







 本文详细介绍了如何使用YOLOv5训练自定义数据集的步骤,包括创建VOCdata文件夹、图片大小重置、图片重命名、使用Labelimg标注、划分训练集与测试集、转换数据集格式以及修改配置文件。最后,通过train.py进行模型训练,为AI目标检测提供了一套完整的流程。
本文详细介绍了如何使用YOLOv5训练自定义数据集的步骤,包括创建VOCdata文件夹、图片大小重置、图片重命名、使用Labelimg标注、划分训练集与测试集、转换数据集格式以及修改配置文件。最后,通过train.py进行模型训练,为AI目标检测提供了一套完整的流程。
YOLOv5训练自己的数据集
文件夹前期大致结构
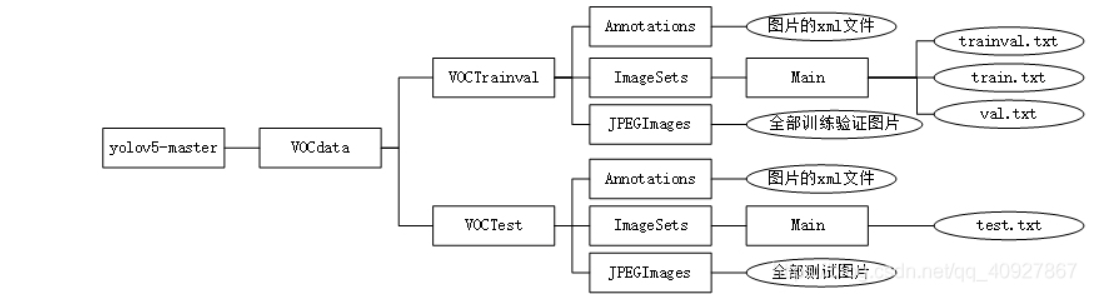
一、创建VOCdata文件夹
在VOCdata文件夹中创建两个子文件夹,分为训练和测试。

将原始图片放入其中文件夹里的old文件夹中。
二、图片大小重置
将原始图片,统一大小。图片大小重置过后保存到JPEGImages文件夹中。
import cv2
import glob
import os
image_path = "D:/pycharm/yolov5/VOCdata/VOCTrainval/old/*.jpg" # 原始图片路径
output_path = "D:/pycharm/yolov5/VOCdata/VOCTrainval/JPEGImages/" # 修改后的保存路径
count = 0
for jpgfile in glob.glob(image_path):
count += 1
#img = Image.open(jpgfile)
image = cv2.imread(jpgfile )
image = cv2.resize(image,(1280,720),interpolation=cv2.INTER_CUBIC)
cv2.imwrite(os.path.join(output_path,os.path.basename(jpgfile)), image)
print("save%d"%count)
print("resize finished!")三、图片重命名
对于统一大小过后的图片,以统一格式重新命名,以便后续增加新的图片进来,代码如下:
import os
path=input('D:/pycharm/yolov5/VOCdata/VOCTrainval/JPEGImages/')
#获取该目录下所有文件,存入列表中
fileList=os.listdir(path)
n=0
m=0 # 图片编号从m+1开始
for i in fileList:
#设置旧文件名(就是路径+文件名)
oldname=path+ os.sep + fileList[n] # os.sep添加系统分隔符
#设置新文件名
newname=path+os.sep +"train"+str(m+1)+".jpg"
os.rename(oldname,newname) #用os模块中的rename方法对文件改名
print(oldname,'======>',newname)
n+=1
m+=1或是下面代码(第一次做自己的数据用的就是这个代码)
from skimage impo 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 18万+
18万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









