







1.论文基本信息
题目:Displets:Resolving Stereo Ambiguities using Object Knowledge
来源:Conferenceon Computer Vision and Pattern Recognition (CVPR)
时间:2015.6
作者:Fatma Guney, Andreas Geiger
2.论文摘要
立体技术近年来发展迅速,但仍然存在一些具有挑战性的问题。一个比较显著的问题是,传统的方法不易对具有反射性和无纹理的平面恢复重建。该论文在较大的距离上进行规范,使用图像分类技术确定目标视差位置(displets),采样时使用基于稀疏视差评估的逆图像技术以及语义分割技术。Displets指出,特定类别的物体形状不是随意的,它具有典型有规律的结构。综合上述思路,针对“车”这一类别进行试验,利用CRF框架将目标转化为超像素,在KITTI立体评估中,该方法排名第一。
3.引言
计算机视觉的目标是从摄像机得到的二维图像中提取三维信息,从而重建三维世界模型,主要分为四个步骤,如图所示:

该论文主要针对立体匹配阶段,其基本原理是从两个视点观察同一景物以获取立体图相对,匹配出相应像点,从而计算出视差并获得三维信息。一般情况下,一幅图像中的某一特征基元在另一幅图像中可能会有很多候选匹配对象,可真正同名的结构基元只有一个,因此可能会出现歧义匹配。该论文就是为了解决立体歧义问题。
大部分的双目视觉立体匹配算法集中对文字特征和平滑假设做处理,忽略了语义信息的重要性。该论文集中研究中级阶段的目标识别和语义分割技术,而且注重目前研究较少的三维重建部分。如下图所示,当前算法面临的主要问题是由于目标类的弱纹理性,反射性,半透明性,通过使用目标识别知识,增加可能的目标之间的距离,提高匹配效果。

4.文章基本原理
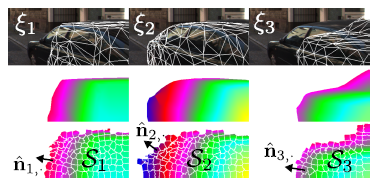
使用SLIC算法将图像分解为一系列的超像素平面,关于displets的说明:
采样三维CAD模型结构(上,中图),通过局部平面和视差图的匹配获取平面参数,其实S代表超像素平面,ni表示平面的法向量。
1)能量函数
立体匹配算法主要是通过建立一个能量代价函数,通过此能量代价函数最小化来估计像素点视差值。立体匹配算法的实质就是一个最优化求解问题,通过建立合理的能量函数,增加一些约束,采用最优化理论的方法进行方程求解。该论文的能量函数如下:

(1)DataTerm(能量函数第一部分)
该数据项指出,左图像和右图像中一致的点在外观上应该相似。由于可能存在很多相似的点,因此用一个半密集的特征区域匹配算法从初始的稀疏视差图得到惩罚偏差如下:
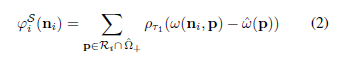
(2)LocalSmoothness(能量函数第二部分)
在能量函数中,鼓励局部平滑度,通过惩罚超像素边缘的不连续性,鼓励具有相似方向的相邻像素。平滑项可分解为:
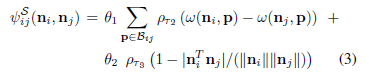
表示超像素i和超像素j之间一系列共享的边界像素,和控制每个式子的重要性。如果相邻的超像素i和j很容易被一个闭塞的边界分开,就降低和的权值。
(3)DispletPotentials(能量函数第三部分)
Displet Potentials标识一个符合特定语义类的可能的几何区域。Displet的一元可能性(unary potential)被定义为,该可能性用来描述图像中形状符合特定目标类的区域被指定给语义类标签
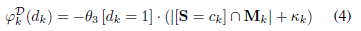
在每个displet和所有超像素之间定义一个可能性,加上一个变量代表平面的法向量,确保displet不会重叠。

2)Rapid Inverse Graphics(快速逆图像)
该部分描述如何使用逆图像从无限大空间的视差图中再次采样,用MCMC画一组符合特定目标类的代表性采样。该过程从原始摄像机中生成视差图,呈现的视差图和输入的视差图进行对比,返回一个表示一致程度的分数。这确保该算法可以抵抗不能程度的光照变化,特别是反射性和半透明的表面。
(1)Semi-ConvexHull(半凸面车身)
从Google上得到的CAD模型中有成千上万的顶点和面,常用的QSlim算法和MATLAB处理不适用,因此提出一个简单方法用来进行网格简化,可以减少CAD模型中的几何类,同时保留车身形状,不影响呈现的深度图。初始化一个凸面车身的网格,在该模型的体积约束下逐渐平滑逼近,该表达被称为Semi-Convex Hull。其最小化了所有网格顶点之间的距离,并且对原始模型上的点进行密集采样。简化算法如下:

(2)Samplingthe Space of Displets(采样Displets空间)
对于一个指定的物体类,c重点研究对得到的半密集视差图中可能的displet空间的二次采样。用MCMC解决逆图像问题,直接从观察模型中采样参数。

该指标对区域O中的每一个像素都进行解释同事避免其他物体的遮挡。使用目标proposals可以避免通过语义类S直接采样。论文提出一个适用于该场景的简单有效的方法去确定图像的proposals。首先,我们将类C中的所有有效的像素用三维表达,然后,我们沿着相机主坐标的x轴和z轴计算核心密度评估(KDE)。由于目标边界经常和KDE的最小值一致,通过将三维的点转化为图像从而确定目标的区域O为每对相邻的最小值。
5.方法效果(实验部分)
1)我们评估所有图像区域(b)和仅仅是反射性区域(a)的匹配错误率。
SGM:Census and Sobelfeatures;
CNN:recently proposedfeatures based on convolutional neural networks.
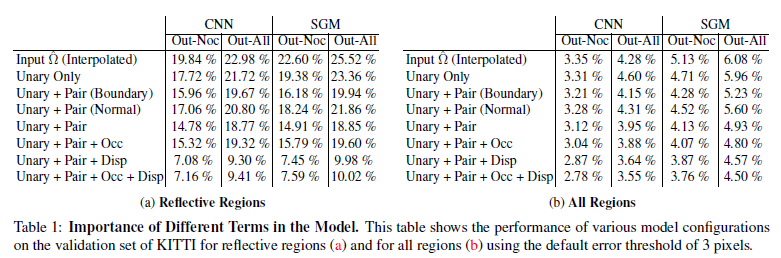
下图表示使用模型结构中的不同项时的错误率;
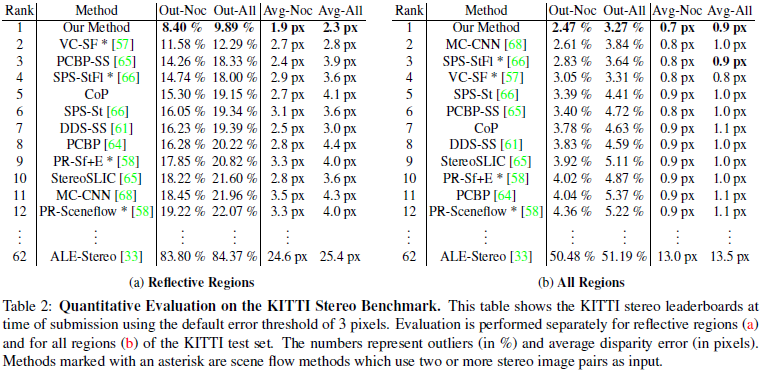
下图表示不同匹配算法的错误率:
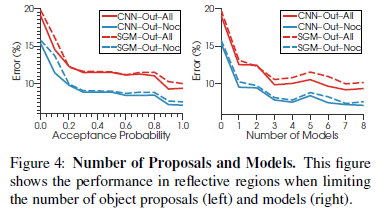
下图表示当分别限制目标proposals和模型树时,反射性区域的效果。横轴为0时表示一直的Displets为0,为1时表示用了所有可能相关的proposals.可以发现Displets越多,算法性能越好。
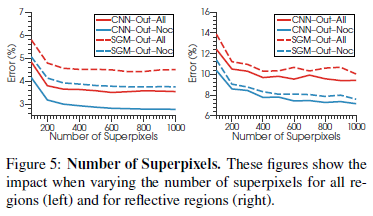
下图对超像素的个数对算法性能的影响进行评估,分别评估所有的区域和反射性区域。最后,在准确度和性能的综合考量下,选择了1000个超像素。
下图表示不使用displets(左)和使用displets(右)的效果差别,每个图都从上往下看。将有大幅度改善的区域用矩形标识出。(大幅度的改善是指物体的反射性,半透明性减低。)最下面的两个是失败的案例,左图中由于三维CAD模型中没有收集罕见的大篷车类的交通工具的距离信息,因此错误率上升。右图失败的原因是由于车和建筑的联系使得语义分割失败,但是整体的重建效果提高了。
6.论文总结
该方法可以减少在弱纹理区域和反射性区域匹配的错误率,大概可以减少50%。该篇论文中,将目标约束在特定的物体类别(车)上,计划将Displets运用到其他的几何类别中,比如建筑,通常是无纹理的但是形状是易于描述的。另一个研究方向是将Displets扩展到花,因为它是一个事先特定的基于光流和场景流非局部类别。
7.个人思考和总结
该论文的两个核心点是:
1.建立了一个较好的能量函数,通过综合各个影响因素并将函数优化,估计像素点视差值,实现立体匹配。
2.结合了图像部分的知识,确定图像中的Proposals。结合三维知识,使用超像素的知识划分图像。首先对图像CAD模型进行网格简化,然后利用三维知识计算KDE确定目标的区域。
易理解错的点:
1.立体匹配并不是确定的物体和物体之间的匹配,不是一幅图像中有一个物体(车),然后去匹配另一个图像,看是否含有这个物体(车)。立体匹配,匹配的是匹配基元,匹配基元有不同的种类。该论文中匹配的应该是像素,计算两幅图像对应位置的视差。立体匹配是计算机视觉中的一个步骤,计算机视觉的目标是从摄像机得到的二维图像中提取三维信息,从而重建三维世界模型。解决立体匹配过程中的歧义问题是为了更好地实现三维重建。
2.最后的效果展示图7,圈框的部分并不是找到了和左图中对应的物体所以把它圈出来了,圈出的部分是使用该论文中的方法后改善效果很明显的区域。论文在开始指出,该方法可以解决传统算法不能解决的无纹理的,反射性,半透明区域的匹配问题。右边的图是使用了Displets方法的,肉眼可以看出,右图相较于左图变暗了,反射性变弱,可以推测出,匹配效果变好了。

















 646
646

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









