







你是否还在为机器学习没有经典的数据集苦苦寻找?本文将为你介绍scikit-learn中的数据集及基本用法。
导入机器学习常用库numpy和matplot:
sklearn有很多数据集,我们先导入scikit-learn的数据集库,再导入鸢尾花数据集:
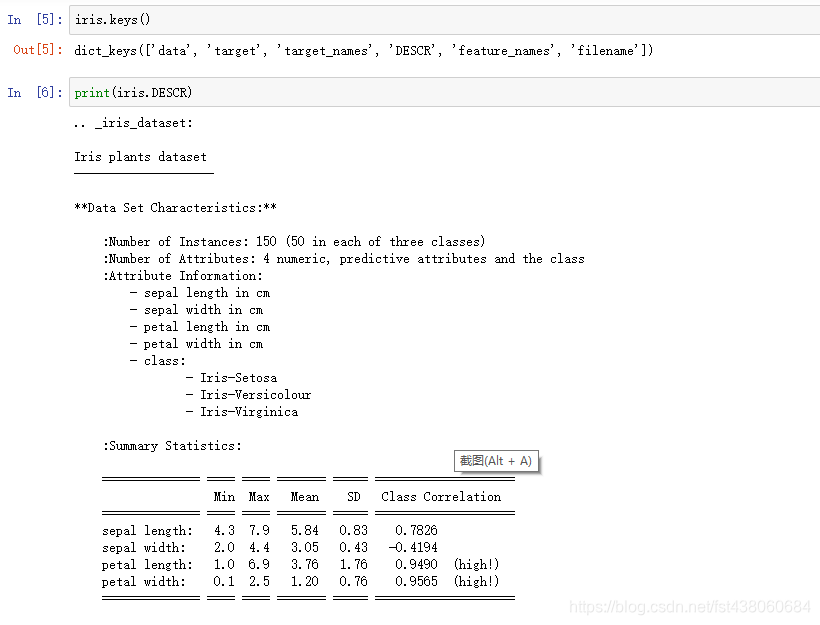
查看数据集里面有什么key,并且查看desc鸢尾花数据集的描述:
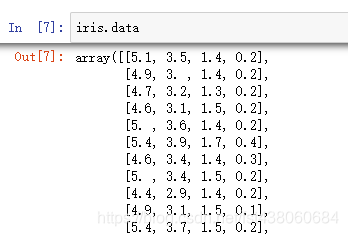
查看鸢尾花具体数据
查看数据集的shape和特征:
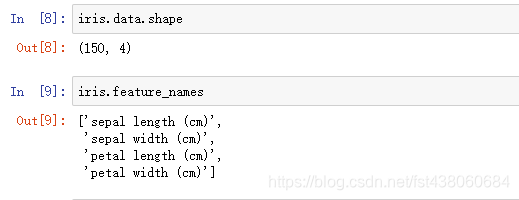
取分类结果数据:

所以我们可以看到,结果分三类,在数据里面表示为0、1、2,一共有150个样本。再结合上面的shape和特征,我们可以知道每个样本都有4个特征。
让我们开始使用数据,先通过fancy index的方式取前两个特征:
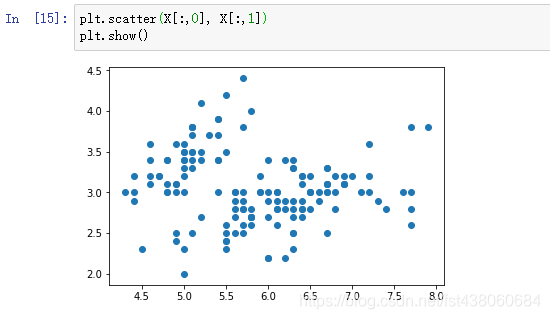
取两个特征的数据画散点图上:
把样本结果导入,并且取结果为0的数据,分别与0和1组合:
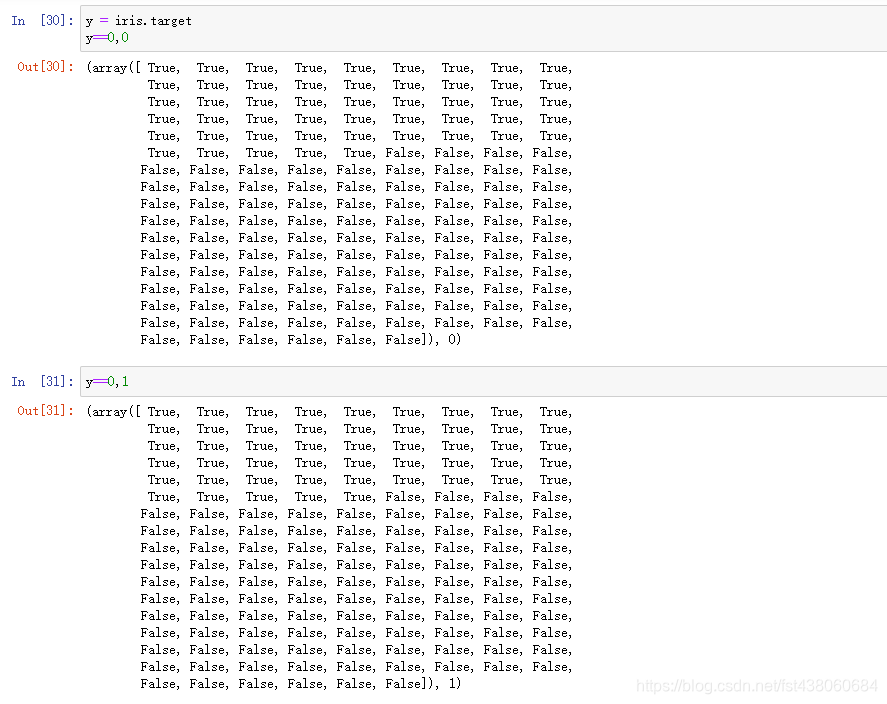
X[y==0,0]表示取样本结果为0的X的第一个特征;
X[y==0,1]表示取样本结果为0的X的第二个特征;
将不同的样本结果(0,1,2)的第一个特征和第二个特征分别绘制在散点图x轴y轴上,分别用不同的颜色和标记:
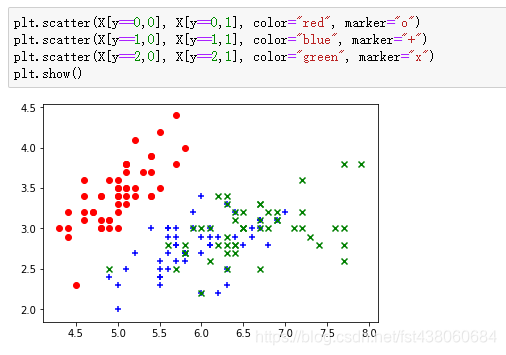
关于marker可以查看这里去了解更多
可以看到,2结果和3结果区分不是很清楚。
之前用的是第一个和第二个特征区分,我们可以用后面的两个第三第四特征区分,这样就比较清晰了:
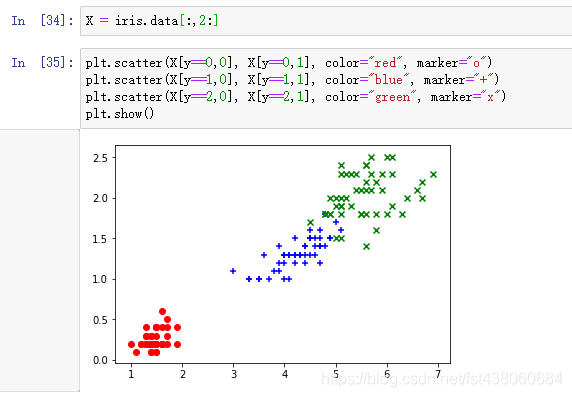
其他的数据集,大家可以自行到scikit-learn的官网查看















08-07
 186
186
186
01-20

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









