






一、Transformer是什么
Transformer是一种深度学习模型架构,最初由Google的研究团队在2017年提出。这种架构最早用于自然语言处理(NLP),但后来也在其他领域表现出色。Transformer的关键特点是其自注意力机制(Self-Attention Mechanism),它允许模型在处理数据时考虑输入序列的不同部分之间的关系。
简单点可以认为:Transformer = self-attention+encoder+decoder
例如GPT就用到了Transformer,GPT全称Generative Pre-trained Transformer。
Generative:即用来生成新文本的机器人
Pre-trained:“预训练”指的是模型经历了从大量数据中学习的过程
“预”字则暗示 模型能针对具体任务 通过额外训练来进行微调
Transformer:是一种特殊的神经网络,一种机器学习模型,它是当今AI热潮的核心发明。
二、Transformer特点
自注意力机制:Transformer通过自注意力机制来捕捉输入序列中各个位置之间的依赖关系,而不依赖于序列的顺序。这样做使得模型能够并行处理数据,提高了训练效率。
编码器-解码器结构:标准的Transformer模型包含两个主要部分:编码器和解码器。编码器负责处理输入数据,解码器生成输出数据。编码器和解码器由多个层堆叠而成。
位置编码:由于Transformer模型本身不考虑序列的顺序,因此需要引入位置编码来为模型提供序列中元素的位置信息。
三、Transformer应用领域
自然语言处理(NLP):Transformer在NLP任务中表现非常出色,如机器翻译(例如BERT、GPT系列)、文本生成、文本分类、情感分析等。
计算机视觉:Transformer模型也被应用于图像处理任务,例如图像分类和目标检测(例如Vision Transformer,ViT)。
时间序列分析:Transformer可以用于处理时间序列数据,如金融预测和气象预测等。
语音处理:用于语音识别和语音生成等任务。
四、理解Transformer
Transformer 首次出现于2017年的的一篇著名论文《Attention Is All You Need》,截止至2024年7月24日晚10点,被引12w+

论文最初将Transformer架构用于机器翻译。

Transformer将注意力模块和多层感知模块层层堆叠
许多视频或论文里会看到Feed Forward Network层,其实Feed Forward Network 就是一个MLP,多层感知机


当然,Transformer有多种应用场景,如语音转文本

文本转语音

文本转图像等等

然而,GPT就是做预测的,给出一个开头,不断重复预测下一个出现的单词,例如:

我特别喜欢的一种功能是能看到它在选取每个新词时,背后的概率分布。
机器学习都是数据驱动的,就是学习参数,拟合我们希望的结果,GPT-3的参数多达1750亿个。

五、从公式原理出发,理解self-attention
李弘毅老师的课程讲的很好很好,建议大家看一下。
视频网址:https://www.bilibili.com/video/BV1J441137V6/?spm_id_from=333.337.search-card.all.click&vd_source=ea5c910bfe0c11f0edf9f3a8da1dd52a
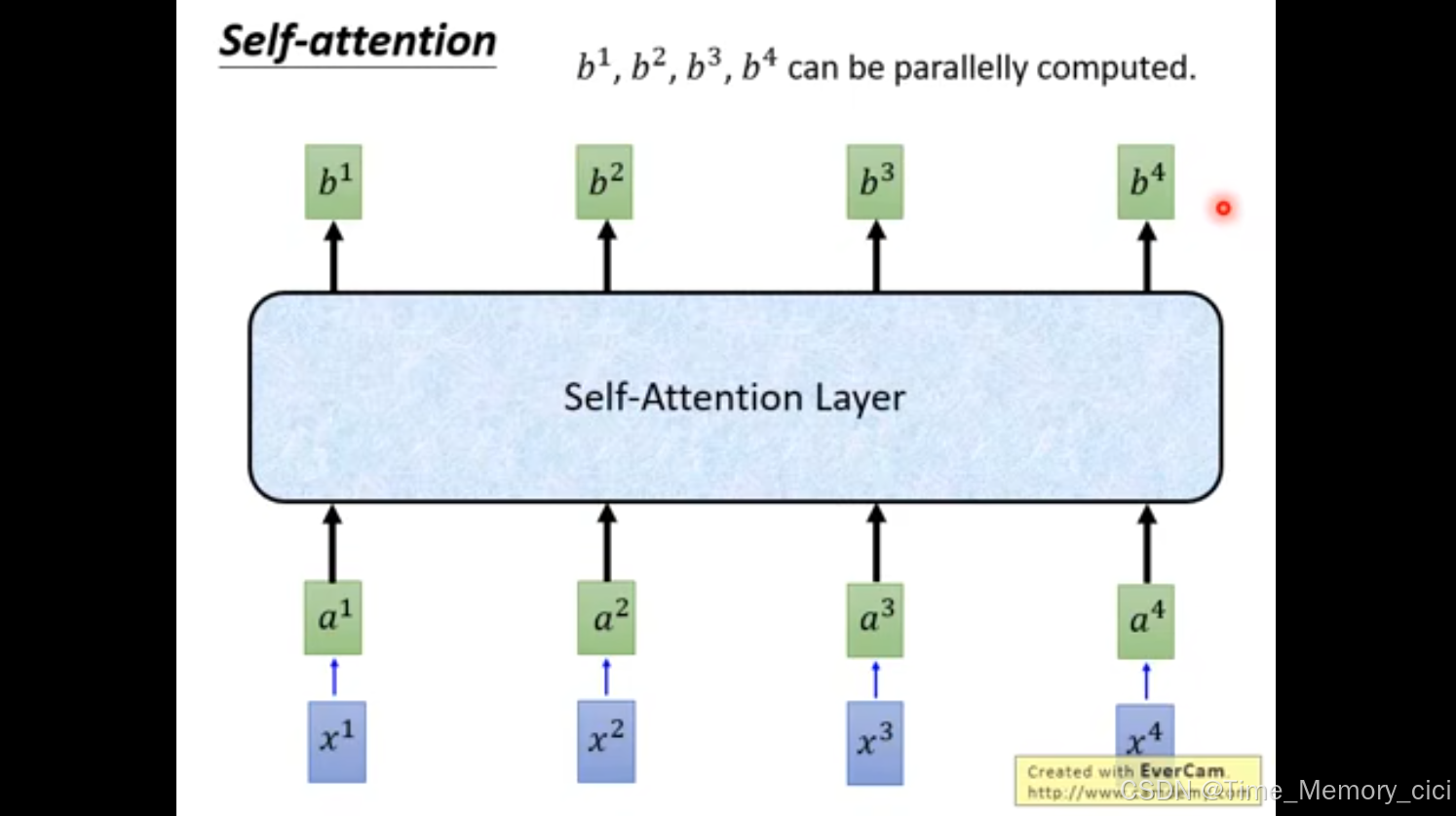
1、输入x1、x2、x3、x4先通过变换,转换为a1、a2、a3、a4形式的embedding vector。
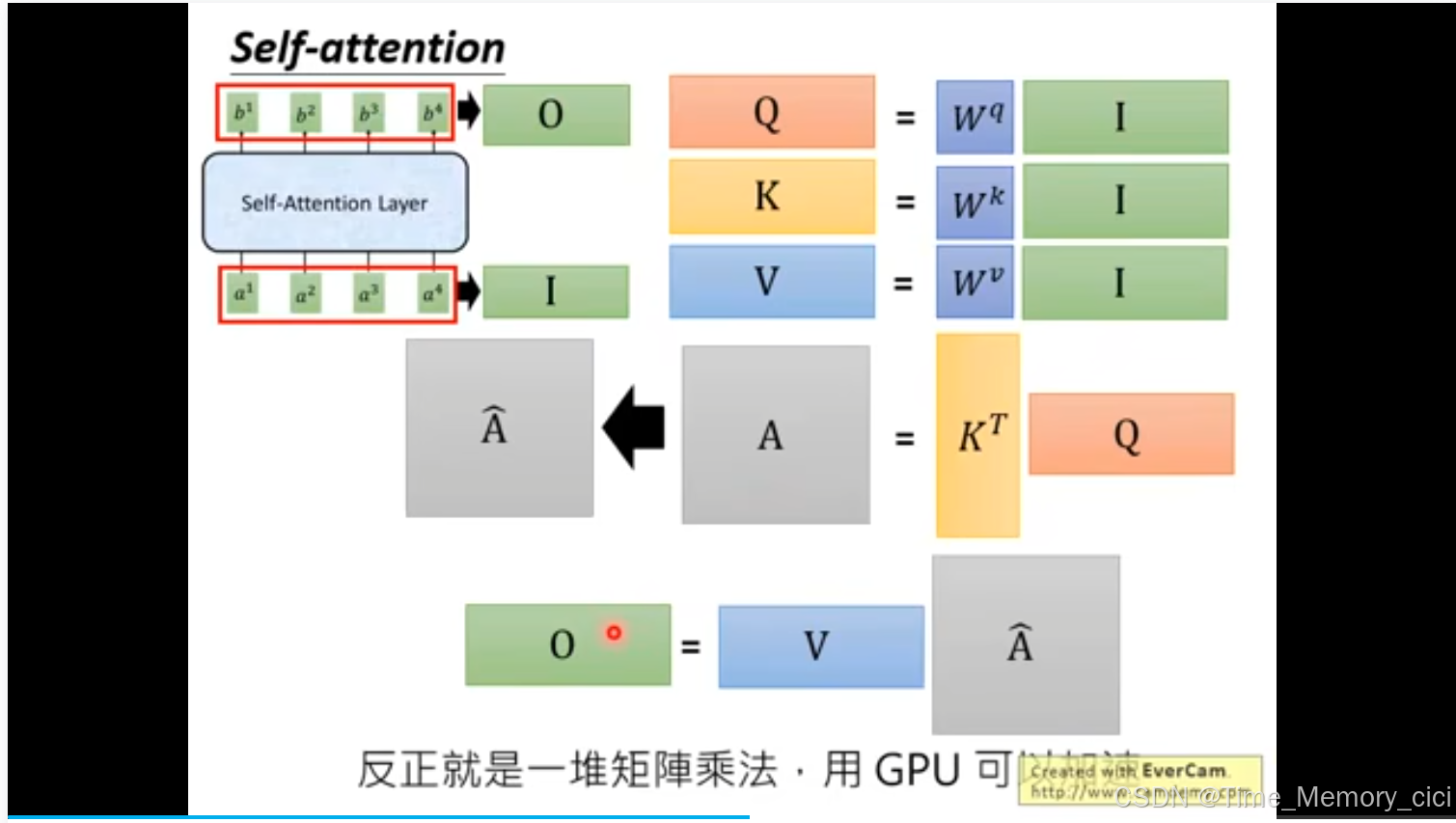
2、然后求q、k、v,方法是a1乘以对应的矩阵
3、求scaled dot-product attention,如下图公式,q和每个k点乘,也就是做内积,然后除以根号d,其中d是q和k的维度。因为q和k能做内积,所以他俩的维度肯定是一样的,都为d。这里除以根号d的目的是,防止q和k的维度太大,导致所求的数值过大。
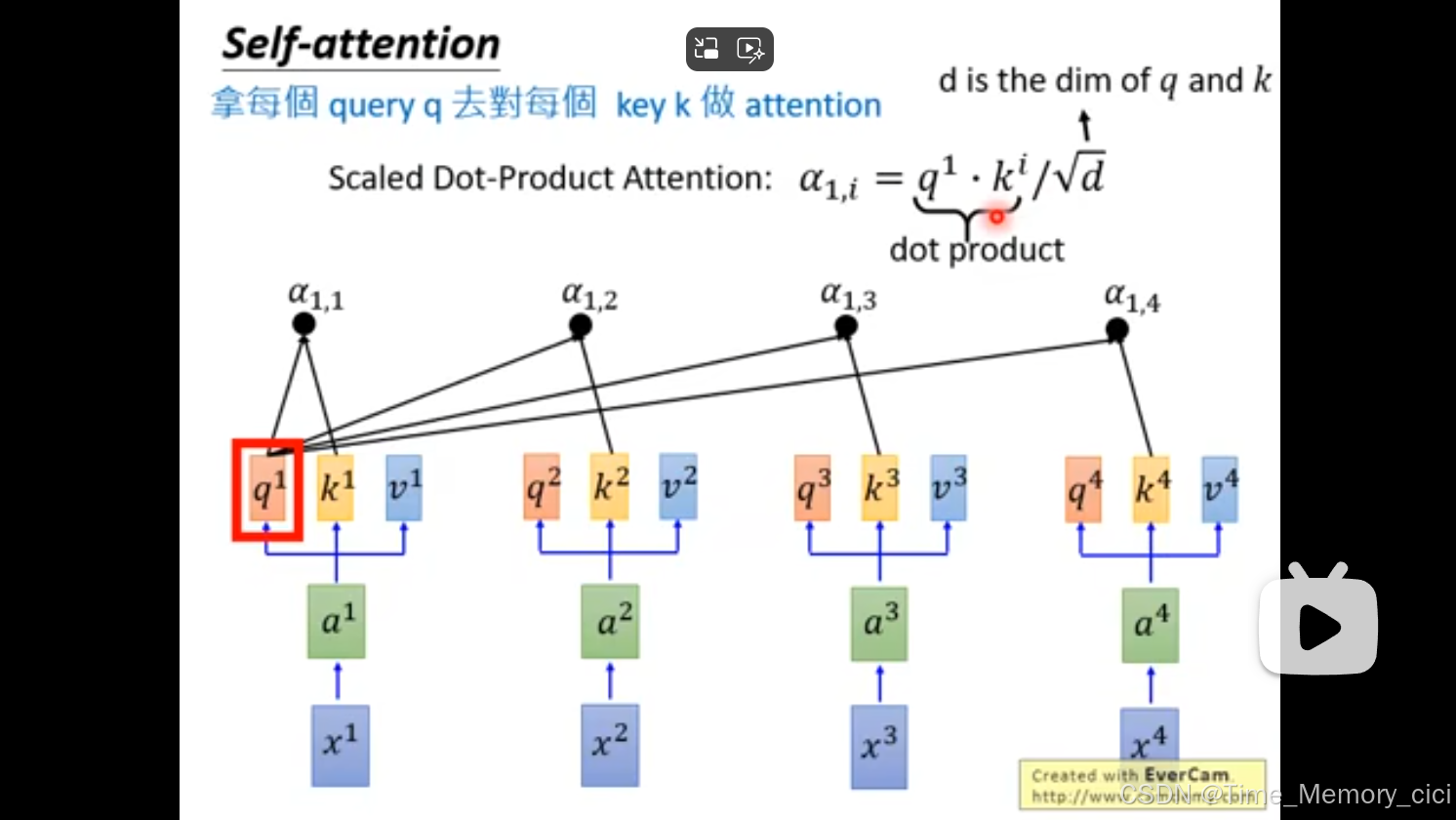
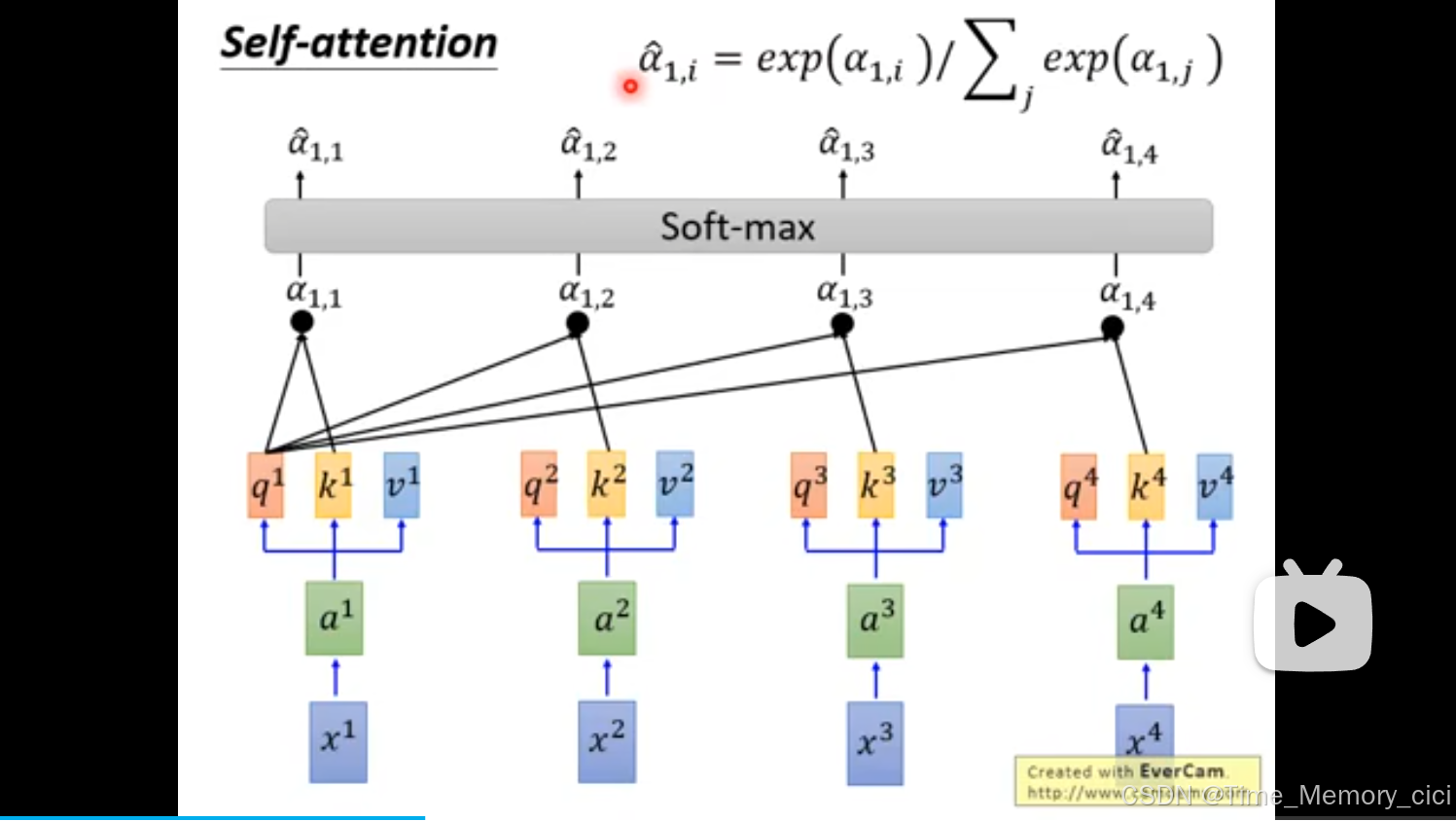
4、然后做soft-max处理。
5、利用v向量,求取b1,可以看到下面两张ppt,b1和b2可以并行计算。
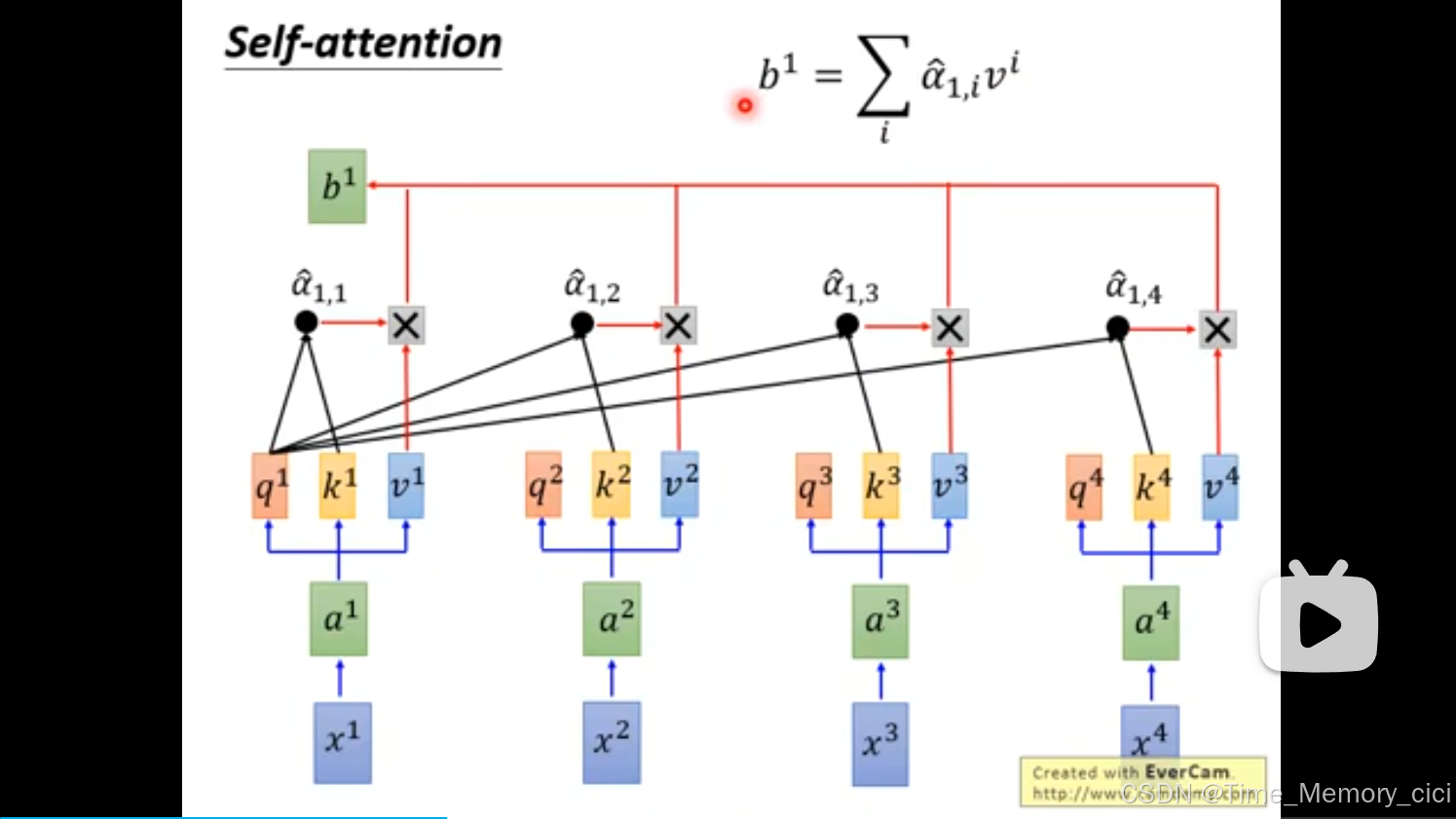
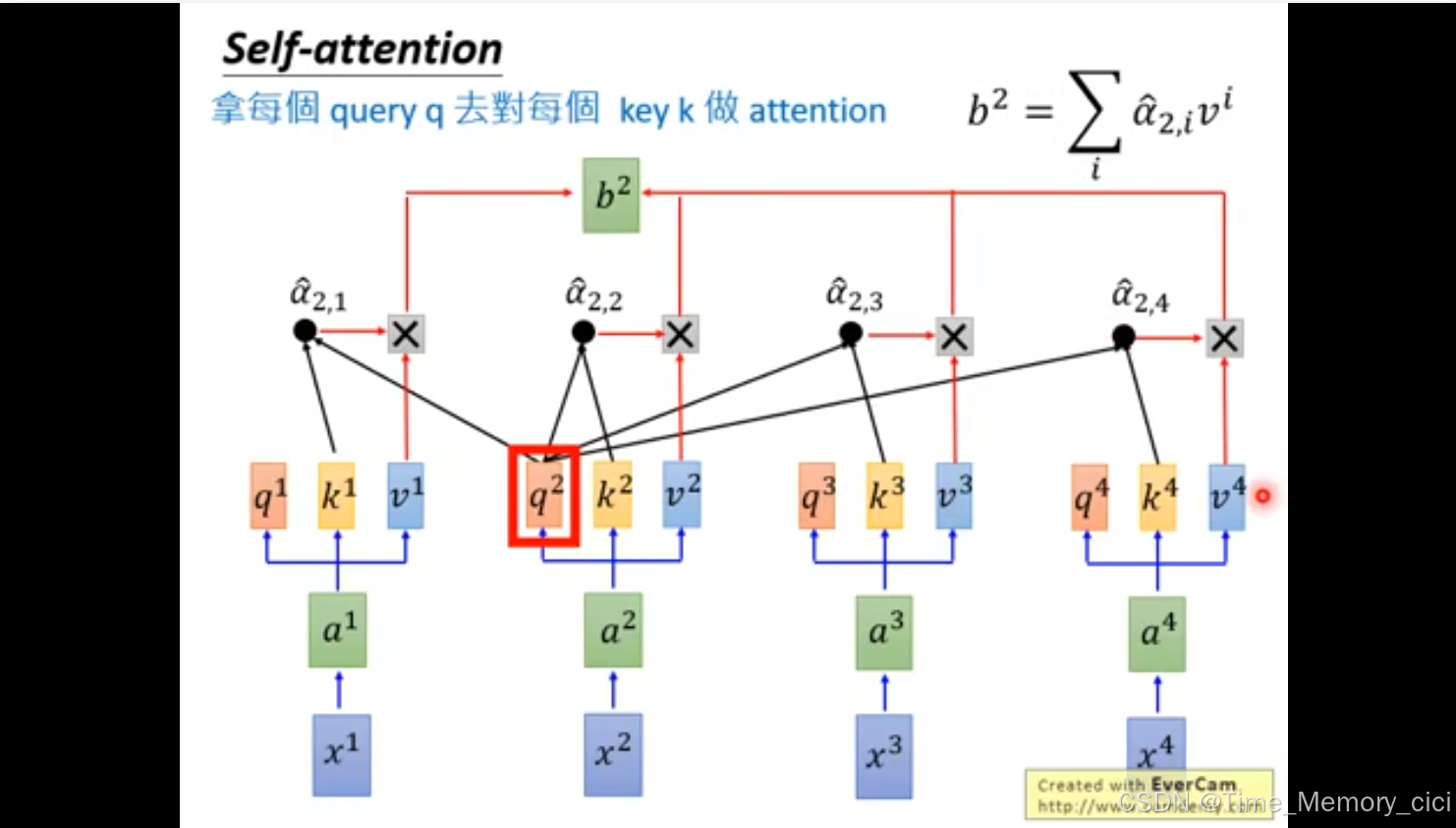
6、总之一句话,self-attention的作用是,输入一组i向量x1、x2、x3、x4,可以并行计算出另外一组向量b1、b2、b3、b4
六、小Tip
Transformer不需要复杂的RNN结构,完全基于自注意力机制。

知识来源于KnowingAI知智:https://www.bilibili.com/video/BV1Zz4y127h1/?spm_id_from=333.337.search-card.all.click&vd_source=ea5c910bfe0c11f0edf9f3a8da1dd52a
神奇的3Blue1Brown:https://www.bilibili.com/video/BV13z421U7cs/?spm_id_from=333.337.search-card.all.click&vd_source=ea5c910bfe0c11f0edf9f3a8da1dd52a


















 1151
1151

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









