







引言
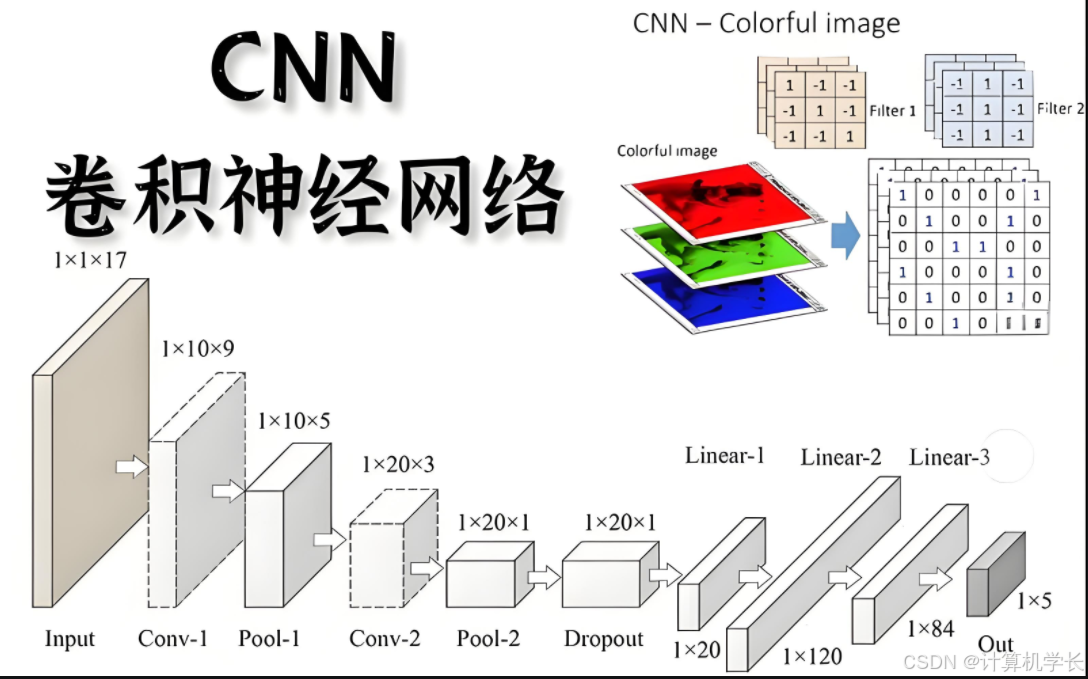
在计算机视觉这片充满无限可能的领域中,卷积神经网络(Convolutional Neural Network,简称 CNN)宛如一颗璀璨的明星,散发着独特的光芒。CNN,作为深度学习家族中的重要成员,是一种专门为处理具有网格结构数据(如图像、音频)而设计的强大模型 。它通过巧妙的卷积操作,能够自动提取数据中的关键特征,仿佛拥有一双敏锐的 “眼睛”,精准地洞察图像中的奥秘。
从最初的 LeNet-5 用于手写数字识别,到 AlexNet 在 ImageNet 竞赛中以远超传统方法的准确率夺冠,CNN 的发展历程充满了创新与突破。它不断推动着计算机视觉技术的边界,在图像分类、目标检测、语义分割等诸多关键任务中取得了令人瞩目的成就,已然成为计算机视觉领域的中流砥柱。接下来,就让我们一同深入探索 CNN 的内部结构,揭开其强大能力背后的神秘面纱。
CNN 核心概念剖析
(一)卷积层:图像特征提取的引擎
卷积层是 CNN 的核心组成部分,其主要职责是从输入图像中提取丰富的特征 。它通过卷积核(也称为滤波器)在输入数据上进行滑动,执行卷积操作,从而获取图像的局部特征。卷积核是一个可学习的小尺寸矩阵,例如常见的 3×3 或 5×5 大小 。
假设我们有一个 5×5 的输入图像矩阵,以及一个 3×3 的卷积核。卷积操作的过程如下:卷积核从输入图像的左上角开始

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 24
24

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











