







 本文详细分析了三个C语言程序中的漏洞,涉及堆溢出、格式化字符串错误和缓冲区溢出。通过源码剖析,展示了如何构造payload利用这些漏洞,包括利用tfree的堆合并和snprintf的格式化字符串错误来修改内存,以及如何通过修改栈帧结构绕过exit函数获取shellcode。
本文详细分析了三个C语言程序中的漏洞,涉及堆溢出、格式化字符串错误和缓冲区溢出。通过源码剖析,展示了如何构造payload利用这些漏洞,包括利用tfree的堆合并和snprintf的格式化字符串错误来修改内存,以及如何通过修改栈帧结构绕过exit函数获取shellcode。
2.5 漏洞程序四
2.5.1 漏洞分析
1、源码及其依赖项分析
1.1 源码分析

由上述代码可见foo函数的执行逻辑顺序为:
p=tmalloc(500) à q=tmalloc(300) à tfree(p) à tfree(q) à p=tmalloc(1024) à tfree(q)
可知为q申请了一次内存但使用tfree了两次,由于申请的内存已经在第一次tfree,第二次tfree会释放一个不存在的空间,导致出错,该漏洞属于堆溢出漏洞。因此,tfree很可能是我们可以利用的地方。
1.2 库文件“tmalloc.h”对应“tmalloc.c”文件分析:
结构体与宏定义:

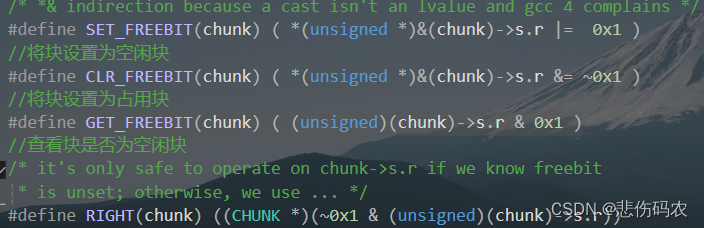
可见,CHUNK结构体占8个字节(前4个字节为左指针,后4个字节为右指针,分别指向前后的块位置)在块的r指针的低位部分存储块的状态,1为空闲,0为占用。
tmalloc函数和tfree函数:
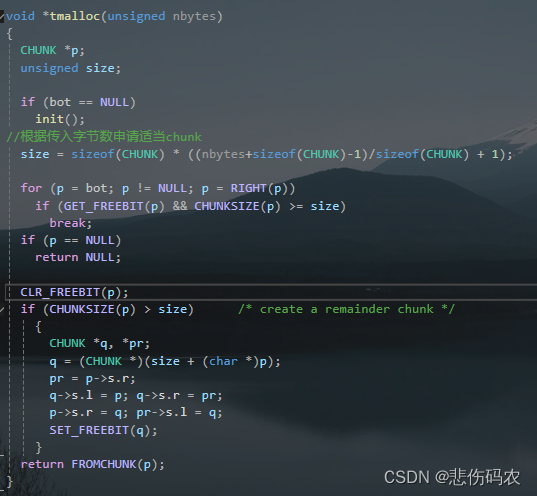
可以总结tmalloc函数的执行过程如下:
首先,tmalloc 函数接收一个参数 nbytes,表示需要分配的内存大小(以字节为单位)。如果内存分配器尚未初始化(即 bot 为 NULL),则会调用 init() 函数进行初始化。init()函数会把bot(arena数组第一个)设为空闲块,top(arena数组最后一个)设为占用块。然后根据传入的字节数 nbytes 计算需要的以块为单位进行内存分配的内存大小 size。从链表的起始位置 bot 开始,内存分配器遍历空闲块链表,寻找一个大小大于等于 size 的空闲块(当前块为空闲且其右块与当前块之间的空间大于等于size)。如果找到了合适大小的空闲块 p,则将其标记为占用状态(调用 CLR_FREEBIT(p) 函数),表示该块已经被分配出去。如果找到的空闲块大小大于 size,则会创建一个新的空闲块来存放剩余的空间()(top左指针指向空闲块尾,空闲块尾右指针指向top,空闲块尾左指针指向空闲块首,空闲块首右指针指向空闲块尾)。如图:

图 1
最后返回分配的内存块的首地址给调用者。
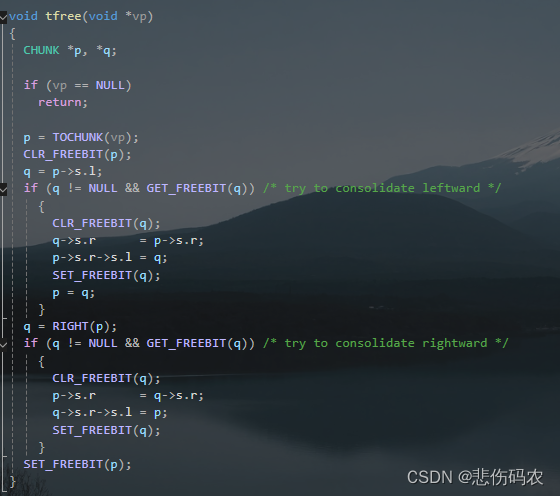
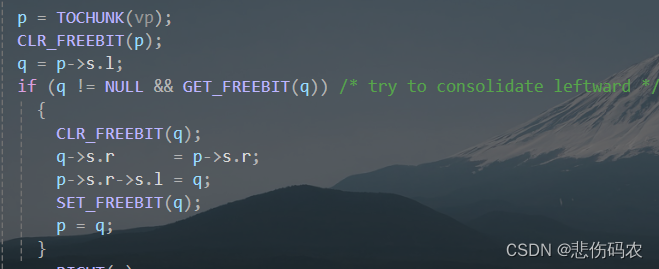
tfree函数的执行过程如下:
首先检查 vp 是否为 NULL,如果是,则直接返回,因为无需释放任何内存。然后使用 TOCHUNK 宏将指针 vp 转换为其对应的内存块头部指针 p。使用 CLR_FREEBIT 宏清除块 p 的空闲位,即将其标记为占用状态。然后尝试合并左空闲块(按图1即向上空闲块合并):首先获取 p 的左边相邻块 q,如果 q 不为空且是空闲的,则尝试与其合并。使用 CLR_FREEBIT 宏清除块 q 的空闲位。更新合并后的块 q 的右指针指向 p 的右指针所指向的块。更新 p 右指针所指向的块的左指针指向合并后的块 q。使用 SET_FREEBIT 宏设置块 q 的空闲位。更新当前处理的块指针 p 为合并后的块 q。然后尝试向右合并空闲块,原理类似,最后使用 SET_FREEBIT 宏设置块 p 的空闲位,表示该块现在是空闲的。这样,tfree函数完成了对给定内存块的释放,并尝试将其与相邻的空闲块合并,以减少内存碎片化。
结合vul4.c和tmallo.c,我们可以分析出,第一次为p使用tmalloc申请了500字节,(由于CHUNK数组一个8字节,按块分配内存,实际分配了504字节),然后为q申请了300字节(实际分配304字节,q也就指向第504字节所在地址),然后分别释放申请的空间,此时虽然块被标记为空闲,但实际上p,q仍指向原位置。之后再分配了1024字节给p,因为504+304<1024,因此q也就指向p所分配中某一块的地方,如下所示:
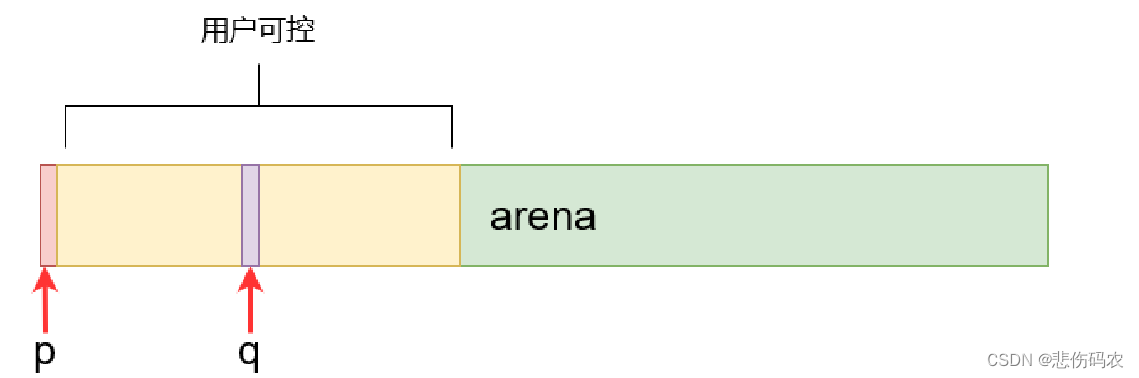
因此我们就可以给q所指的地方赋值,又根据tfree的原理,第二次释放q时,若我们在赋值q所指的地方时将其左指针设置为我们想要返回的地址,右指针设置为存储返回地址的地址,即foo函数的返回地址存储的地址。需要注意的是,与左节点合并必须满足左节点空闲,即左指针的第 5 位(左指针的右指针的低位,对应下图中q0->s.r)应该是奇数。当使用tfree时,语句p0às.ràs.l=q0,也就是相当于将q的右指针所指地址(也就是存储返回地址的地址)的前四字节(即其右指针)替换为q的左指针(也就是设置的返回地址)。
注意,上文提到的q指的是vul4.c中的q,而q0指的是tmalloc.c中的q,p,p0同理。
2.5.2 构造payload
1、确定shellcode地址(p所指内存地址);
在最后一个tfree的汇编代码处下断点:
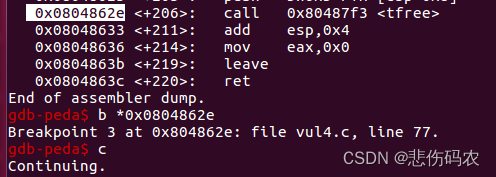
得到指针p指向的内存地址0x804a068
![]()
将shellcode设置为p起始地址偏移32字节处,便于后续操作
2、确定返回地址所在的内存地址
获得栈底指针寄存器 ebp 的值为0xbffffa4c
![]()
其上四字节即返回地址所在地,即0xbffffa50
3、获取q所指地址:
![]()
重新调试,在第三个tmalloc前下断点,可见覆盖前q堆首值:

可见其左指针指向p堆的堆首。
4、构造payload
上面提到将shellcode设置为p起始地址偏移32字节处,这是因为tfree时与左节点合并必须满足左节点空闲,即左指针的第 5 位(左指针的右指针的低位,对应下图中q0->s.r)应该是奇数,而shellcode第五位是0x76,不满足。

因此我们将q的左指针指向 p 的起始数据区域,同时将其 5~8 个字节赋值为 0xffffffff。但0xffffffff无法对应指令,当从p 的起始数据区域开始执行时到此处会出错,我们可以使用jmp指令跳过这部分区域,jmp指令对应机器码为\xeb,使用\xeb08跳过8字节偏移来跳过这部分。因此最后构造如下payload:
编译运行:

2.6 漏洞程序五
2.6.1 漏洞分析

该程序存在由错误使用snprintf函数导致的格式化字符串漏洞,snprintf函数的功能是根据指定的 format 字符串将格式化数据写入到 str 缓冲区中,并根据 size 控制写入的字符数。其原型如下:

可见,在函数定义中,其恰当的用法应当是当format中包含若干格式化指示符时,其后应该再加相同数量的参数以对应格式化指示符,但原程序中使用snprintf(buf, sizeof buf, arg);时,只有一个参数,且用户可以控制输入的内容,这就可能导致安全性问题。当用户的输入包含格式化字符串控制符时(如 %s、%n 等),snprintf找不到其对应的参数,但它不会意识到这一点,而是会继续尝试从堆栈中读取相应的数据,从而读取到错误的内存数据(越过了它能读取的边界)。恶意用户就可以精心构造输入文件,插入了类似 %x、%s 的格式化字符串,从而导致程序崩溃或者泄漏敏感信息。更严重的情况下,攻击者可能通过 %n 格式化字符串控制符修改内存中的数据,引发潜在的安全问题。
在理解程序存在的漏洞之后,我们还需要回顾一些c语言语法,已知:
a. 在C语言中可以通过%Ns(d/x/p/f等)来控制输出多少位,例如%2u可以输出2位无符号10进制数,因此使用%133u可以输出133位10进制数。
b. 在C99中,%n是一个格式说明符,主要用于 printf 和 sprintf 等函数。它的作用是将到目前为止写入(或读取)的字符数存储到一个 int 类型的变量中。例如语句printf("aaaaa%n", &count);printf("%d\n", count);的结果是:![]()
由此可以总结触发漏洞过程如下:
当构造的输入为

时,程序执行到snprintf(buf, sizeof buf, arg); 由于实际提供的参数比指示符要求的参数少,snprintf将尝试读取未定义的内存。在这种情况下,snprintf函数会试图读取额外的4字节,这样就读取了0xffff ffff,并将其视为无符号整数来打印, 然后读取到指示符%n时,会再向下读取4字节,即0xffffdb2c,并将其视为需要将输出字符数写入的地址,从而导致了3D被写入到内存0xffff bd2c中。通过这种方法,我们即可实现向任意内存写入数据,假如我们找到了snprintf函数的返回地址,并将其修改为shellcode的起始地址,就能使其返回错误的地址从而成功获取shell
2.6.2 构造payload
构造如下输入以调试获取buf及其他数据地址:

编译,使用gdb -e exploit5 -s /tmp/vul4调试,
catch exec
r
b foo
c
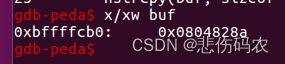
使用disas foo,disas snprintf命令反汇编foo snprintf函数,并通过p $ebp, x/xw buf等指令调试,获取buf起始地址和栈帧结构

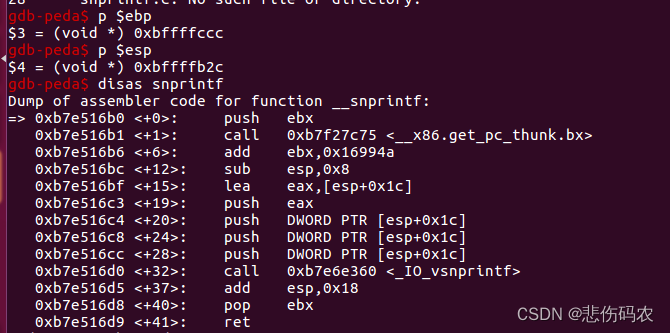
根据以上汇编指令和buf起始地址,可以推断栈帧结构如下:

可见snprintf()函数的返回地址储存在0xbfffffb2c处,同时,由于以下构造:

图 2
会不断修改buf中的数值,所以我们不能像前几次一样将返回地址修改为buf数组的地址,而是将其修改为arg数组的地址,通过命令x/xw查询到arg数组起始地址为0xbffffe61:

同时,由于构造输入的前数十个字节需要用于存储如图1的构造,我们不能将shellcode存储在arg数组起始处,可以存储在+96字节(0xbffffec1)处,并把返回地址设置为+80字节(0xbffffeb1)处(80字节已经足够容纳以上数据,且空余字节通过\x90填充,对应nop指令,不影响程序),从而构造以下payload

编译运行,没有出现预期结果,gdb调试,发现增加的c语言语句导致程序地址发生变化,新的地址如下:

如上文,重新构造payload如下

编译运行,成功获取具有root权限的shell
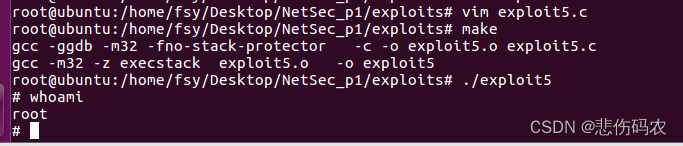
2.7 漏洞程序六
2.7.1 漏洞分析

vul6与vul2类似,也是可能导致一个字节的缓冲区溢出,但在执行foo函数后直接退出(exit(0)),因此无法使用vul2的构造方法,需要设法绕过此函数。exit()函数的汇编代码如下:

其在执行时第一条指令是jmp指令,若能修改其目标地址,则可跳转至我们想要跳转的地方。
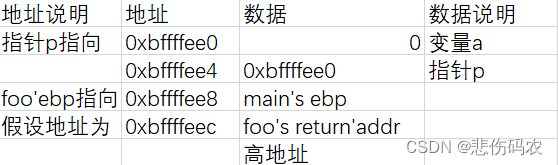
由漏洞程序2可知,通过nstrcpy()函数可以修改foo函数ebp的值,而变量p与a的位置是根据ebp决定的:

因此存在修改指针p指向地址空间的值的可能性。
结合vul2推断其栈帧结构大致如下:
进一步分析汇编代码,在执行bar()函数后执行*p=a时,其对应汇编指令如下:

也就相当于将ebp-0x8位置的数据复制到ebp-0x4的位置,若我们修改ebp指向buf数组中某一位置,从而使得ebp-0x8指向buf数组中某一数值,该数值定为jmp指令的目标地址存储的地方,根据上文exit函数反汇编代码可知为0x0804a00c,并使得ebp-0x4指向的地址中存储shellcode的开始地址,最终可以实现使用shellcode的开始地址替换jmp指令的目标地址,从而获取shell.
2.7.2 构造payload
根据上述原理,首先获取foo函数ebp和buf起始地址:


若将ebp修改为0xbffffe00,则其与buf起始地址的偏移为0xe00-0xd70=144
则ebp-0x8对应0xbffffdf8,偏移136,将其设置为buf起始地址0xbffffe00, ebp-0x4对应0xbffffdfc,偏移140,将其设置为0x0804a00c
如下构造payload

编译,由于原本获取的是以“hi there”为输入的ebp,buf,因此再次调试获取buf起始地址和ebp如下:

得到偏移0xd00-0xcb0-0x08 =80-8=72修改payload,如下:

编译运行,成功获取具有root权限shell

至此,全部实验成功















 276
276

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









