






四、基本概念
这部分和C语言重复的部分就简写速过,因为我之前写过一个C语言的系列,非常详细。C和C++这些都是一样的,所以这里不再一遍遍重复码字了。感兴趣的同学可以翻看我之前的C语言系列文章。
1、数据类型
编程的本质就是操作数据。
操作数据就是读数据、进行计算、写数据,其中读和写必然要牵扯到数据的存储。
数据的存储就必须要有数据的名字(变量名)、数据的内容(变量值)、数据的类型(变量类型)。
名字和值好理解,那为啥要类型呢?类型表示给这个变量一个多大的空间去存储它,比如一个字母a就给1个字节(8bit)就可以了,多了就是浪费;一个整数一般给4个字节,就是32位,当然你还可以规定比如第一个位表示符号位,这样就是可以表示正整数和负整数了,那剩下的31位,就能最大存一个2的31次方这个数字,当然如果你存了31个0,那就是0了,如果你存了31个1,那就是数字2的31次方了。也所以不是你想存多大就能存多大的,数字超过2的31次方,就会发生溢出,也就是你存的数字并不是你想存的数字了。
所以数据类型就是指这个数据存放空间的大小。不同的数据类型意味着占用不同大小的内存空间。
下图是基本的数据类型: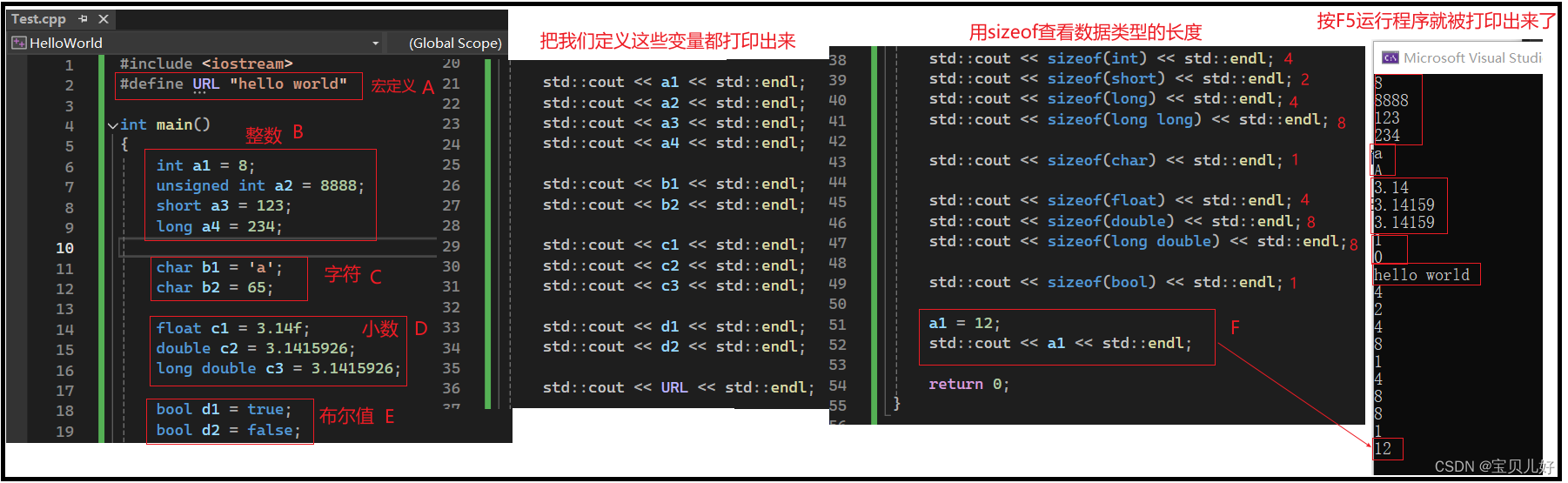
说明:
(1)数据首先是分为常量和变量。在程序运行的过程中,其值不能被改变的叫常量。可以改变的叫变量,入上图F。
常量我们用宏定义,上图A,宏URL就表示字符串“hello world”。上图中BCDE都是变量。
(2)不管是常量还是变量,对计算机来说最重要的是地址和类型!所谓的变量名其实是给程序员看的。计算机只要知道这个数据的首地址和占用内存的大小即可,它不需要知道这个数据的名称。数据名称只是程序员写的代码和编译器之间的沟通信号。编译器和代码用变量名沟通完毕后,编译器再和cpu传话时,用的就是这个数据的首地址和占用空间了。
(3)如果是整数变量,你可以定义变量的类型为int,short,long,long long这4种类型之一。其中int类型占用4个字节,short类型占2个字节,long类型占4个字节,long long 类型占8个字节。占用字节的大小决定着你这个数字在内存中的存储空间的大小,也就是决定着你存储的数字的上下限。unsigned表示是否有符号位。
同理其他数据类型。
(4)不同的数据类型给分配多大的内存,一般是取决于编译器,不同类型编译器之间会有差异,一般情况下,不会相差太大。
(5)bool类型不是取1就是取0,是不是1个比特位就够用了,为啥给分一个字节的空间呢?因为我们寻址内存的是是按照字节寻找的,找不到位的哈。
(6)除了上面展示的数据类型,你也可以创建自定义数据类型,但你自定义的类型都是在这些基本类型之上创建的。
(7)数据转化为指针或引用。指针通过一个*号来声明,引用用&表示。说来话长,这些以后要专门聊。
2、函数
函数就是我们写的代码块,被设计用来执行特定的任务。
如果函数被放到类里面了,就叫做方法了。所以这里我们讲的是函数不是方法。
为啥要函数?避免重复写相同的代码。你就理解为把某项特定的功能封装起来。你啥时候想用这个功能了,你调用这个函数就可以了。下面用例子展示: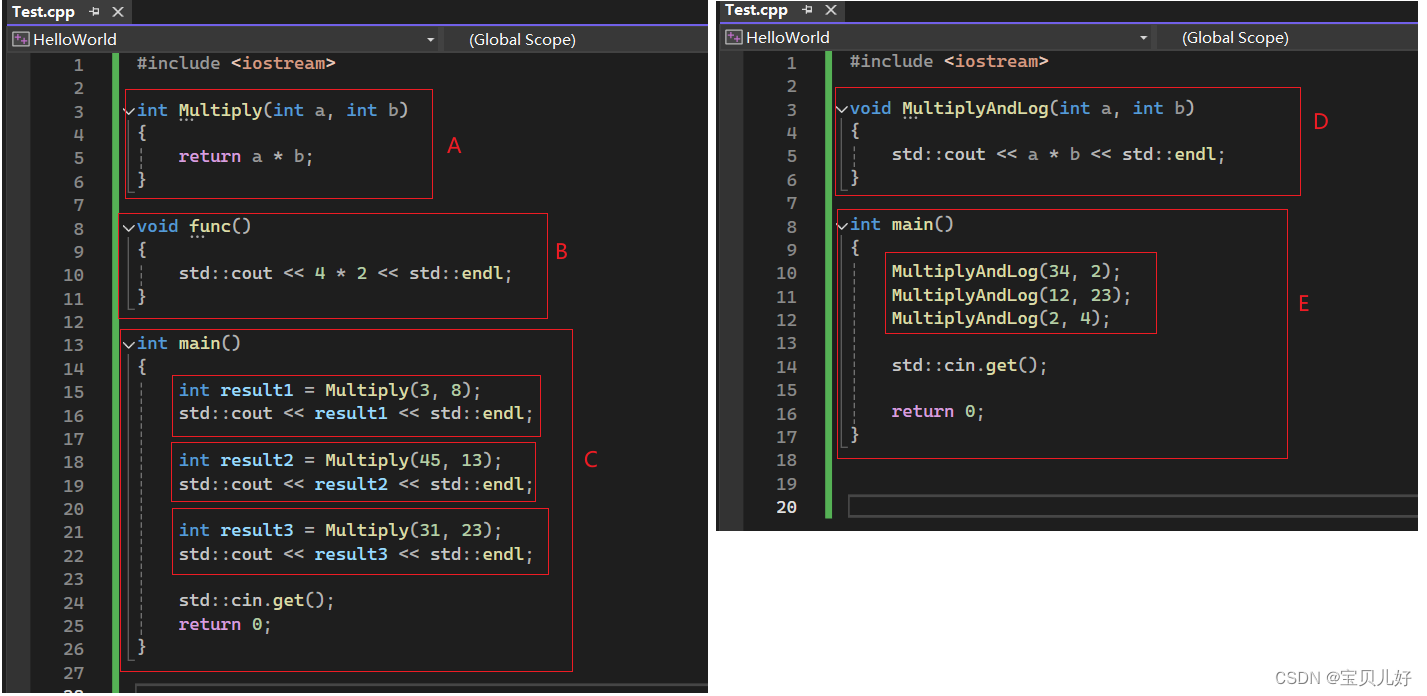 左图所示:我写了3个函数A、B、C。函数A的名字是Multiply,名字前面的int表示函数的返回值的类型是整型,名字后面的括号里是参数。这个函数有两个参数,a和b,参数a和b的类型都是int类型。函数B的名字是func,这个函数只是要实现在屏幕上打印一个4x2的结果,所以也不需要什么参数,所以小括号里面啥参数也不用写。又因为这个函数也不返回啥,所以函数名前面的返回值类型是void,void就是啥也没有的意思。函数C就是我们常说的main函数,是一个程序的入口函数,因为不需要传入任何参数,所以后面小括号里面啥也不用写,又因为其返回值是0,所以main前面是int。
左图所示:我写了3个函数A、B、C。函数A的名字是Multiply,名字前面的int表示函数的返回值的类型是整型,名字后面的括号里是参数。这个函数有两个参数,a和b,参数a和b的类型都是int类型。函数B的名字是func,这个函数只是要实现在屏幕上打印一个4x2的结果,所以也不需要什么参数,所以小括号里面啥参数也不用写。又因为这个函数也不返回啥,所以函数名前面的返回值类型是void,void就是啥也没有的意思。函数C就是我们常说的main函数,是一个程序的入口函数,因为不需要传入任何参数,所以后面小括号里面啥也不用写,又因为其返回值是0,所以main前面是int。
左图的Multiply函数就是一个“实现两个数相乘计算出结果”这个功能的函数。我们在C函数体内调用了3次Multiply函数。但是有没有发现,在main函数里写了3遍cout,是不是很麻烦。所以右图我们再写一个MutiplyAndLog函数,把A和B的功能都包含进来,是不是右图的main函数就简洁了很多!对这就是函数的封装打包,就是为了避免重复写代码!
函数有声明和定义。声明通常存储在头文件中,我们在翻译单元或cpp文件中编写定义
函数很重要,每个程序都是由一系列函数组成的。所以这里简单过一下函数调用过程中的堆栈:
堆(Heap)与栈(Stack)是开发人员必须面对的两个概念,不同场景下,堆与栈代表不同的含义。一般情况下,有两层含义:
(1)程序内存布局场景下,堆与栈表示两种内存管理方式;
(2)数据结构场景下,堆与栈表示两种常用的数据结构。
这里的堆栈通常称为调用栈或执行栈,是由操作系统和编译器共同管理的一种数据结构,用于存储函数调用的上下文信息。下面展示一个函数调用的粒子:
可见一个程序的运行一般是在内存中跳来跳去执行函数的。函数的prologue、epilogue是自动由编译器生成的,它的具体实现细节可能因编程语言、编译器、目标架构和调用约定的不同而有所变化。例如,在x86架构的C语言中,函数prologue和函数 epilogue 的典型汇编代码可能如下:
3、头文件
头文件通常用于声明一些函数。头文件中有很多函数声明,使我们在多个.cpp文件中使用。头文件就是我们声明函数的一个公共地方。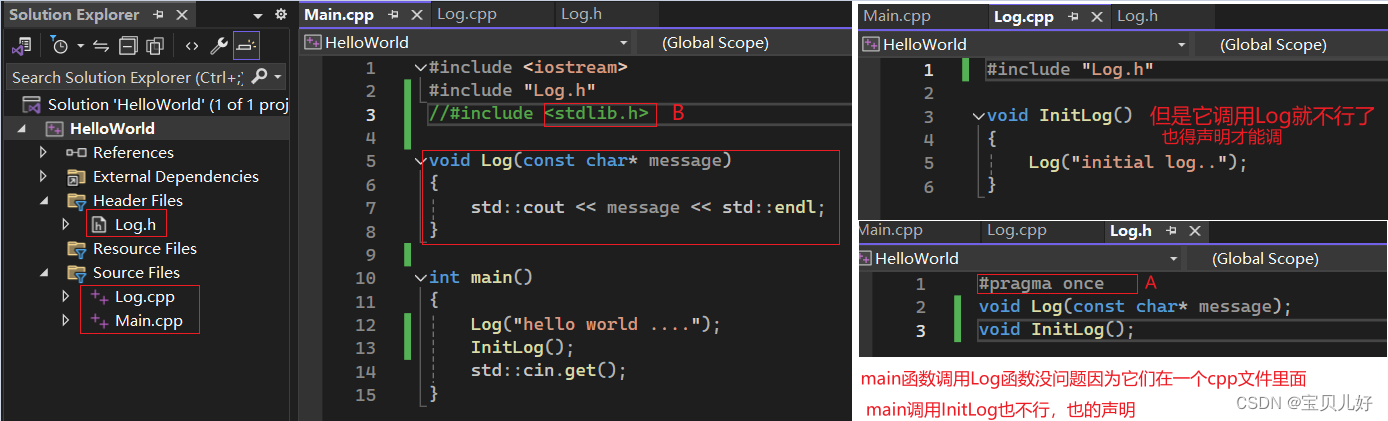
如上图所示,如果每个.cpp文件用到的函数都得声明一下,就非常麻烦,所以我们所有的函数的声明都放到.h文件中,然后在.cpp中include这个头文件,当预编译时就相当于是声明了。
A:这条语句的意思是只声明一次。当我们有多个头文件时,很难保证多个头文件中的声明函数没有重复的,当我们把多个头文件都include到.cpp文件中时,就会出现重复声明,就会报错,pragma once可以避免多次声明。
B:有的有头文件有后缀.h,有的头文件没有后缀,这是因为C++标准库和C标准库的区分。C++标准库的头文件文件名都没有扩展名,以此和C标准库进行区分。
C:include头文件时,有的用尖括号有的用双引号是因为:尖括号只用于编译器包含的默认路径,而如果你使用引号,那就自由很多,你可以写任意的你的相对路径。
4、断点调试
如果你的代码有语法错误,那编译时就会报错,你按照报错信息调试代码即可。但是如果你的代码能顺利运行但就是运行结果非你所想、或者运行过程中系统崩溃等现象,这些你就没法通过报错信息调试了,此时很重要的调试方法就是打断点->读取内存信息,去分析为啥运行过程中没有按照你的预期执行。
设置断点是为了读取内存。断点就是暂停的意思,程序执行到断点处就会挂起执行线程,此时程序的状态,就是你内存的状态。此时你查看内存视图,诊断你程序出问题的原因。
(1)如何进入断点调试模式: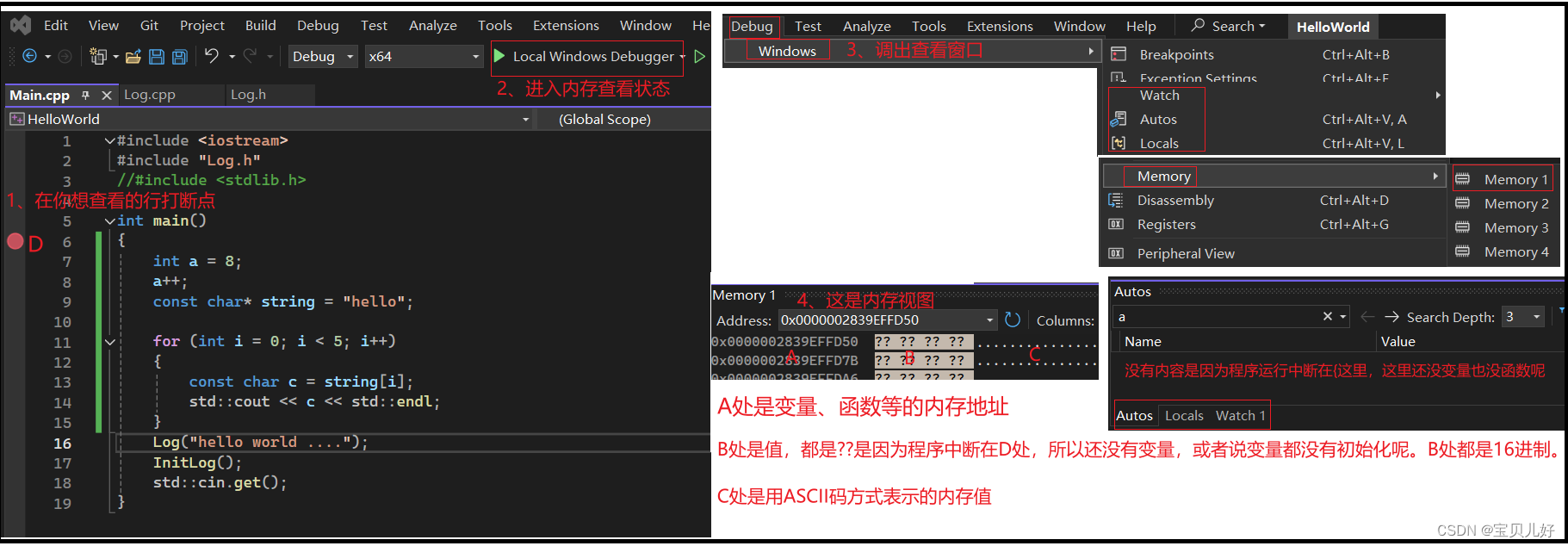
(2)内存查看的基本操作: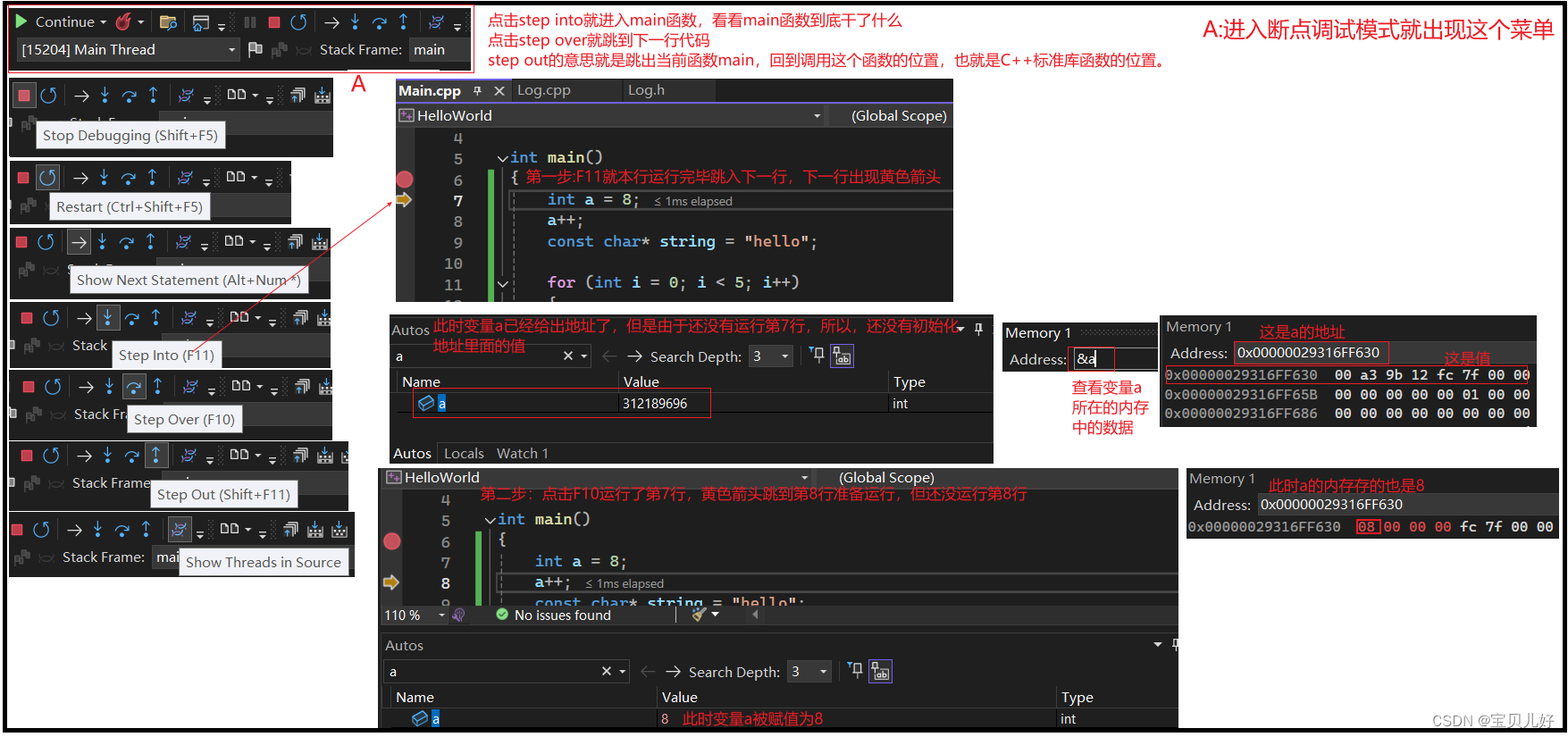
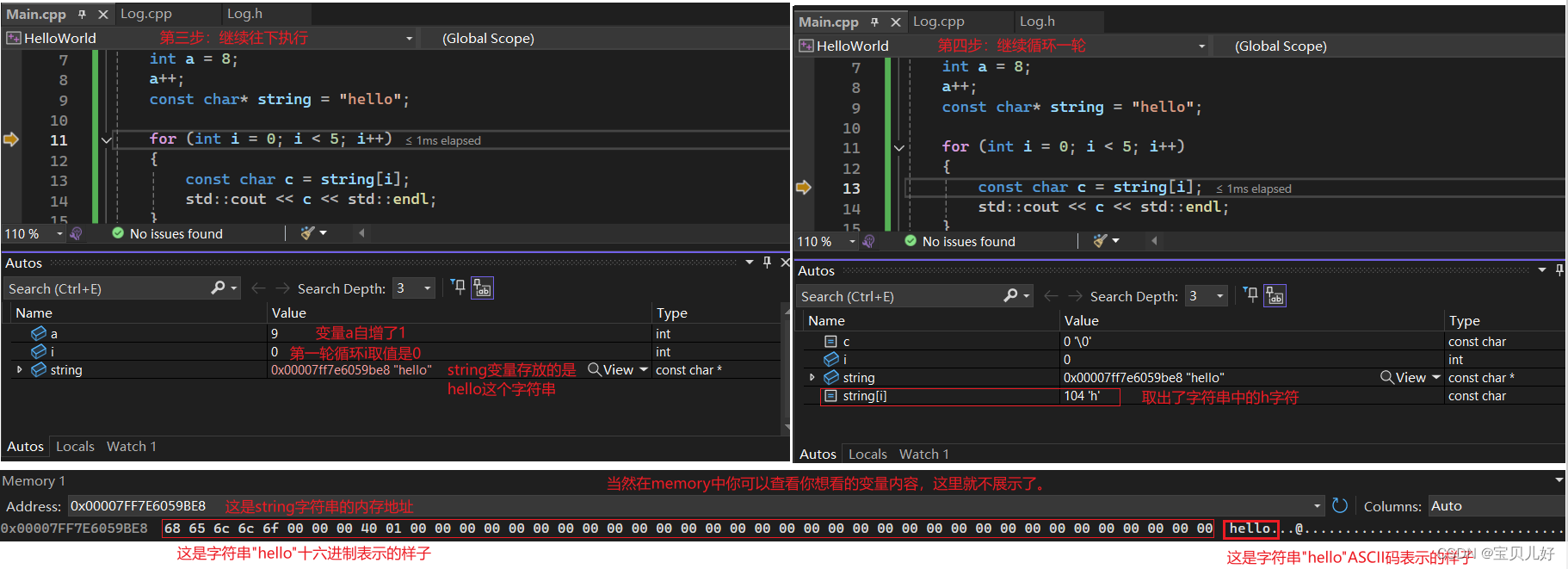
以上就是打断点,读取内存的方法。断点调试的内容很深很深,这里只是入门展示一下。
5、输入输出
(1)C与C++的输入输出方式对比
输入输出是人机交互的最直接方式,我们以后会经常用到。为了防止有些学过C的同学混淆,我们先区分一下C与C++的输入和输出。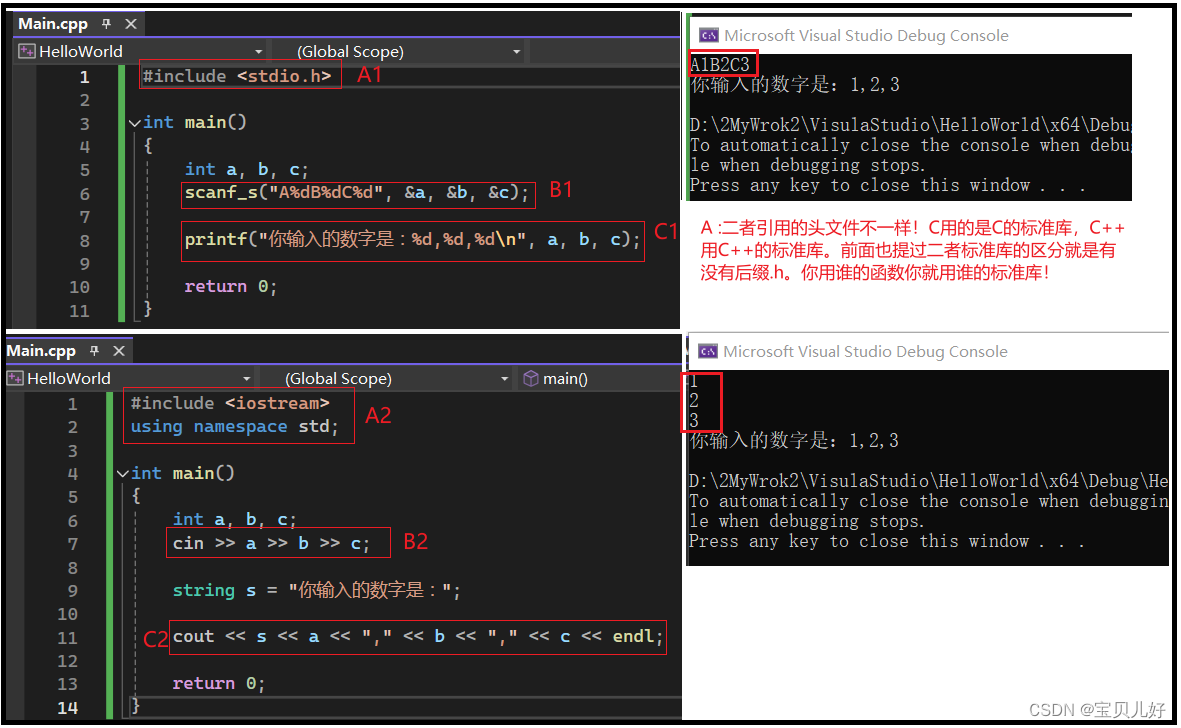
我们先看输入:
C用的函数是scanf(),我这里用scanf_s是因为我用的是C++编译的,会报这个函数更新了,让我用scanf_s替代,这没关系。
我们看scanf_s函数,函数第一个参数:它是一个包含占位符的字符串,后面的参数是这些占位符的地址,&是取址符。
函数的返回值是成功赋值的数据个数。
说明:当程序执行到scanf_s时,程序就停止在控制台,等待用户输入。用户一定要按照A数字B数字C数字的方式输入,也就是第一个参数规定的格式。当然如果你第一个参数没有规定格式,那scanf就默认是用回车分隔abc三个变量的。
C++用的是cin是iostream类的一个实例,程序运行到B2时也是会停止在控制台等待用户输入,默认用回车分隔用户的输入内容。
其中>> 是流提取运算符。C++ 编译器会根据要输入值的数据类型,选择合适的流提取运算符来提取值,并把它存储在给定的变量中。所以使用C++的输入输出,你就不需要老考虑使用哪个占位符了,这就方便了很多!
我们再看输出:
一个用的是printf,一个用的是cout。printf函数也用到占位符;cout用到<<流插入运算符。
C++ 编译器会根据要输出变量的数据类型,选择合适的流插入运算符来显示值。流插入运算符 << 被重载来输出内置类型(整型、浮点型、double 型、字符串和指针)的数据项。
endl表示换行符。
最后看看占位符:
占位符是一种有特定作用的符号,用于在格式化字符串中占住一个固定的位置,之后填充。占位符也分为输入占位符和输出占位符。
输入占位符的一般格式为:%[*][输入数据宽度][长度]类型, 其中有方括号[]的项为非必选项
输入占位符中[*]表示该输入项读入后不赋予相应的变量,即跳过该输入值。
输出占位符的一般格式为:%[标志][输出最小宽度][.精度][长度]类型, 其中有方括号[]的项为非必选项
输出占位符中[.精度]表示如果输出数字,则表示小数的位数;如果输出的是字符,则表示输出字符的个数
下面举个小例子: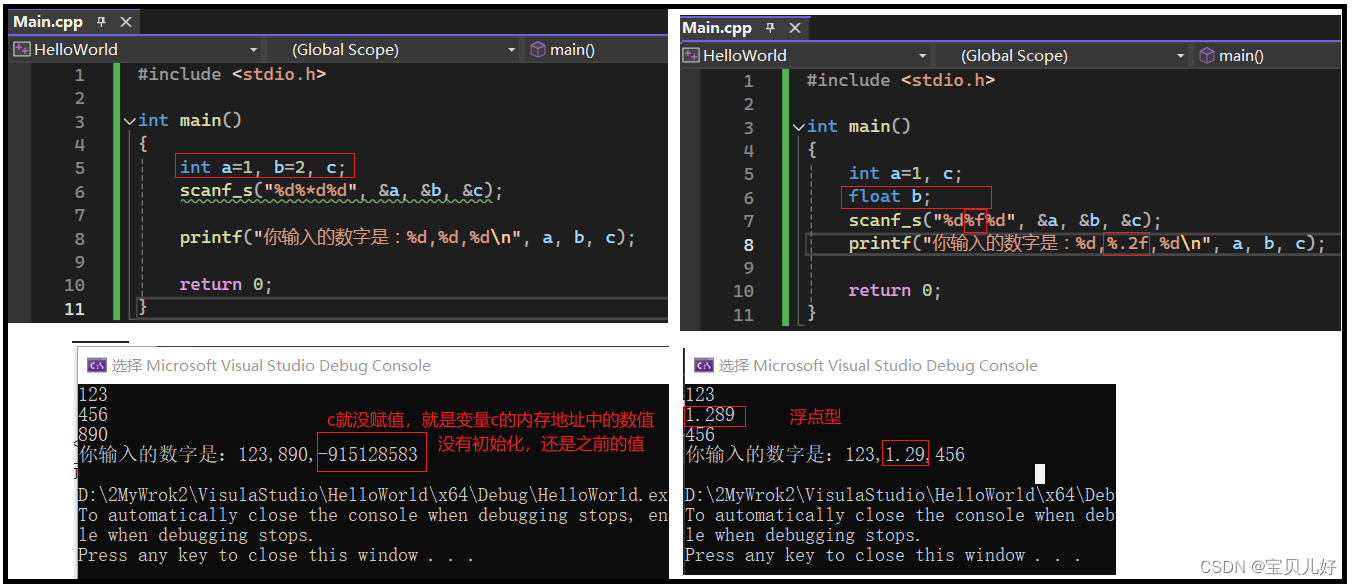
(2)C++的输入输出功能
C++的输入输出功能是由输入输出流(iostream)库提供的。iostream是标准库的一部分。
输入输出流是一个类层次结构。
标准输入standard input与预定义的iostream对象cin绑定在一起。
标准输出standard output与预定义的iostream对象cout绑定在一起。
标准错误standard error与预定义的iostream对象cerr绑定在一起。
输出操作符<<用来将一个值导向到标准输出cout或者标准错误cerr上。
双字符序列"\n"表示换行符newline。这是显式的进行换行,还可以使用预定义的iostream操纵符endl。
操纵符endl是在iostream上执行的一个操作:在输出流中插入一个换行符,然后刷新输出缓冲区。
类似,输入操作符>>用来从标准输入读入一个值
下面示例一个读取未知个数的输入值: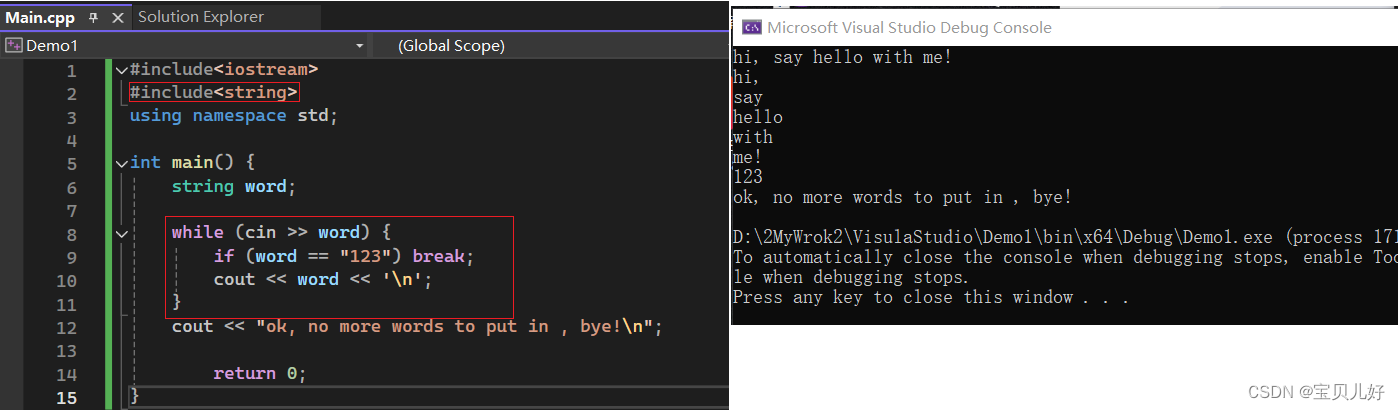
(3)文件的输入输出
示例:从origin.txt文件中读取数据,写入到input.txt文件中: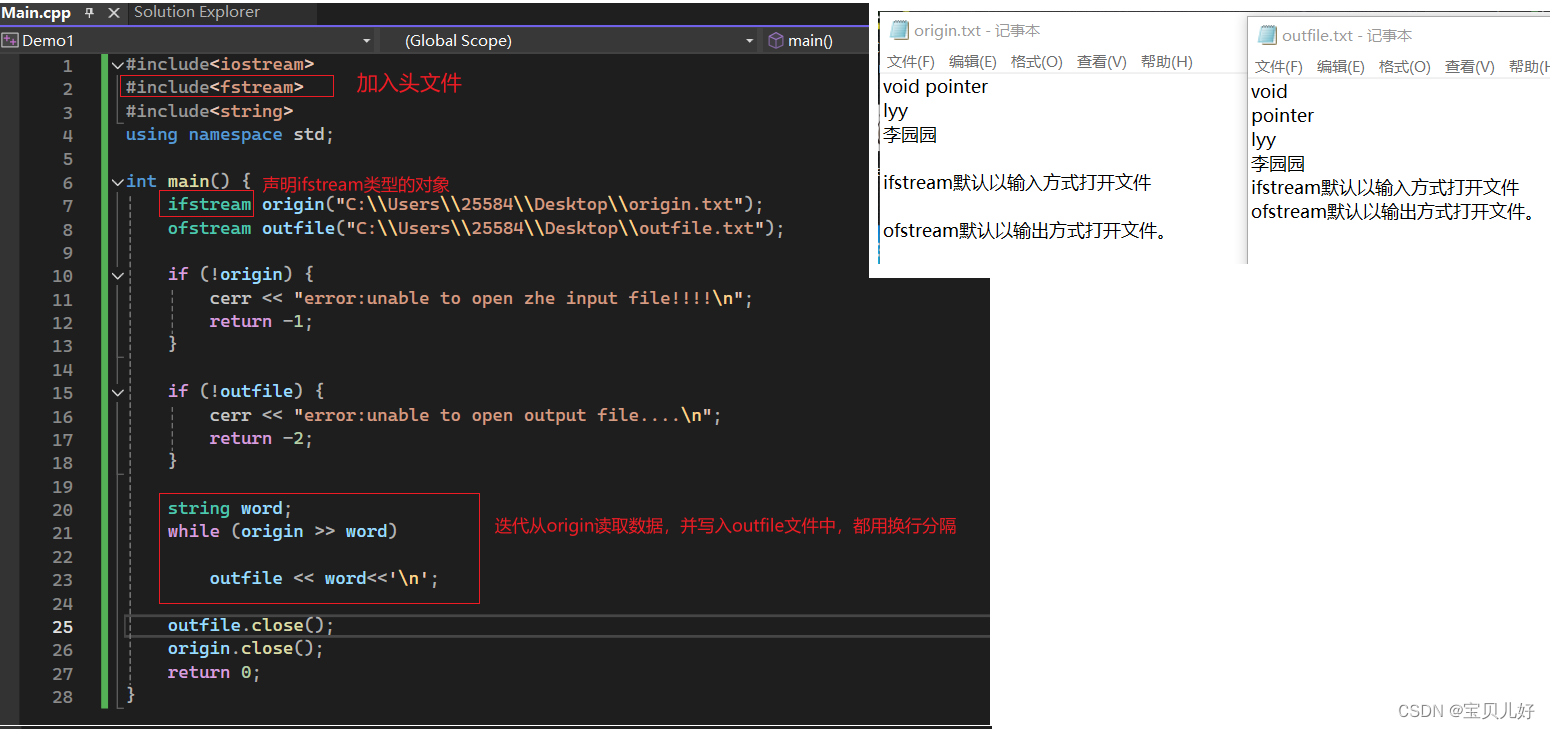
6、条件与分支
说明:本部分不讲条件语句本身,因为if语句本身是非常好理解的,就是if条件成立就执行下面的代码块,if条件不成立就跳过,这些条件语句我在C语言系列有详细的讲解,不明白的同学可以翻看那部分。这里我主要是深挖一下条件语句底层的实现逻辑:
几个概念:条件语句conditioan、if语句、分支语句branch
我们写if语句时,是先对实际condition(条件语句)进行评估,然后才是基于评估后的branch(分支语句)。
当我们开始一个应用程序时,整个应用程序及其所有模块加载到内存中。所以这些所有的指令组成了我们的程序,而且都被存储在内存中。当程序中有很多条件语句所产生的分支,基本上就是告诉cpu跳到这部分执行,再跳到那部分执行。这种在内存中跳来跳去的执行,实际上其过程是非常复杂的。比如cpu得先检查条件,然后跳到内存的不同地方,然后从那里开始执行指令。这意味着if语句和分支通常有比较大的开销。如果你想让你的代码快,最好少使用if语句。实际上很多优化的代码其实是特意避开分支的,是特意避免使用if语句。
下面我们看看一个分支的运行过程: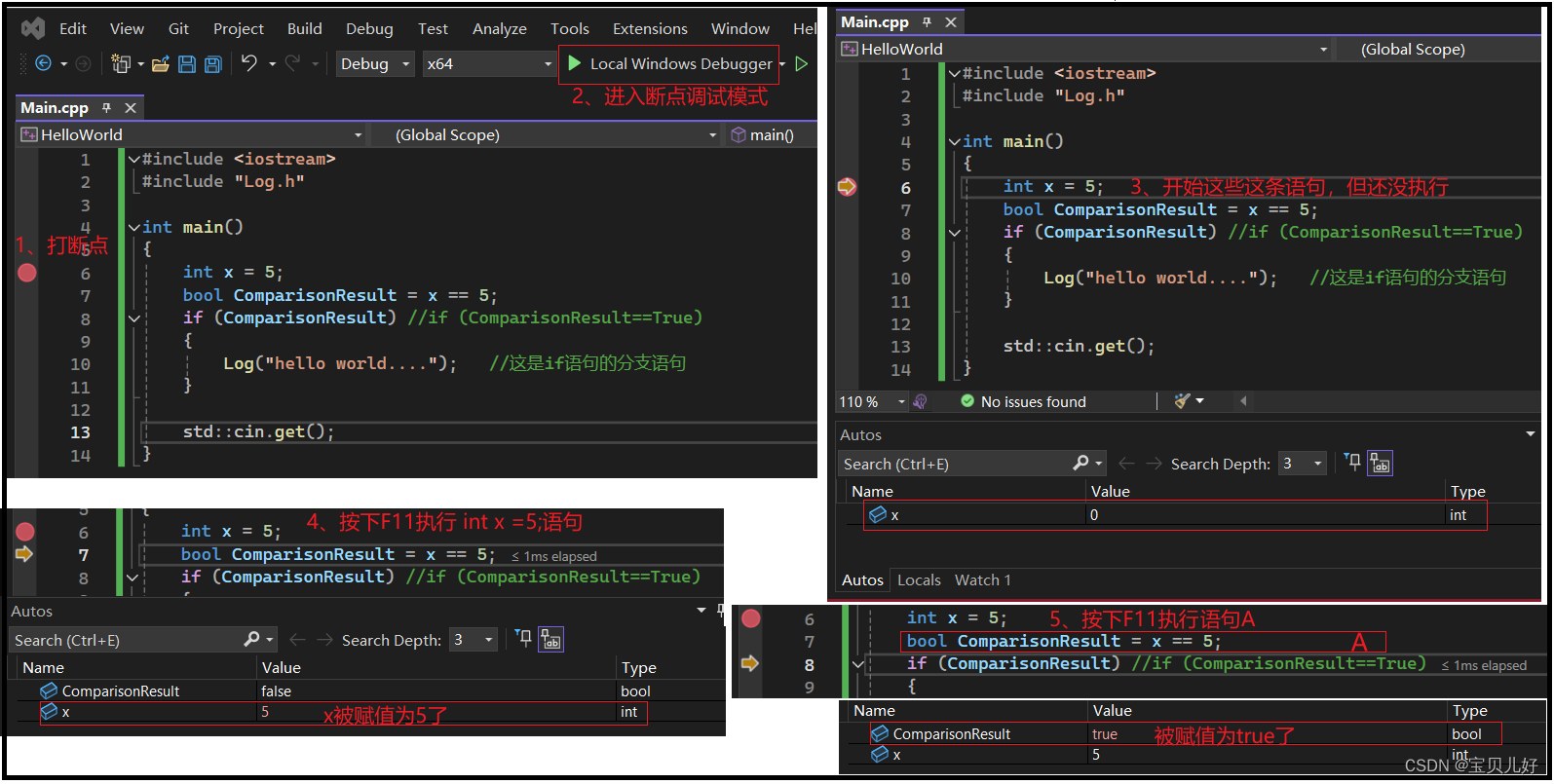
A:==是equality运算符, ==能工作是因这个运算符在C++标准库中被重载了。直白点说,就是C++标准库中有一个equality函数,这个函数接受两个整数参数,这个函数的功能是检查这个两个整数参数的内存(就是取这两个参数的四个字节的内存,前面不是说过整数一般都是4个字节嘛)以确保它们是相等的(就是比较这个两个4个字节的每一位,就是总共32位,看看这32位,是否每一位都是相等的,只有32位全部相等才相等),如果相等返回true,不相等返回false。
同理,你在C和C++中看到的所有的这些操作符都一个道理,都是在标准库中有确定的应用方式。
这里是先执行x==5,也就是先检验x是否等于5,如果x等于5就返回true,否则返回false
下面我们再通过反汇编视图(disassembly视图),看看编译器实际生成的if语句的汇编代码: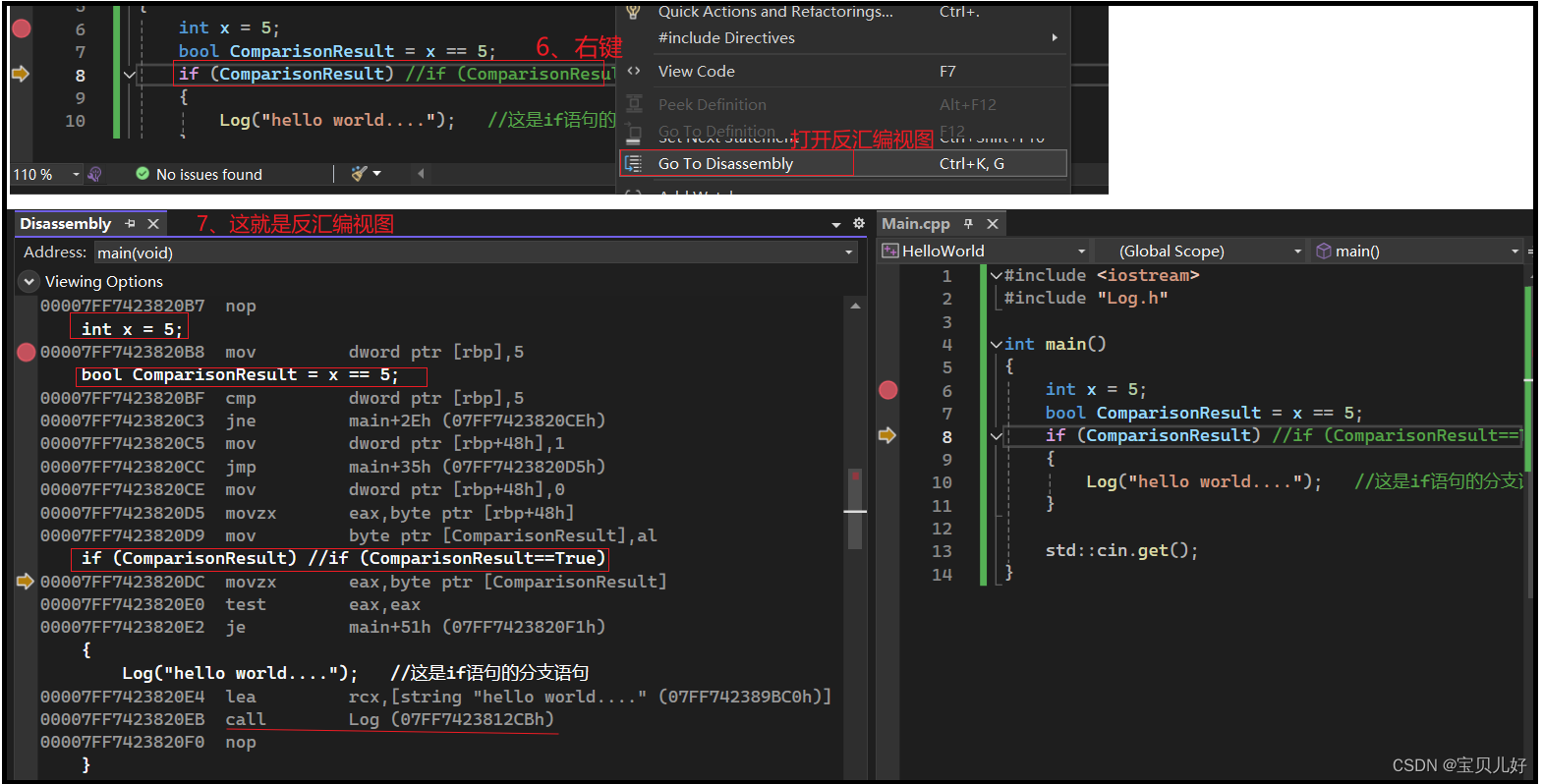
这里汇编代码我可能讲不了,就说几个点吧:
cmp:comparasion
jne:jump not equal
mov:move
je:jump equal 条件跳跃
(1)我们前面说过bool类型占用的是一个字节(byte),但是一个字节里面有8位(bit),而bool只需要1位就可以表示了,那编译器如何在一个byte中寻找那个bit的呢?结论是:只要这8位中有一位是1,那就是true;如果8位全部为0才是false。
(2)if汇编语句中第一行就是将变量ComparisonResult的值加载到寄存器eax。
第二行test是测试条件,看eax寄存器是否是能通过条件,就是是否是true,就是是否有1。也就是对这两个寄存器进行逻辑与计算。
逻辑计算完毕后开始执行第三行je,je是条件跳跃,如果test的结果是True,就一行一行往后继续执行,后面就是Log函数;如果test的结果是false,就是跳转到后面的地址执行。
(3)上面的反汇编视图是我们在调试(debug)模式下的汇编代码,所以编译器实际上是一点都没有优化我们的代码,所以我们可以回头看代码的运行机制。其实编译器在编译的时候是要进行优化的。
所谓优化,实质上是对代码进行等价变换,使得变换后的代码运行结果与变换前的代码运行结果相同,而运行速度加快或占用存储空间减少,或两者都有。
具体我们这里的if语句,编译器其实在if语句前都已经知道if语句中的条件是否成立,因为前面不是有int x = 5嘛,编译器都知道变量x的值是5,所以x等不等于5,编译器是知道的,所以bool变量ComparisonResult是0还是1,编译器也是知道的。所以在实际的编译过程中,编译器直接把if(false)下面的代码块直接就删除了。这点我们在讲编译预处理部分的时候也讲过。而不需要程序已经到执行阶段了,再去比较x等不到5,ComparisonResult是true还是false。
那预编译阶段,编译器是如何做到比较的呢?我们知道两个整数相等还是不相等,就是所谓的常数折叠,就是编译器其实在执行int x=5时,并不是给变量x分配一个首地址+4个字节的长度,而是把x = 5保存到符号表里,在用到x时,会根据符号表把x替换成1。同理,编译器再执行bool ComparisonResult = x == 5;时,也不会给变量ComparisonResult分配一个自己去存储0或1,也是保存在符号表中。也所以预编译阶段编译器就知道x和5的比较结果了,也就是ComparisonResult的值了。所以预编译阶段if语句中的不符合条件的分支代码块就已经被直接删掉了。if后面跟的分支语句都是满足if条件需要执行的语句,这样就减少程序执行过程中的计算量了。
所以如果我们想调试自己的程序时,你尽量关闭所有的优化,最好就是处于debug模式下。
(4)if语句的写法
也所以我们上面例子中的if语句只要写if(ComparisonResult)即可,其实是不用写if(ComparisonResult==true)或if(ComparisonResult==1)。而且即使如果你这样写了,编译器也不会给你真正编译成,让你再去调用标准库中equality函数,再去对比一下ComparisonResult和1是否相等这个操作。
也所以,上面的代码你还可以简写成下图1的形式: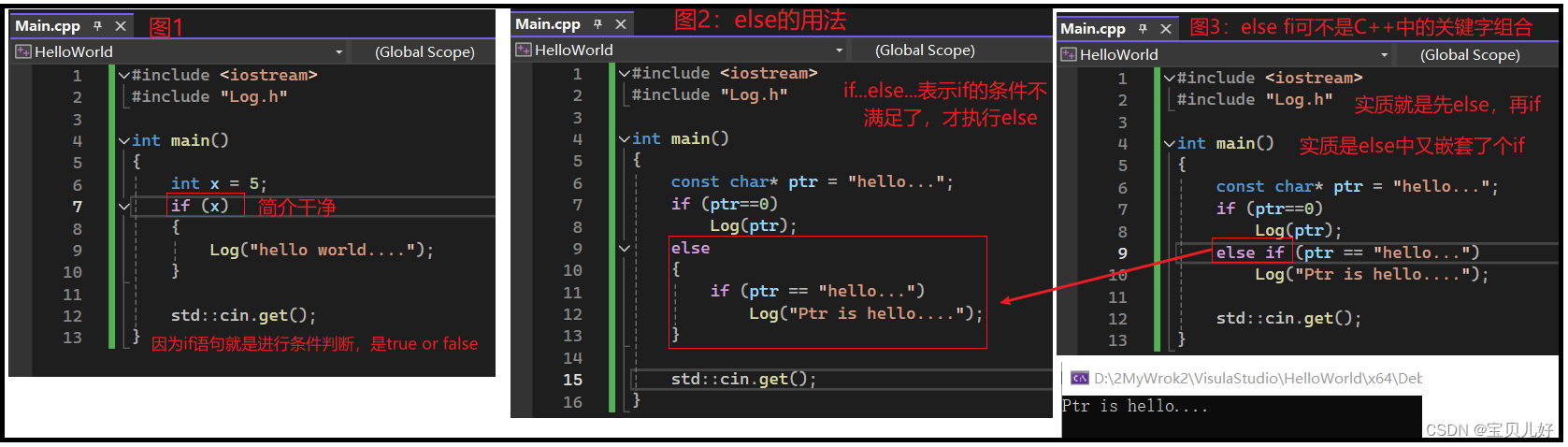
7、VS项目设置
在Visual Studio我们创建项目的步骤如下: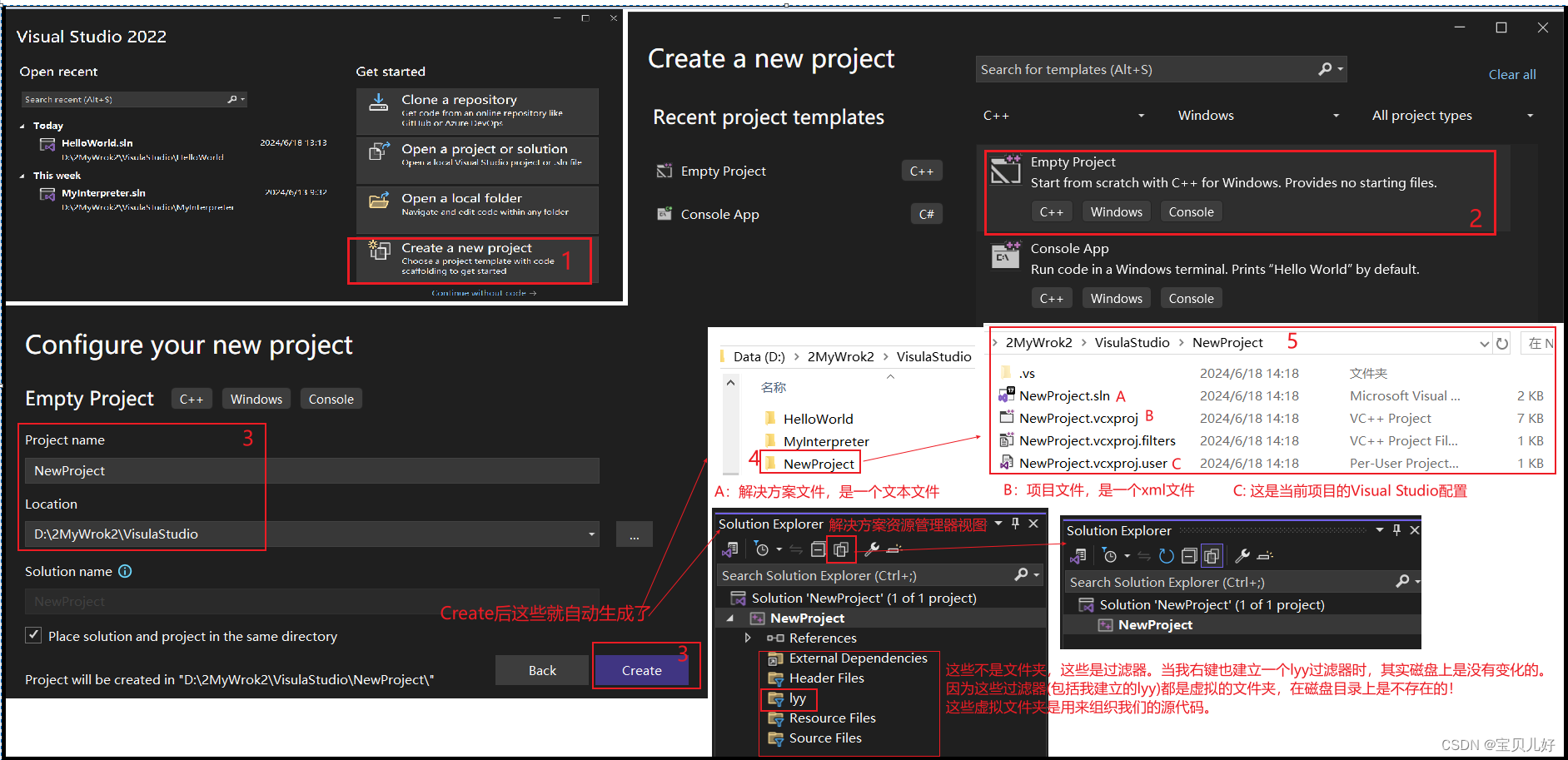

但是Visual Studio的这种项目组织方式不是很合理。项目组织就是设置你的各种文件目录。一个清晰明了的目录可以使你的项目一目了然。我们通常的做法是:创建一个名为Source或者src的文件夹,这个文件夹包含我们所有的源代码、头文件等东西,这样可以使我们的项目文件和可能使用到的任何其他资源,能够被很好的分开在不同的文件夹中。下面我们更改这种组织方式:
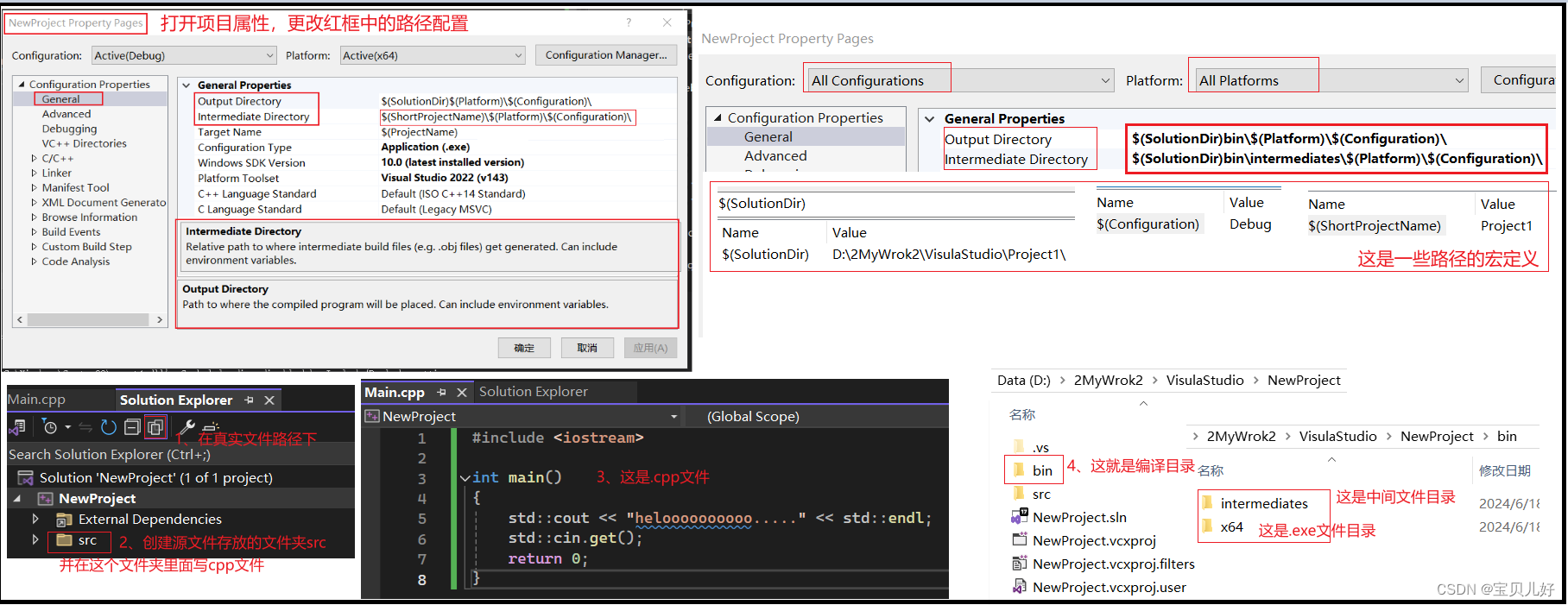

工必善必先利其器,这里先介绍一下VS的设置,以后我们还会讲到编译器设置、链接设置、release模式优化设置等。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









