






一、一个极简但完整的C++程序
我们编写程序是为了解决问题和任务的。
1、任务:
某个书店将每本售出的图书的书名和出版社,输入到一个文件中,这些信息以书售出的时间顺序输入,每两周店主会手工计算每本书的销售量、以及每个出版社的销售量。报表以出版社名称的字母顺序排序,以便下订单进货,填补已经卖出去的书。
现在我们写一个程序来完成这个任务。
2、分解任务
将复杂问题分解成一个个容易实现的小问题。分而治之divide and conquer, 逐步求精stepwise refinement。
上面书店任务分成以下4个子任务:
(1)读取销售文件;
(2)根据书名和出版社名称计算销售量
(3)以出版社名称对书名进行排序
(4)输出结果
子问题3还是太复杂,继续分隔任务:
(1)读取销售文件;
(2)根据书名和出版社名称计算销售量
(3a)按出版社排序 (3b)对每个出版社的书,按书名排序 (3c)在每个出版社组中,比较相邻的书名,如果二者匹配,增加第一个的数量,删除第二个。
(4)输出结果
子问题脉络不清,继续整理动作序列:
(1)读取销售文件;
(2)对文件排序————先按出版社,然后在出版社内部按书名排序;
(3)压缩重复的书名;
(4)将结果写入文件;
这个动作序列就是算法algorithm,下面就是把这个算法转化为C++语言的程序。
3、编写程序
(1)C++语句 
在C++语言中,操作数operand + 操作符operator = 表达式expression。也就是动作被称为表达式。
以分号结尾的表达式称为语句statement。语句是C++中最小的程序单元。上述代码就是3条语句。
语句A:是一个声明语句declaration。
book_count是标识符identifier或者叫符号变量symbolic variable,简称变量variable,或者对象object。都是指计算机内存中的一块区域,这块区域是存储整数值的,这块区域与变量名book_count相关联。认真看过编译原理的同学就知道,变量名其实是给程序员看的,程序编译的时候,变量名直接被编译器映射成首地址和长度(长度是从变量的类型上看到的,比如上面的int类型)。
0是文字常量literal constant,表示变量book_count被初始化为0。
语句B:是一个赋值语句assignment。作用就是把变量books_on_shelf和变量books_on_order的值相加,并把结果写入变量book_count的内存区域中。当然前提是books_on_shelf和books_on_order都已经被声明和初始化过了。
语句C:是一个输出语句output。作用是在用户终端先输出一个字符串,再输出与变量名book_count相关联的内存区域中的值。
cout是用户终端;<<是输出操作符。
(2)编写C++程序
把上述语句按逻辑语义分组,就形成一些有名字的单元,这些单元称为函数function。
每个程序都是由一系列函数组成的。那照葫芦画瓢,我们把书店任务子任务(1)读取销售文件的实现语句都组织到一个称为readIn()的函数中。其他任务同理分别组织到:sortBook()、compactBook()、printBook()函数。
在C++中,每个程序必须有一个main()函数,程序才能运行。因为main函数是一个程序的入口(当然你也可以设置其他入口,但每必要)。这个main函数是由程序员写的。
一个程序是不可能一下子从头到尾一口气写出来的,都是渐进式一点点添加完成的,所以下面我们先用哑函数来实现这个书店的任务,也就是先把程序代码的整体大块写出来: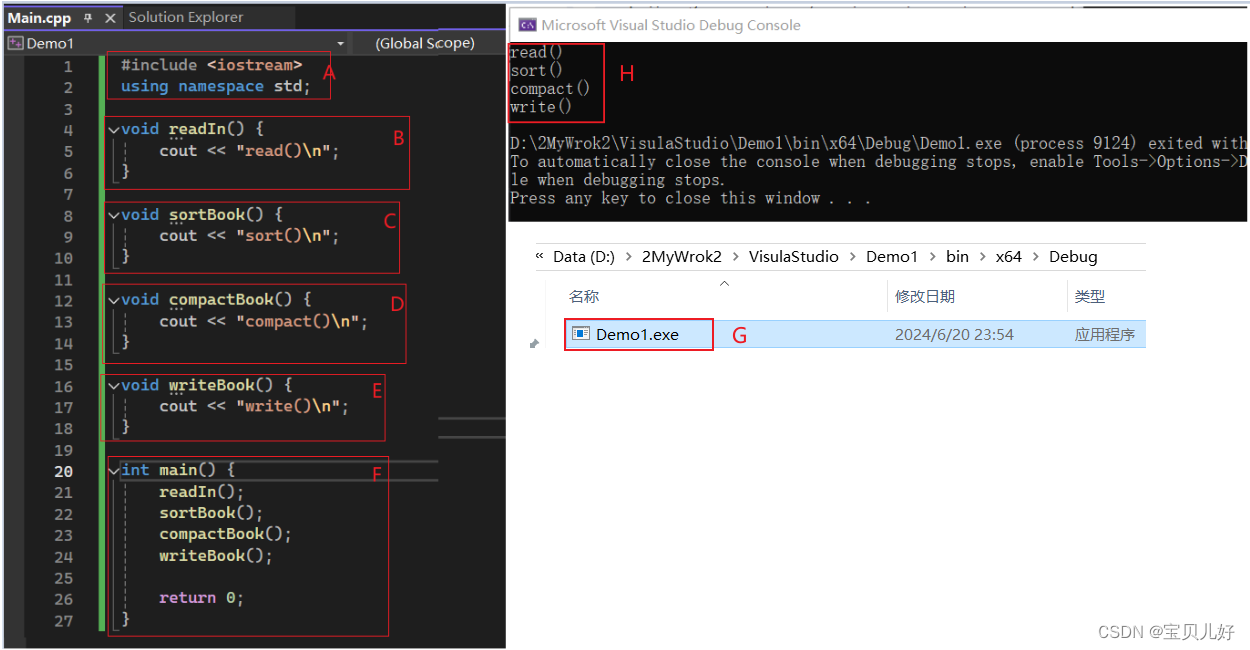
解释:
a、上图ABCDEF都是函数。通常函数由四部分组成:返回类型、函数名、参数表、函数体。
void表示该函数没有返回值。int表示函数返回值是整数类型。
参数表由小括号括起来。多个参数由逗号分开。
函数体由花括号括起来。函数体由多个程序语句序列构成。
b、上图F函数是main函数,main函数是一个程序的入口。也就是说这个程序是从main函数开始执行的,然后是从上往下依次执行的,除非遇到条件语句、分支语句、控制流语句等才会跳出执行,跳出执行完毕后,继续回到原来位置继续往下执行。
return 是C++预定义的语句,作用是终止函数的执行。return 后面的值是函数的返回值return value。在C++标准中,如果main函数没有显示的提供返回语句,则默认返回0。
c、上例中,函数BCDE都是定义函数。main函数里面的才是函数调用。当开始执行main函数时,main函数体先调用invoke函数(这部分在编译时讲过),然后才是readIn,sortBook,依次往后,执行到return 0;后,程序正常结束。
d、include是预处理器指示符preprocessor include directive,预处理器指示符用#号 标识。作用是复制iostream文件中的内容到本文本文件中,这是预处理器的作用,预处理器又是捆绑在编译器中。
iostream是输入输出流库标准文件,文件中就包括比如cout的信息。但是类似cout这样的关键字不是你可以直接在代码文本中使用的,你还得加上using namespace std;语句才可以直接使用。
这条语句被称为using指示符using directive。C++标准库中的名字都是在一个叫std的名字空间中声明的。using指示符告诉编译器要使用在名字空间std中声明的名字。
4、编译程序
当我们的文本程序文件————.cpp文件中的代码编写完毕后,就改执行这个.cpp文件,看它是否可以帮我我们完成书店的任务。
代码是人类认识的文本,计算机cpu只认识0和1,所以代码到执行中间还有很长的路,这个路就是编译。
编译也是一个非常非常复杂的过程,建议大家先看:【C++】编译原理-CSDN博客
这里我就简单说一些流程就好了。
(1)编辑-编译-调试 edit-compile-debug
在程序编译阶段,一般情况下,都会报出bug,就是我们写的程序计算机理解不了,编译器都会报出来,比如你的代码犯了语法错误、类型错误等,编译器就会报错,此时你首先要明白,既然报错就一定是你代码的错,不可能是计算机的错,所以要改的是你的代码。然后你就进入编辑-编译-调试这个循环过程,直到顺利编译完毕,没有bug为止。
(2)代码生成code generation
当编译成功后,也就是你的代码被编译器成功转化为目标代码或汇编指令代码,这些代码是cpu理解的代码。而你编译成功的结果一般是生成一个.exe的可执行文件,如上图的G。
5、执行程序
双击运行G这个可执行文件,就是上图的H。
如果H的运行结果符合我们的要求,比如正确统计出来并显示,那就任务完成。上图的结果H显然不是我们想要的结果,哈哈,那是因为的的代码还没开始写,我们用的是哑函数,这里主要展示项目开发的流程,实际功能就根本没开始写呢。下面我们开始慢慢补充。
6、补充1
我们先不补充这几个函数,我们补充一种情况:比如如果销售很慢,比如这两周店主卖出了0本,或者只卖出了1本。当卖出0本时,我们也要给店主回复个没有销售记录的提示。当卖出1本时,我们就不必要排序和压缩了。当然如果卖出了2本或2本以上,那就走正常流程了。我们先用if语句实现这种情况,代码如下:
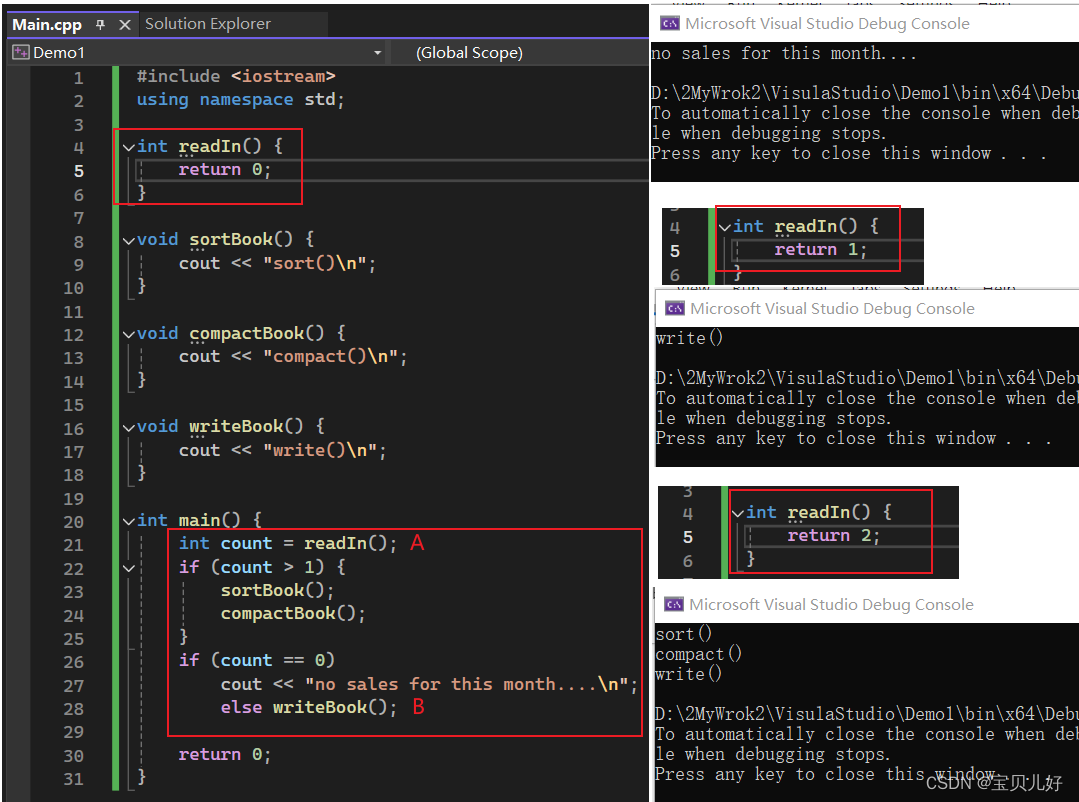
(1)此时就得修改readIn函数的返回值,我们根据readIn函数的返回值决定程序该如何执行。
(2)修改main函数。首先是获取readIn函数的返回值,代码A,用一个整型变量count接受readIn函数的返回值。
如果readIn函数返回值count大于1,就是卖出了2本或者2本以上,那我们正常执行,就是继续执行排序、压缩。
如果readIn函数返回值count等于0,就是没有销售,返回一个字符串“no sales this nonth...”
如果readIn函数返回值count不等于0,就执行else语句,也就是B语句,就是调用writeBook函数。
暂时先补充这一个逻辑,后面我们学到相关的知识点在继续补充。















 652
652

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









