









系列文章目录
feapder的使用
文章目录
前言
feapder库相比scrapy的易用性较高,并且有相应的爬虫管理平台作为爬虫监控,很多东西都能一键封装好,性能方面与scrapy相比基本没什么区别,可以作为快速爬虫的任务使用。
一、feapder是什么?
feapder是一款上手简单,功能强大的Python爬虫框架。
二、使用步骤
1.安装
环境:
Python 3.6.0+
Works on Linux, Windows, macOS
通用版feapder pip安装:
pip install feapder
2.生成feapder爬虫项目
创建轻量级爬虫airpspider
feapder create -s first_crawl
生成一个文件first_crawl.py
值得注意的是,这里不推荐feapder的原生setting,因为并发量太大以及重试次数太多单爬一个网站会导致IP快速被封,后面笔者发现feapder会默认搜索setting文件,setting文件可到楼底去查找,主要是爬虫开始时限制并发数以及重试次数。
# -*- coding: utf-8 -*-
"""
Created on 2022-06-29 10:52:36
---------
@summary:
---------
@author: Administrator
"""
import feapder
class FirstCrawl(feapder.AirSpider):
def start_requests(self):
yield feapder.Request("https://spidertools.cn")
def parse(self, request, response):
# 提取网站title
print(response.xpath("//title/text()").extract_first())
# 提取网站描述
print(response.xpath("//meta[@name='description']/@content").extract_first())
print("网站地址: ", response.url)
if __name__ == "__main__":
FirstCrawl().start()
简单描述一下该流程。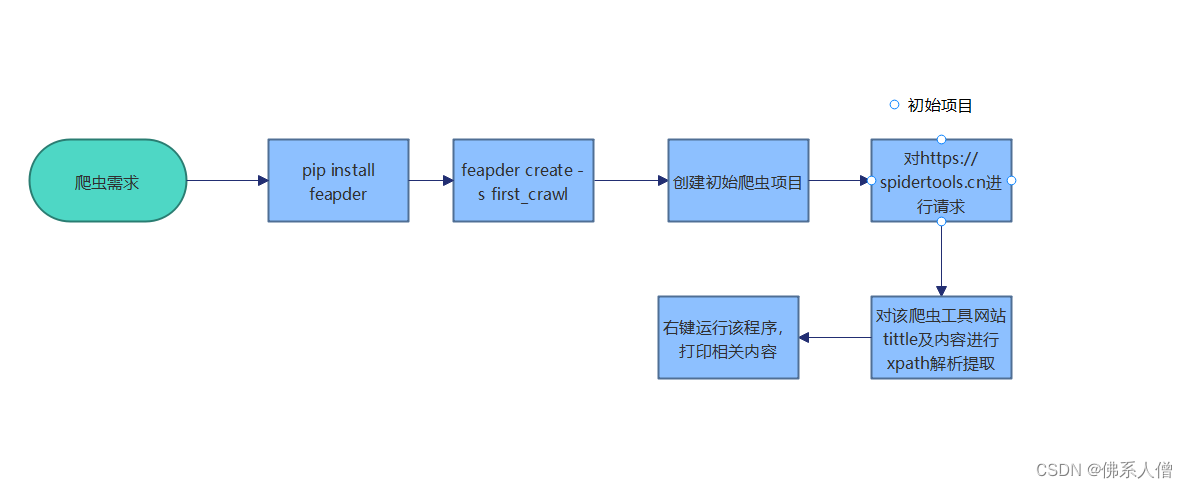
呈现结果:
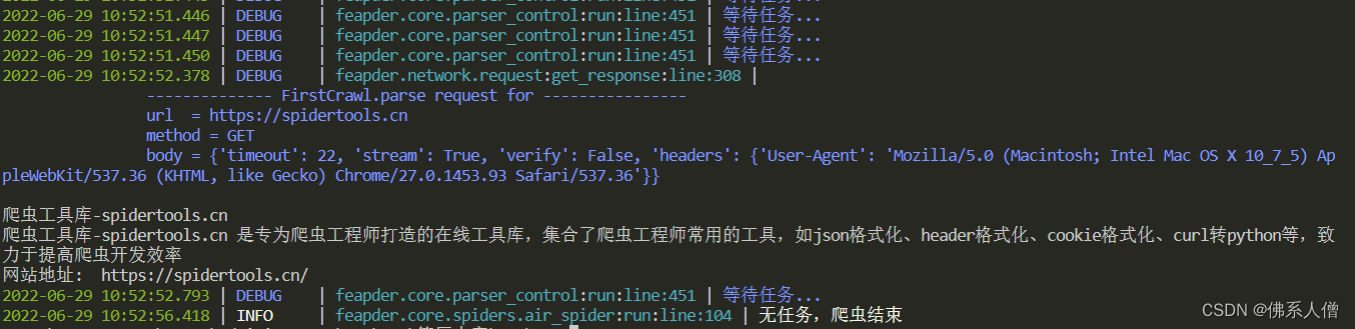
注意的是:
该框架有随机ua,不需要自己写,如果遇到需要随机指纹,也可以直接写中间件,具体是添加指纹类以及中间件方法download_midware
setting代码:
import os
# MYSQL
MYSQL_IP = ""
MYSQL_PORT = 3306
MYSQL_DB = ""
MYSQL_USER_NAME = ""
MYSQL_USER_PASS = ""
# REDIS
# IP:PORT
REDISDB_IP_PORTS = "xxx:6379"
REDISDB_USER_PASS = ""
# 默认 0 到 15 共16个数据库
REDISDB_DB = 0
# 数据入库的pipeline,可自定义,默认MysqlPipeline
ITEM_PIPELINES = ["feapder.pipelines.mysql_pipeline.MysqlPipeline"]
# 爬虫相关
# COLLECTOR
COLLECTOR_SLEEP_TIME = 1 # 从任务队列中获取任务到内存队列的间隔
COLLECTOR_TASK_COUNT = 100 # 每次获取任务数量
# SPIDER
SPIDER_THREAD_COUNT = 10 # 爬虫并发数
SPIDER_SLEEP_TIME = 0 # 下载时间间隔 单位秒。 支持随机 如 SPIDER_SLEEP_TIME = [2, 5] 则间隔为 2~5秒之间的随机数,包含2和5
SPIDER_MAX_RETRY_TIMES = 1 # 每个请求最大重试次数
# 浏览器渲染下载
WEBDRIVER = dict(
pool_size=2, # 浏览器的数量
load_images=False, # 是否加载图片
user_agent=None, # 字符串 或 无参函数,返回值为user_agent
proxy=None, # xxx.xxx.xxx.xxx:xxxx 或 无参函数,返回值为代理地址
headless=False, # 是否为无头浏览器
driver_type="CHROME", # CHROME 或 PHANTOMJS,
timeout=30, # 请求超时时间
window_size=(1024, 800), # 窗口大小
executable_path=None, # 浏览器路径,默认为默认路径
render_time=0, # 渲染时长,即打开网页等待指定时间后再获取源码
)
# 重新尝试失败的requests 当requests重试次数超过允许的最大重试次数算失败
RETRY_FAILED_REQUESTS = False
# request 超时时间,超过这个时间重新做(不是网络请求的超时时间)单位秒
REQUEST_LOST_TIMEOUT = 600 # 10分钟
# 保存失败的request
SAVE_FAILED_REQUEST = True
# 下载缓存 利用redis缓存,由于内存小,所以仅供测试时使用
RESPONSE_CACHED_ENABLE = False # 是否启用下载缓存 成本高的数据或容易变需求的数据,建议设置为True
RESPONSE_CACHED_EXPIRE_TIME = 3600 # 缓存时间 秒
RESPONSE_CACHED_USED = False # 是否使用缓存 补采数据时可设置为True
WARNING_FAILED_COUNT = 1000 # 任务失败数 超过WARNING_FAILED_COUNT则报警
# 爬虫是否常驻
KEEP_ALIVE = False
# 设置代理
PROXY_EXTRACT_API = None # 代理提取API ,返回的代理分割符为\r\n
PROXY_ENABLE = True
# 随机headers
RANDOM_HEADERS = True
# requests 使用session
USE_SESSION = False
# 去重
ITEM_FILTER_ENABLE = False # item 去重
REQUEST_FILTER_ENABLE = False # request 去重
# 报警 支持钉钉及邮件,二选一即可
# 钉钉报警
DINGDING_WARNING_URL = "" # 钉钉机器人api
DINGDING_WARNING_PHONE = "" # 报警人 支持列表,可指定多个
# 邮件报警
EMAIL_SENDER = "" # 发件人
EMAIL_PASSWORD = "" # 授权码
EMAIL_RECEIVER = "" # 收件人 支持列表,可指定多个
# 时间间隔
WARNING_INTERVAL = 3600 # 相同报警的报警时间间隔,防止刷屏; 0表示不去重
WARNING_LEVEL = "DEBUG" # 报警级别, DEBUG / ERROR
LOG_NAME = os.path.basename(os.getcwd())
LOG_PATH = "log/%s.log" % LOG_NAME # log存储路径
LOG_LEVEL = "DEBUG"
LOG_COLOR = True # 是否带有颜色
LOG_IS_WRITE_TO_CONSOLE = True # 是否打印到控制台
LOG_IS_WRITE_TO_FILE = False # 是否写文件
LOG_MODE = "w" # 写文件的模式
LOG_MAX_BYTES = 10 * 1024 * 1024 # 每个日志文件的最大字节数
LOG_BACKUP_COUNT = 20 # 日志文件保留数量
LOG_ENCODING = "utf8" # 日志文件编码
OTHERS_LOG_LEVAL = "ERROR" # 第三方库的log等级
后面笔者尝试对搜狗进行了爬虫,并对每个搜索结果进行请求并根据索引值起名保存到相应目录
具体可见
# -*- coding: utf-8 -*-
"""
Created on 2022-07-03 09:21:20
---------
@summary:
---------
@author: Administrator
"""
import feapder
class AirSougu(feapder.AirSpider):
def start_requests(self):
yield feapder.Request("https://www.sogou.com/web?query=feapder")
def parse(self, request, response):
# 提取网站title
urls = response.xpath('//div[3]/div/div/h3/a/@href').extract()
# print(url)
for url in urls:
print(url)
# print the index of url
index_url = urls.index(url)
print(index_url)
yield feapder.Request(url, callback=self.parse_details, index_url=index_url)
def parse_details(self,request,response):
#根据url请求详情页面
content = response.text
print(content)
index_url = request.index_url
print(index_url,"索引是")
# save to file
with open(f'{index_url}.html', 'w', encoding='utf-8') as f:
f.write(content)
# time.sleep(1)
if __name__ == "__main__":
AirSougu().start()
总结
可以具体看看框架架构图加深下理解。
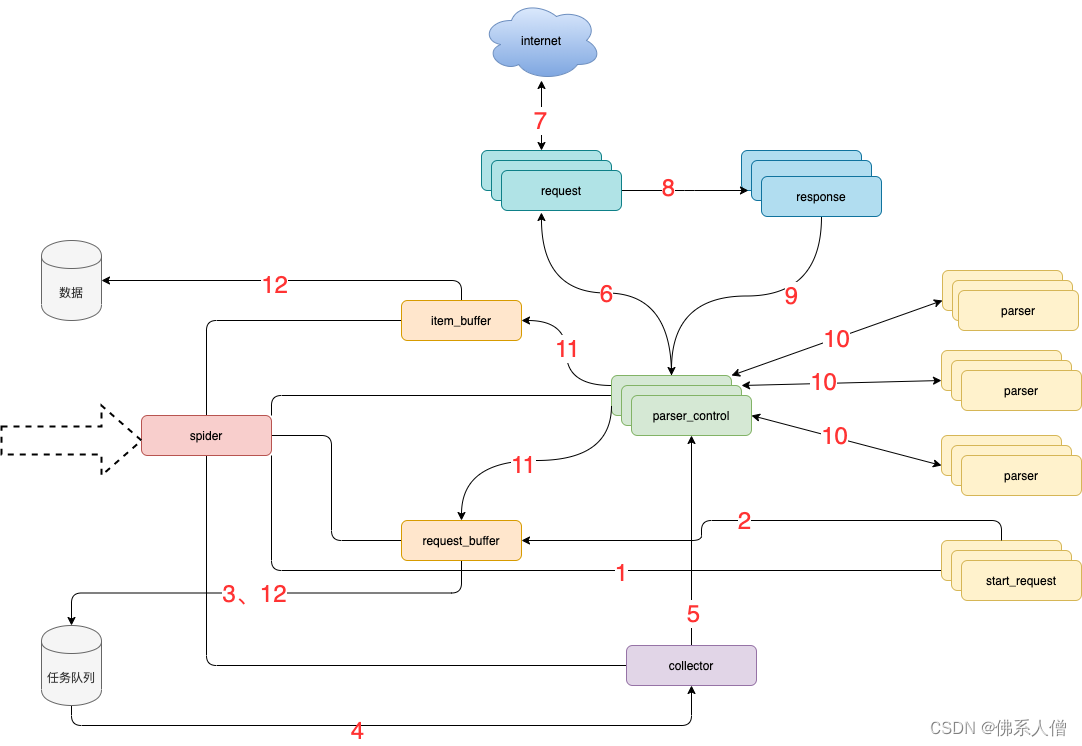
模块说明:
spider 框架调度核心
parser_control 模版控制器,负责调度parser
collector 任务收集器,负责从任务队里中批量取任务到内存,以减少爬虫对任务队列数据库的访问频率及并发量
parser 数据解析器
start_request 初始任务下发函数
item_buffer 数据缓冲队列,批量将数据存储到数据库中
request_buffer 请求任务缓冲队列,批量将请求任务存储到任务队列中
request 数据下载器,封装了requests,用于从互联网上下载数据
response 请求响应,封装了response, 支持xpath、css、re等解析方式,自动处理中文乱码
流程说明:
spider调度start_request生产任务
start_request下发任务到request_buffer中
spider调度request_buffer批量将任务存储到任务队列数据库中
spider调度collector从任务队列中批量获取任务到内存队列
spider调度parser_control从collector的内存队列中获取任务
parser_control调度request请求数据
request请求与下载数据
request将下载后的数据给response,进一步封装
将封装好的response返回给parser_control(图示为多个parser_control,表示多线程)
parser_control调度对应的parser,解析返回的response(图示多组parser表示不同的网站解析器)
parser_control将parser解析到的数据item及新产生的request分发到item_buffer与request_buffer
spider调度item_buffer与request_buffer将数据批量入库















 968
968











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









