 'z', 'd', 0, false));
}
TEST(gen_chain_char, gcc1) {
char*result[100];
read_file(words8, "word8.txt");
EXPECT_EQ(20, gen_chain_char(words8, 20, result, 'z', 'x', 'h', true));
}
TEST(gen_chains_char, gcc2) {
char*result[100];
read_file(words9, "word9.txt");
EXPECT_EQ(20, gen_chain_char(words9, 20, result, 'n', 'z', 0, false));
}
TEST(gen_chains_char, gcc3) {
char*result[100];
read_file(words10, "word10.txt");
EXPECT_EQ(51, gen_chain_char(words10, 20, result, 'z', 'u', 'h', true));
}
intmain() {
::testing::InitGoogleTest();
returnRUN_ALL_TESTS();
}测试的函数以及测试数据构造
单元测试主要测试了以下四个函数
intread_file(char*words[], std::stringfile_path);
intgen_chains_all(char*words[], intlen, char*result[]);
intgen_chain_word(char*words[], intlen, char*result[], charhead, chartail, charreject, boolenable_loop);
intgen_chain_char(char*words[], intlen, char*result[], charhead, chartail, charreject, boolenable_loop);
intgen_chains_word(char*words[], intlen, char*result[], charhead, chartail, charreject, boolenable_loop);
intgen_chains_char(char*words[], intlen, char*result[], charhead, chartail, charreject, boolenable_loop);其中后三个函数为计算模块的接口函数,第一个函数只是为了方便从文件中直接读取单词到words中。
gen_chains_all
这一函数找出所有符合要求的单词链(在此可以看作-n)。由于这一环节无需考虑环的问题,因此随机生成一定数量的单词,并保证不构成单词环即可,如以下示例所示:
# 生成单词的代码
fromrandomimportrandint
forcntinrange(10):
filename = "word"+str(cnt+1) +".txt"
file = open(filename, "w")
c = chr(randint(ord('a'), ord('z')))
foriinrange(20):
word = c
m = randint(3, 12)
forjinrange(m):
word += chr(randint(ord('a'), ord('z')))
c = chr(randint(ord('a'), ord('z')))
whilec == word[m]:
c = chr(randint(ord('a'), ord('z')))
word += c
file.write(word+"\n")
file.close()
// 生成的单词
aqhomctfqx
xgsmwri
iqpzjdu
ukroumfyre
ewjwzrx
xvrfmatyf
fnbntqxhf
fhldsiryuufj
jegvwlry
yknvmmgpxbmf
fwclwp
pzbdps
skdbafnbadi
iiihoawdgshs
suxwxvqesqeoz
zibobraopn
nuafwzvgotu
ubhrkawvbvp
ptbyidkdutztlv
vmxauzm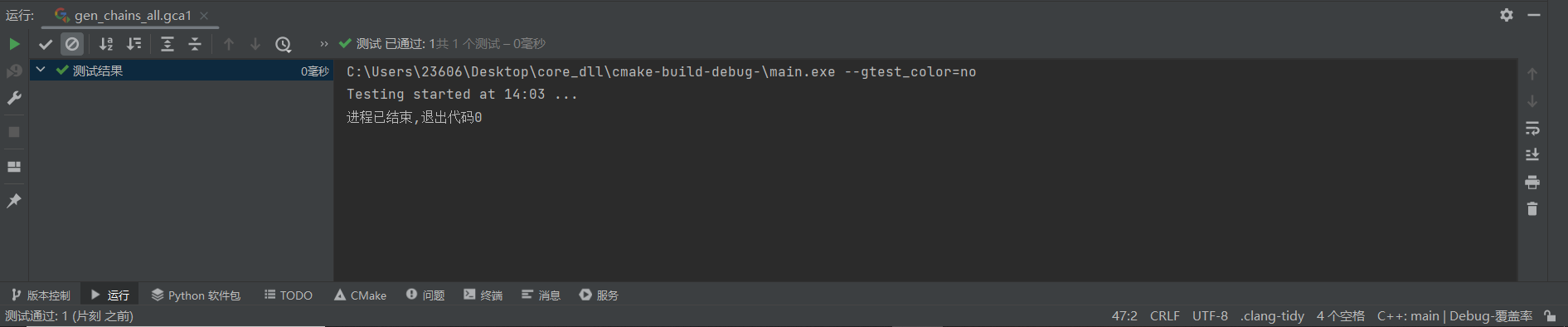
gen_chain_word以及gen_chains_word
gen_chain_word以及gen_chains_word返回全部(或者单个最长单词链)。由于这里增加了首字符,尾字符,不能出现的首字符以及是否允许成环的限制,因此在测试时,需要同时覆盖这四种情形,以及他们的组合。
// 仅为举例
gen_chain_word(words, 10, result, 0, 0, 0, true);
gen_chain_word(words, 10, result, 0, 0, 0, false);
gen_chain_word(words, 10, result, 'a', 0, 0, true);
gen_chain_word(words, 10, result, 0, 'a', 0, true);
gen_chain_word(words, 10, result, 0, 0, 'a', true);特别的,当enable_loop == false时,与上述构造数据方法类似,仍然不能出现环(否则需要产生异常)。而enable_loop == true时,可以产生环,因此在生成单词,可以删除对单词环的限制。
gen_chain_char以及gen_chains_char
与上述类似
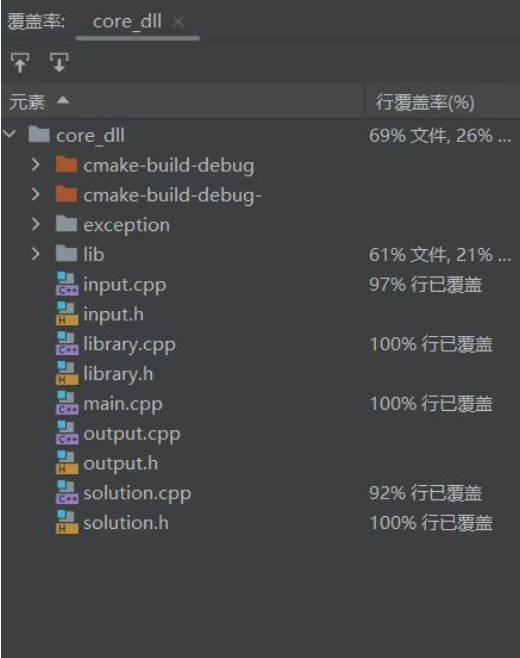
测试覆盖率截图
其中lib为外部导入的文件夹(类似库文件,可以不考虑)。其余文件的测试覆盖率均达到了90%以上。
十、异常处理说明
输入模块异常
异常类 | 异常 | 输入参数 | print_exception | 说明 |
IllegalParameterException | 出现非法参数 | ---- | illegal parameter occurred! | |
RequiredParameterMissingException | 缺少必要参数 | ----/-h | missing required parameter!/missing required parameter after -h! | 缺少-n, -w, -c参数,或-h, -t, -j后缺少字母 |
ConflictParameterException | 参数冲突 | ---- | parameters not compatible! | 多次出现-n, -w, -c |
DuplicatedParameterException | 同一参数出现多次 | ---- | multiple occurrences of the same parameter! | |
ParameterTypeException | 参数类型错误 | -h | the parameter after -h should be a letter but not a string! | -h, -t, -j后的参数并非字母 |
FileNonExistException | 文件不存在 | file_name | file_name is non-existent! | |
FileNonReadException | 文件不可读 | file_name | file_name is not readable! | 在文件存在的基础上判断 |
FileEmptyException | 文件为空 | ---- | words file is empty! | |
FileContentException | 文件内容错误 | c | contains unexpected character: c | 其中c为非法字符(字母以外字符) |
OneLetterWordException | 单词仅有一个字母 | word | have one-letter word: word | |
DuplicatedWordException | 出现重复单词 | word | have duplicated word: word |
计算模块异常
异常类 | 异常 | 输入参数 | print_exception | 说明 |
WordsOverflowException | 输入单词数过大 | is_circle | words more than is_circle ? 100 : 10000 ! | 环最大为100,否则为10000 |
CircleTypeException | 输入enable_loop与实际不匹配 | is_circle | enable_loop is !is_circle but should be is_circle! | |
ResultOverflowException | 输出链(单词)数过大 | ---- | result chains more than 20000! | 会返回输出数,但是否返回正确result并不保证 |
输出模块异常
异常类 | 异常 | 输入参数 | print_exception | 说明 |
NonMatchedChainException | 输出链为空 | ---- | not have matched chain! | 我们并未在计算模块关注是否存在符合条件的链,而是在输出模块判断 |
FileNonWriteException | 文件不可写 | file_name | file_name is not writable! | 如果不存在文件,则会创建文件;只有存在文件且不可写才会触发异常 |
计算模块单元测试样例
WordsOverflowException
gcgvvmjcrffke
ewqhnoahw
wkwmok
kjhsz
zpesxg
gcriiytkswted
daxmgeydgsrrv
vudmndopefpkiy
yjwgslidvts
sicjwnvqevero
otajk
...
...
bbjbstoojtju
ufkxtq
// 共20000个
输出:words more than 100!CircleTypeException
gen_chain_word(words, 2, result, 0, 0, 0, false)
输出:enable_loop is !is_circle but should be is_circle!ResultOverflowException
输入:类似WordsOverflowException
输出:result chains more than 20000!十三、结对过程
2023年3月7日,在宿舍进行项目的计划、step1的开发,总计6h。
2023年3月12日,三号楼进行step1的基本功能测试、step2的核心模块封装,总计4h。

2023年3月15日,图书馆咖啡厅进行step2的单元、回归测试,修改bug,step2的核心模块封装,step3异常实现,总计7h。
2023年3月17日,主楼进行step2的测试,修改bug,step2的输入输出模块封装,异常测试,总计7h。

2023年3月18日,主楼修改bug,博客写作,总计5h。
[独立]十四、结对编程优缺点
结对编程
优点
在代码架构、接口设计阶段,双方可以很明确不同模块的功能,减少双方理解的模糊地带;同时对于算法的设计时,可以集两家之长
在代码开发时,结对编程可以在开发过程中进行bug排查,减少代码中的错误和缺陷
开发中,双方可以相互交流和学习,两个人掌握技术的覆盖面更大,减少了学习新技术的成本
结对编程让双方共同保证项目的开发,互相监督,确保按时完成任务
缺点
两个人一起工作,如果不能很好地沟通于合作,势必造成人力、时间的浪费,甚至效率不如分别进行
双方一同工作,可能会导致编程时间拉长,造成精神上的压力
本人
优点
能够对项目进行很好的架构,设计好接口与模块功能
熟练掌握数据结构和算法,能够将函数功能很好实现
较为擅长于他人交流
缺点
没有使用过C++
不善于测试,没有使用过VS相关插件
队友
优点
代码风格规范,编程功底很好,能够很好地实现函数功能
熟悉C++语法
善于合作,可以很好地交流,愿意主动承担工作
缺点
对附加模块(如GUI)不太有热情,缺乏对完美的追求
[独立]十五、PSP表格记录实际时间
PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
Planning | 计划 | 60 | 40 |
· Estimate | · 估计这个任务需要多少时间 | 60 | 40 |
Development | 开发 | 1390 | 1720 |
· Analysis | · 需求分析 (包括学习新技术) | 40 | 100 |
· Design Spec | · 生成设计文档 | 30 | 30 |
· Design Review | · 设计复审 (和同事审核设计文档) | 30 | 20 |
· Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
· Design | · 具体设计 | 90 | 120 |
· Coding | · 具体编码 | 840 | 900 |
· Code Review | · 代码复审 | 50 | 40 |
· Test | · 测试(自我测试,修改代码,提交修改) | 300 | 500 |
Reporting | 报告 | 180 | 160 |
· Test Report | · 测试报告 | 150 | 120 |
· Size Measurement | · 计算工作量 | 15 | 20 |
· Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 15 | 20 |
合计 | 1630 | 1920 |















 107
107











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









