







 本文深入解析Linux Shell重定向原理及应用,重点介绍标准输出与错误输出的重定向方法,包括>/dev/null2>&1等命令的使用技巧。
本文深入解析Linux Shell重定向原理及应用,重点介绍标准输出与错误输出的重定向方法,包括>/dev/null2>&1等命令的使用技巧。
连接远程机器执行 shell 命令的一个使用示例:
命令:$(nohup python test.py --slave=wb_spider >& /dev/null < /dev/null &) && sleep 0.1
1、Linux 中 shell 重定向
一段程序在处理完外部的输入后,会将运算结果输出到指定的位置。在交互式的程序中,输入来自用户的键盘和鼠标,结果输出到用户的屏幕,或者播放设备中。而对于某些后台运行的程序,输入可能来自于外部的一些文件,运算的结果通常又写到其他的文件中。而且程序在运行的过程中,会有一些关键性的信息,比如异常堆栈,外部接口调用情况等,这些都会统统写到日志文件里。
一般在使用 shell 命令的时候,更多的是通过键盘输入然后在屏幕上查看命令的执行结果。但是某些情况下需要将 shell 命令的执行结果存储到文件中,那么就需要使用输入输出的重定向功能。例如:shell 脚本中经常会发现 >/dev/null 2>&1
输出 重定向
输出重定向的使用方式很简单,基本的一些命令如下:
| 命令 | 介绍 |
|---|---|
| command >filename | 把标准输出重定向到新文件中 |
| command 1>filename | 同上 |
| command >>filename | 把标准输出追加到文件中 |
| command 1>>filename | 同上 |
| command 2>filename | 把标准错误重定向到新文件中 |
| command 2>>filename | 把标准错误追加到新文件中 |
在使用 > 或者 >> 对输出进行重定向。符号的左边表示文件描述符,如果没有的话表示1,也就是标准输出,符号的右边可以是一个文件,也可以是一个输出设备。
使用 > 时,会判断右边的文件存不存在,如果存在的话就先删除,然后创建一个新的文件,不存在的话则直接创建。但是当使用 >> 进行追加时,则不会删除原来已经存在的文件。
输入 重定向
在理解了输出重定向之后,理解输入重定向就会容易得多。对输入重定向的基本命令如下:
| 命令 | 介绍 |
|---|---|
| command <filename | 以filename文件作为标准输入 |
| command 0<filename | 同上 |
| command <<delimiter | 从标准输入中读入,直到遇到delimiter分隔符 |
使用 < 对输入做重定向,如果符号左边没有写值,那么默认就是0。
# cat input
aaa
111
# cat >out <input
# cat out
aaa
111神奇的事情发生了,out 文件里面的内容被替换成了input文件里的内容。那么 << 又是什么作用呢?我们再看:
# cat >out <<end
> 123
> test
> end
# cat out
123
test看到,当我们输入完 cat >out <<end 然后敲下回车之后,命令并没有结束,此时cat命令像一开始一样,等待你给它输入数据。然后当我们敲入end之后,cat命令就结束了。end 之前输入的字符都已经被写入到了out文件中。这就是输入分割符的作用。
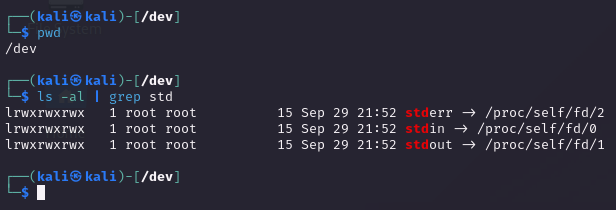
标准 "输入(0)、输出(1)、错误(2)"
当执行 shell 命令时,会默认打开 3 个 文件(文件描述符)
| 类型 | 文件描述符 | 默认情况 | 对应文件句柄位置 |
|---|---|---|---|
| 标准输入(standard input) | 0 | 从键盘获得输入 | /proc/slef/fd/0 |
| 标准输出(standard output) | 1 | 输出到屏幕(即控制台) | /proc/slef/fd/1 |
| 错误输出(error output) | 2 | 输出到屏幕(即控制台) | /proc/slef/fd/2 |
标准输入(文件描述符是0) 就是从键盘获取输入数据,所以在执行 shell 命令时默认从键盘获得输入,并且将结果输出到控制台上。但是可以通过更改文件描述符默认的指向,从而实现输入输出的重定向。比如:将 1 指向文件,那么标准的输出就会输出到文件中。
/dev/null 代表 linux 的空设备文件,所有往这个文件里面写入的内容都会丢失,俗称 "黑洞"
- 2>/dev/null 意思就是把错误输出到 "黑洞"
- >/dev/null 2>&1 默认情况是 1,也就是等同于 1>/dev/null 2>&1 ,就是把标准输出重定向到 "黑洞", 还把错误输出 2 重定向到标准输出 1 ,即 标准输出和错误输出都进了“黑洞”
- 2>&1 >/dev/null 意思就是把错误输出 2 重定向到标准输出 1 中也就是屏幕,标准输出进了 " 黑洞 "。整个意思:也就是标准输出进了黑洞,错误输出打印到屏幕
>/dev/null
这条命令的作用是将标准输出1重定向到 /dev/null中。/dev/null 代表 linux 的 空设备文件,所有往这个文件里面写入的内容都会丢失,俗称 "黑洞"。那么执行了>/dev/null 之后,标准输出就会不再存在,没有任何地方能够找到输出的内容。文件描述符 的 物理文件对应关系
2>&1
linux 在执行 shell 命令之前,就会确定好所有的输入输出位置,并且从左到右依次执行重定向的命令,所以 >/dev/null 2>&1 的作用就是让标准输出重定向到 /dev/null中(丢弃标准输出),然后错误输出由于重用了标准输出的描述符,所以错误输出也被定向到了 /dev/null 中,错误输出同样也被丢弃了。执行了这条命令之后,该条 shell 命令将不会输出任何信息到控制台,也不会有任何信息输出到文件中。
- > 后面跟上 &(注意中间没有空格) ,表示重定向的目标 是 一个文件描述符,而不是一个文件。使用 & 可以将两个输出绑定在一起。命令 2>&1 的作用是错误输出将和标准输出同用一个文件描述符,说人话就是错误输出将会和标准输出输出到同一个地方。
示例:2>/dev/null # 表示重定向到 /dev/null 文件
示例:2>1 # 表示把 标准错误(文件描述符2) 输出到 当前目录下"文件名为1"的文件中
示例:2>&1 # >后面跟上&(注意中间没有空格),表明后面的1是文件描述符。意思就是:把 stderr 重定向到 "文件描述符为1(即/dev/stdout)"的文件中 - &>file 也可以写成 >&file,二者意思完全相同,都等价于 >file 2>&1,此处 &> 或者 >& 视作整体,分开没有单独的含义
正确写法: xxx > tempfile 2>&1
- 先将 程序xxx 要输出到 stdout 的内容,重定向到 文件tempfile,此时 文件tempfile 就是这个程序的stdout
- 再将 程序xxx 的 stderr 重定向到 stdout,也就是文件 tempfile
shell 中可能经常能看到:>/dev/null 2>&1 。命令的结果可以通过 %> 的形式来定义输出,分解这个组合 >/dev/null 2>&1 为五部分。
1:> 代表重定向到哪里,例如:echo "123" > /home/123.txt
2:/dev/null 代表空设备文件
3:2> 表示stderr标准错误
4:& 表示等同于的意思,2>&1,表示 2 的输出重定向等同于 1
5:1 表示stdout标准输出,系统默认值是1,所以">/dev/null"等同于 "1>/dev/null"因此,>/dev/null 2>&1也可以写成 “ 1> /dev/null 2>&1 ”
那么 &>/dev/null 语句执行过程为:
- 1>/dev/null :首先表示标准输出重定向到空设备文件,也就是不输出任何信息到终端,说白了就是不显示任何信息。
- 2>&1 :接着,标准错误输出重定向 到标准输出,因为之前标准输出已经重定向到了空设备文件,所以标准错误输出也重定向到空设备文件。
错误写法: xxx 2>&1 > tempfile
- 先将要输出到 stderr 的内容重定向到 stdout,此时会产生一个 stdout 的拷贝,作为程序的stderr,而程序原本要输出到 stdout 的内容,依然是对接在 stdout 原身上的,
- 因此第二步重定向 stdout,对 stdout 的拷贝不产生任何影响
>/dev/null 2>&1 对比 2>&1 >/dev/null
两条命令貌似是等同的,但其实大为不同。linux在执行shell命令之前,就会确定好所有的输入输出位置,并且从左到右依次执行重定向的命令。那么我们同样从左到右地来分析2>&1 >/dev/null:
- 2>&1,将错误输出绑定到标准输出上。由于此时的标准输出是默认值,也就是输出到屏幕,所以错误输出会输出到屏幕。
- >/dev/null,将标准输出1重定向到/dev/null中。
用一个表格来更好地说明这两条命令的区别:
| 命令 | 标准输出 | 错误输出 |
|---|---|---|
| >/dev/null 2>&1 | 丢弃 | 丢弃 |
| 2>&1 >/dev/null | 丢弃 | 屏幕 |
>/dev/null 2>&1 对比 >/dev/null 2>/dev/null
尝试将标准输出和错误输出都定向到out文件中:
# ls a.txt b.txt >out 2>out
# cat out
a.txt
�法访问b.txt: 没有那个文件或目录WTF?竟然出现了乱码,这是为啥呢?这是因为采用这种写法,标准输出和错误输出会抢占往out文件的管道,所以可能会导致输出内容的时候出现缺失、覆盖等情况。现在是出现了乱码,有时候也有可能出现只有error信息或者只有正常信息的情况。不管怎么说,采用这种写法,最后的情况是无法预估的。
而且,由于out文件被打开了两次,两个文件描述符会抢占性的往文件中输出内容,所以整体IO效率不如>/dev/null 2>&1来得高。
结合 nohup
使用 nohup command & 形式的命令可以启动一些后台程序。
示例:# nohup java -jar xxxx.jar &
为了不让一些执行信息输出到前台(控制台),还会加上刚才提到的 >/dev/null 2>&1 命令来丢弃所有的输出:nohup java -jar xxxx.jar >/dev/null 2>&1 &
在工作中用到最多的就是:nohup command >/dev/null 2>&1 &
2、$( ) 与 ` ` (反引号)
在 bash shell 中,$( ) 与 ` ` (反引号) 都是用来做命令替换用 (command substitution)的。所谓的命令替换和变量替换差不多,都是用来重组命令行:
例如:echo the last sunday is $(date -d "last sunday" +%Y-%m-%d)
[king@ubuntu ~]$ echo the last sunday is $(date -d "last sunday" +%Y-%m-%d)
the last sunday is 2018-08-05
[king@ubuntu ~]$如此便可方便得到上一星期天的日期了
用 $( ) 的理由
- ` ` 很容易与 ' ' ( 单引号)搞混乱,尤其对初学者来说。
- 在多层次的复合替换中,` ` 须要额外的跳脱( \` )处理,而 $( ) 则比较直观。
例如:这是错的:command1 `command2 `command3` `
原本的意图是要在 command2 `command3` 先将 command3 提换出来给 command 2 处理,
然后再将结果传给 command1 `command2 …` 来处理。
然而,真正的结果在命令行中却是分成了 `command2 ` 与 “ 两段。
正确的输入应该是:command1 `command2 \`command3\` `
要不然,换成 $( ) 就没问题了:command1 $(command2 $(command3))
$( ) 的不足
- ` ` 基本上可用在全部的 unix shell 中使用,若写成 shell script ,其移植性比较高。
- 而 $( ) 并不见的每一种 shell 都能使用
变量 替换
一般情况下,$var 与 ${var} 并没有啥不一样。但是用 ${ } 会比较精确的界定变量名称的范围,比方说:
[king@ubuntu ~]$ A=B
[king@ubuntu ~]$ echo $AB
原本是打算先将 $A 的结果替换出来,然后再补一个 B 字母于其后,
但在命令行上,真正的结果却是只会提换变量名称为 AB 的值出来…
若使用 ${ } 就没问题了:
[king@ubuntu ~]$ echo ${A}B
BB
精华文章:http://www.chinaunix.net/forum/viewtopic.php?t=201843
一些例子加以说明 ${ } 的一些特异功能:
假设定义了一个变量为:
file=/dir1/dir2/dir3/my.file.txt
我们可以用 ${ } 分别替换获得不同的值:
${file#*/}:拿掉第一条 / 及其左边的字符串:dir1/dir2/dir3/my.file.txt
${file##*/}:拿掉最后一条 / 及其左边的字符串:my.file.txt
${file#*.}:拿掉第一个 . 及其左边的字符串:file.txt
${file##*.}:拿掉最后一个 . 及其左边的字符串:txt
${file%/*}:拿掉最后条 / 及其右边的字符串:/dir1/dir2/dir3
${file%%/*}:拿掉第一条 / 及其右边的字符串:(空值)
${file%.*}:拿掉最后一个 . 及其右边的字符串:/dir1/dir2/dir3/my.file
${file%%.*}:拿掉第一个 . 及其右边的字符串:/dir1/dir2/dir3/my
记忆的方法为:
[list]# 是去掉左边(在鉴盘上 # 在 $ 之左边)
% 是去掉右边(在鉴盘上 % 在 $ 之右边)
单一符号是最小匹配﹔两个符号是最大匹配。[/list]
${file:0:5}:提取最左边的 5 个字节:/dir1
${file:5:5}:提取第 5 个字节右边的连续 5 个字节:/dir2
我们也可以对变量值里的字符串作替换:
${file/dir/path}:将第一个 dir 提换为 path:/path1/dir2/dir3/my.file.txt
${file//dir/path}:将全部 dir 提换为 path:/path1/path2/path3/my.file.txt
利用 ${ } 还可针对不同的变量状态赋值(没设定、空值、非空值):
${file-my.file.txt} :假如 $file 没有设定,则使用 my.file.txt 作传回值。(空值及非空值时不作处理)
${file:-my.file.txt} :假如 $file 没有设定或为空值,则使用 my.file.txt 作传回值。 (非空值时不作处理)
${file+my.file.txt} :假如 $file 设为空值或非空值,均使用 my.file.txt 作传回值。(没设定时不作处理)
${file:+my.file.txt} :若 $file 为非空值,则使用 my.file.txt 作传回值。 (没设定及空值时不作处理)
${file=my.file.txt} :若 $file 没设定,则使用 my.file.txt 作传回值,同时将 $file 赋值为 my.file.txt 。 (空值及非空值时不作处理)
${file:=my.file.txt} :若 $file 没设定或为空值,则使用 my.file.txt 作传回值,同时将 $file 赋值为 my.file.txt 。 (非空值时不作处理)
${file?my.file.txt} :若 $file 没设定,则将 my.file.txt 输出至 STDERR。 (空值及非空值时不作处理)
${file:?my.file.txt} :若 $file 没设定或为空值,则将 my.file.txt 输出至 STDERR。 (非空值时不作处理)
tips:
以上的理解在于, 你一定要分清楚 unset 与 null 及 non-null 这三种赋值状态.
一般而言, : 与 null 有关, 若不带 : 的话, null 不受影响, 若带 : 则连 null 也受影响.
还有哦,${#var} 可计算出变量值的长度:
${#file} 可得到 27 ,因为 /dir1/dir2/dir3/my.file.txt 刚好是 27 个字节…
接下来,再为大家介稍一下 bash 的组数(array)处理方法。
一般而言,A="a b c def" 这样的变量只是将 $A 替换为一个单一的字符串,
但是改为 A=(a b c def) ,则是将 $A 定义为组数…
bash 的组数替换方法可参考如下方法:
${A[@]} 或 ${A[*]} 可得到 a b c def (全部组数)
${A[0]} 可得到 a (第一个组数),${A[1]} 则为第二个组数…
${#A[@]} 或 ${#A[*]} 可得到 4 (全部组数数量)
${#A[0]} 可得到 1 (即第一个组数(a)的长度),${#A[3]} 可得到 3 (第四个组数(def)的长度)
A[3]=xyz 则是将第四个组数重新定义为 xyz …
好了,最后为大家介绍 $(( )) 的用途吧:它是用来作整数运算的。
在 bash 中,$(( )) 的整数运算符号大致有这些:
+ - * / :分别为 "加、减、乘、除"。
% :余数运算
& | ^ !:分别为 "AND、OR、XOR、NOT" 运算。
例:
$ a=5; b=7; c=2
$ echo $(( a+b*c ))
19
$ echo $(( (a+b)/c ))
6
$ echo $(( (a*b)%c))
1
在 $(( )) 中的变量名称,可于其前面加 $ 符号来替换,也可以不用,如:
$(( $a + $b * $c)) 也可得到 19 的结果
此外,$(( )) 还可作不同进位(如二进制、八进位、十六进制)作运算呢,只是,输出结果皆为十进制而已:
echo $((16#2a)) 结果为 42 (16进位转十进制)
以一个实用的例子来看看吧:
假如当前的 umask 是 022 ,那么新建文件的权限即为:
$ umask 022
$ echo "obase=8;$(( 8#666 & (8#777 ^ 8#$(umask)) ))" | bc
644
事实上,单纯用 (( )) 也可重定义变量值,或作 testing:
a=5; ((a++)) 可将 $a 重定义为 6
a=5; ((a–)) 则为 a=4
a=5; b=7; ((a < b)) 会得到 0 (true) 的返回值。
常见的用于 (( )) 的测试符号有如下这些:
<:小于
>:大于
<=:小于或等于
>=:大于或等于
==:等于
!=:不等于

















 2300
2300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









