









在springboot微服务中采集日志推送kafka
背景
在分布式的项目中,各功能模块产生的日志比较分散,同时为满足性能要求,同一个微服务会集群化的部署,当某一次业务中报错后,如果不能确定产生的节点,那么只能逐个节点去查看日志文件,logback中RollingFileAppender,ConsoleAppender这类同步化记录器也降低系统性能,综上一些问题,可能考虑采用ELK (elasticsearch+logstash+kibana)配合消息中间件去异步采集,统一展示去解决。
这里采用kafka 去作为消息中间件异步推送日志
整体流程图
流程图:
快速搭建kafka+zk开发环境
在任意宿主机上创建一个docker-compose.yml文件,将内容复制进去,替换一下ip.我这里宿主机IP为192.168.1.149
vi docker-compose.yml #这里将下面内容复制进去,然后wq保存退出
docker-compose up -d #启动服务 ,这里一定要cd到docker-compose.yml同级目录再执行
docker-compose.yml内容如下
version: "2"
services:
zookeeper:
image: docker.io/bitnami/zookeeper:3.8
ports:
- "2181:2181"
environment:
- ALLOW_ANONYMOUS_LOGIN=yes
networks:
- es_default
kafka:
image: docker.io/bitnami/kafka:3.2
user: root
ports:
- "9092:9092"
environment:
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://192.168.1.149:9092 #这里替换为你宿主机IP或host,在集群下,各节点会把这个地址注册到集群,并把主节点的暴露给客户端,不要注册localhost
# - KAFKA_CFG_LISTENERS=PLAINTEXT://0.0.0.0:9092
depends_on:
- zookeeper
networks:
- es_default
networks:
es_default:
name: es_default
# external: true
volumes:
zookeeper_data:
driver: local
kafka_data:
driver: local
通过logback记录日志到kafka
引用kafka-clients依赖,注意版本最好跟服务端一致
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.2.0</version>
</dependency>
Springboot中默认采用的logback实现日志记录,因此可以仿照ConsoleAppender,去承继OutputStreamAppende在项目中创建一个基于Kafka记录日志的KafkaAppender,最好是独立一个日志模块,方便其它业务模块引用
我这里可能开发机性能的问题,有个奇怪的问题,必须要调整一下max.block.ms ,即降低消息阻塞时间,否则我这会经常性阻塞60秒(默认值)
package com.kuizii.base.log;
import ch.qos.logback.classic.spi.ILoggingEvent;
import ch.qos.logback.classic.spi.LoggingEvent;
import ch.qos.logback.core.AppenderBase;
import ch.qos.logback.core.Layout;
import ch.qos.logback.core.OutputStreamAppender;
import ch.qos.logback.core.util.EnvUtil;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.springframework.util.StringUtils;
import java.io.OutputStream;
import java.util.Properties;
public class KafkaAppender<E> extends OutputStreamAppender<E> {
private Producer logProducer;
private String bootstrapServers;
private Layout<E> layout;
private String topic;
public void setLayout(Layout<E> layout) {
this.layout = layout;
}
public void setBootstrapServers(String bootstrapServers) {
this.bootstrapServers = bootstrapServers;
}
public void setTopic(String topic) {
this.topic = topic;
}
@Override
protected void append(E event) {
if (event instanceof ILoggingEvent) {
String msg = layout.doLayout(event);
ProducerRecord<String, String> producerRecord = new ProducerRecord<>(topic, 0,((ILoggingEvent) event).getLevel().toString(), msg);
logProducer.send(producerRecord);
}
}
@Override
public void start() {
if (StringUtils.isEmpty(topic)) {
topic = "Kafka-app-log";
}
if (StringUtils.isEmpty(bootstrapServers)) {
bootstrapServers = "localhost:9092";
}
logProducer = createProducer();
OutputStream targetStream = new KafkaOutputStream(logProducer, topic);
super.setOutputStream(targetStream);
super.start();
}
@Override
public void stop() {
super.stop();
if (logProducer != null) {
logProducer.close();
}
}
//创建生产者
private Producer createProducer() {
synchronized (this) {
if (logProducer != null) {
return logProducer;
}
Properties props = new Properties();
props.put("bootstrap.servers", bootstrapServers);
//判断是否成功,我们指定了“all”将会阻塞消息 0.关闭 1.主broker确认 -1(all).所在节点都确认
props.put("acks", "0");
//失败重试次数
props.put("retries", 0);
//延迟100ms,100ms内数据会缓存进行发送
props.put("linger.ms", 100);
//超时关闭连接
//props.put("connections.max.idle.ms", 10000);
props.put("batch.size", 16384);
props.put("buffer.memory", 33554432);
//该属性对性能影响非常大,如果吞吐量不够,消息生产过快,超过本地buffer.memory时,将阻塞1000毫秒,等待有空闲容量再继续
props.put("max.block.ms",1000);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
return new KafkaProducer<String, String>(props);
}
}
}
然后在各业务需要记录日志的模块中配置logback.xml
在logback.xml中添加一个KafkaAppender,如下所示:
<appender name="kafkalog" class="com.kuizii.base.log.KafkaAppender">
<bootstrapServers>192.168.1.149:9092</bootstrapServers>
<topic>demoCoreKafkaLog</topic>
<encoder>
<pattern>%date %level [%thread] %logger{36} [%file : %line] %msg%n</pattern>
<charset>utf8</charset>
</encoder>
<layout class="ch.qos.logback.classic.PatternLayout">
<pattern>%date %level [%thread] %logger{36} [%file : %line] %msg%n</pattern>
</layout>
</appender>
启动系统,日志将被写入kafka队列 ,等待logstash消费并推送ES ,当然其实也可以直接推送ES,不足Kafka为的就是提高性能。
快速搭建ELK环境
接下来将创建Elasticsearch+Kibana+Logstash+Merticbeat.四个工具,用途如下
Elasticsearch采用restful接收http请求调用lucene建立索引作全文检索
Kibana展示日志,图表,看板
Merticbeat对各工具将于指标监控,比如内存,CPU,IO,这里不多讲
Logstash用于从各数据源获取数据,清理,过滤,转换后发给另一数据源。
我这里elasticsearch 7.11.*版本的授权license对云服务商之类要商用的有开源限制,一般商用不影响,我这里采用的7.10.1
我们需要先创建一个logstash工作任务,目前将我们kafka中的日志消息获取出来 ,再推送给elasticsearch。在宿主机上创建一个任务文件,如logstash.conf内容如下
input {
kafka {
bootstrap_servers => "192.168.1.149:9092" #kafka的地址,替换为你自己的
client_id => "logstash"
auto_offset_reset => "latest"
consumer_threads => 5
topics => ["demoCoreKafkaLog","webapiKafkaApp"] #获取哪些topic
type => demo #自定义
# codec => "json"
}
}
output {
stdout { }
elasticsearch {
hosts => ["http://elasticsearch:9200"] #es地址,这里由于上面docker-compose中几个服务在一个虚拟网络在,可以用服务名代替
index => "demolog-%{+YYYY.MM.dd}" #这里将会是创建的索引名,后续 kibana将会用不同索引区别
#user => "elastic"
#password => "changeme"
}
}
然后还是定义一个docker-compose.yml,然后docker-compose up -d 去创建服务容器
version: "2"
services:
elasticsearch:
image: elasticsearch:7.10.1
restart: always
privileged: true
ports:
- "9200:9200"
- "9300:9300"
volumes:
- "/d/workspace/es/data:/usr/share/elasticsearch/data"
environment:
- discovery.type=single-node
networks:
- es_default
kibana:
image: kibana:7.10.1
restart: always
privileged: true
ports:
- "5601:5601"
environment:
- ELASTICSEARCH_URL=http://elasticsearch:9200
depends_on:
- elasticsearch
networks:
- es_default
metricbeat:
image: elastic/metricbeat:7.10.1
restart: always
user: root
environment:
- ELASTICSEARCH_HOSTS=http://elasticsearch:9200
depends_on:
- elasticsearch
- kibana
command: setup -E setup.kibana.host=kibana:5601 -E output.elasticsearch.hosts=["elasticsearch:9200"] -E setup.ilm.overwrite=true
networks:
- es_default
logstash:
image: elastic/logstash:7.10.1
restart: always
user: root
volumes:
- /d/workspace/logstash/pipeline/:/usr/share/logstash/pipeline/ #这里将冒号前段的路径改为宿主机的路径,用于存放转换任务
depends_on:
- elasticsearch
- kibana
networks:
- es_default
networks:
es_default:
driver: bridge
name: es_default
创建完成,稍等各服务启动完成,有点慢,可能一两分钟,然后通过 http://host:9200访问es,看是否成功
http://host:5601访问kibana.
docker logs [logstash容器名] 查看logstash的日志,如下,已经接收到了Kafka的消息。

最后,就可以在kibana中展示了。
Kibana查看,统计日志
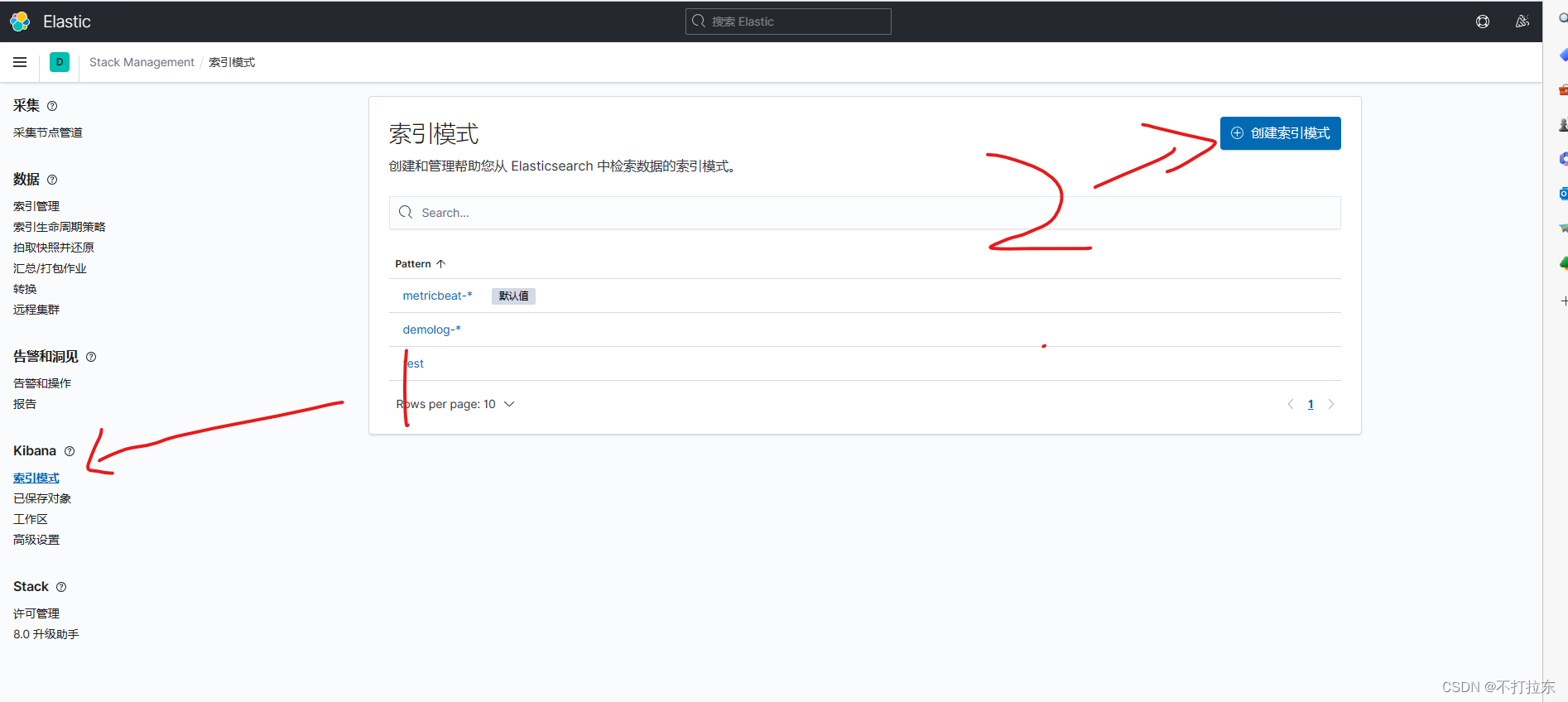
访问 http://kibana:5601。在如下进入索引管理
点击创建索引模式,准备或模糊匹配索引名称,然后完成创建
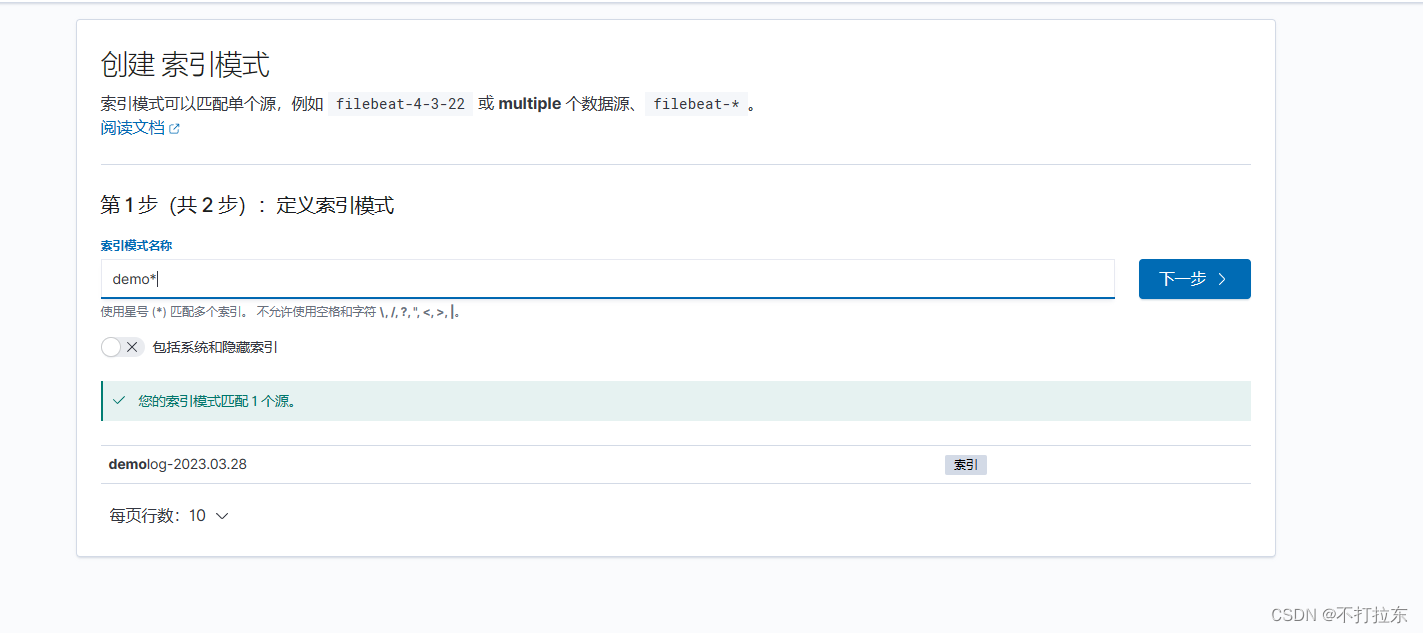
最后,创建一个展示页如图
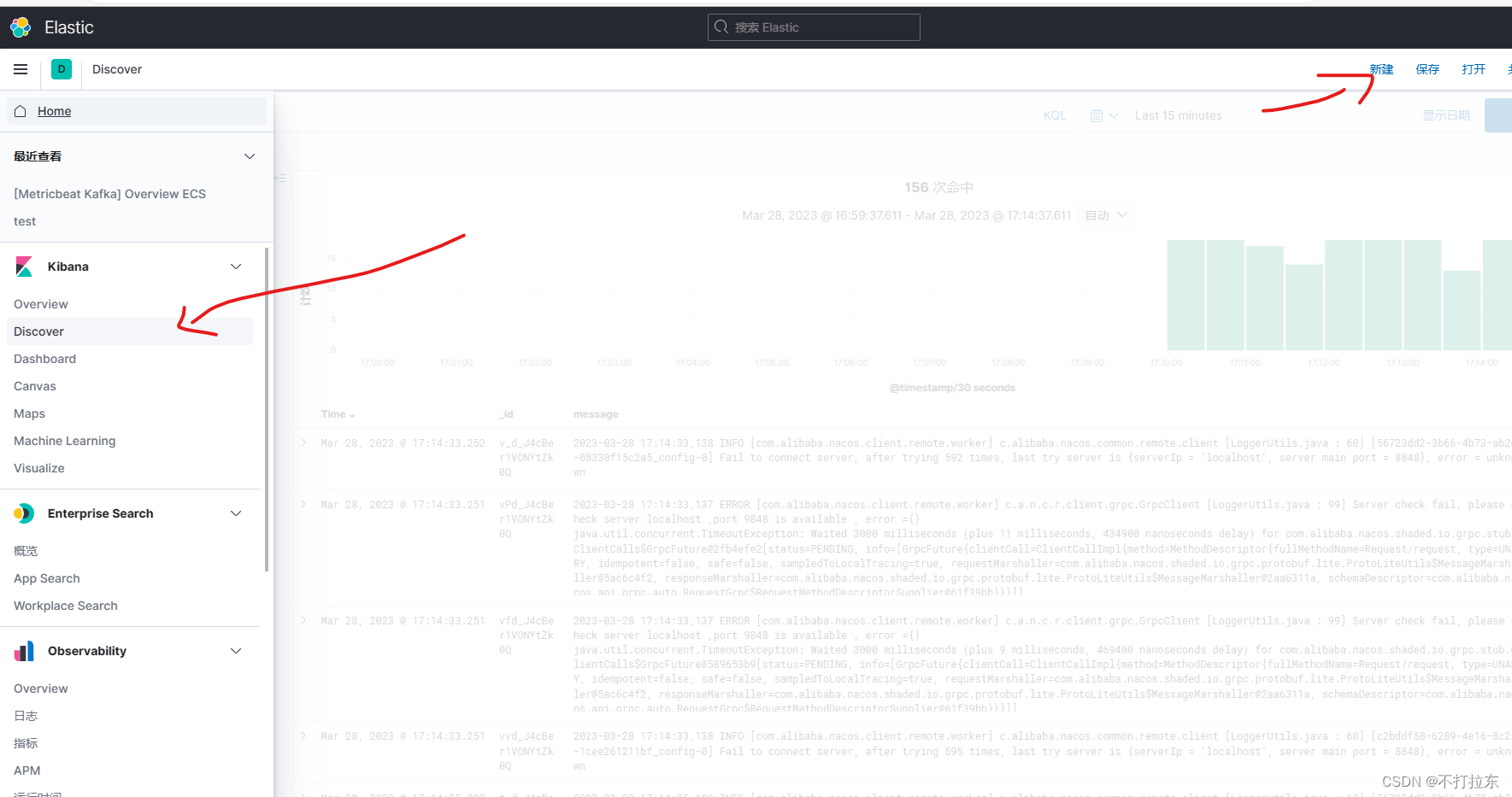
如下1中选择刚刚创建的索引模式,2中选择要展示的字段 ,右侧就可以看到各微服务中收集的日志了,右上保存,以后便可以直接使用了。
至于想要高级的使用技巧,可以深入查看kibana教程,如我有空,可能也会写相关文章。
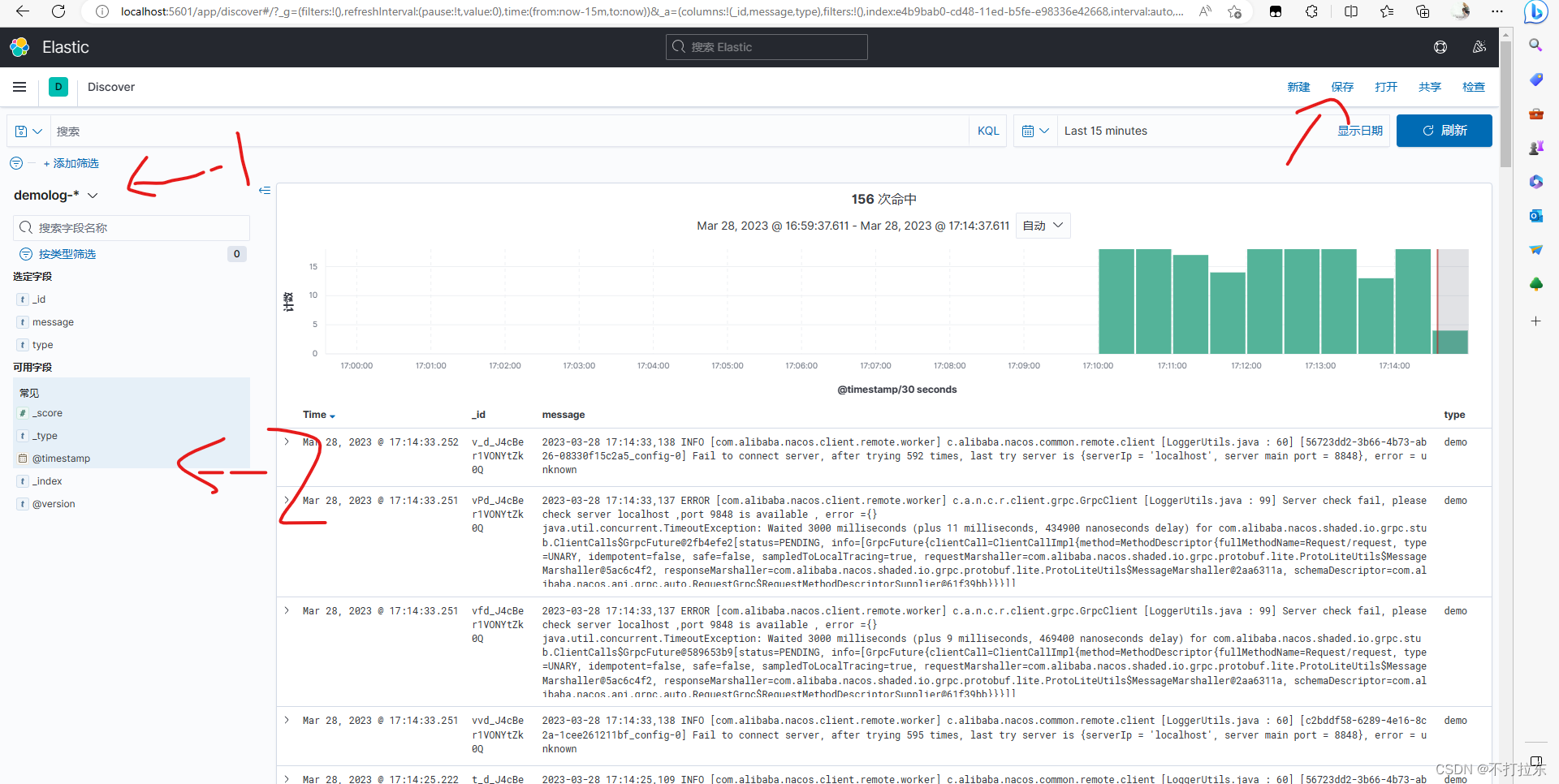
最后,KafkaAppender源码如下
源码链接
















 601
601











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









