









简介
本文假定读者已经有了一定的目标检测的预备知识,否则请戳博客卷积神经网络总结及R-CNN系列目标检测算法总结(应该还不错,欢迎戳~)。本文将对Faster R-CNN中的关键点进行介绍,其它特别细节的点还是推荐阅读论文。
注:本文参考了很多其他文章,最后均给出了链接,感谢分享。
Faster R-CNN是在R-CNN和Fast R-CNN的基础上改进而来的,关于这两个模型的基本知识请戳上面的链接。Fast R-CNN中说唯一的遗憾就是region proposals是用SS算法产生的,跑在CPU上,消耗了大量时间。作者就想:为什么不用神经网络来产生region proposals呢,这样整个网络就都可以用GPU来跑了(RPN部分就是用来做这个的)。注意不单单是训练一个网络来产生region proposals,两个网络单独训练看起来并不那么优美,并且错过了共享计算的好处。所以我们要解决两个问题:
- 使用RPN网络来产生region proposals;
- RPN要和之前的网络(Fast R-CNN)共享卷积计算;
那么R-CNN,Fast-RCNN和Faster-RCNN之间的区别就很明显了:
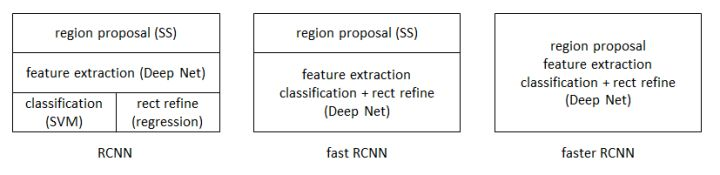
网络结构
下面先给出Faster R-CNN的网络结构,后面会对这个结构的关键部分进行介绍。

其中红色部分就是新增的RPN(用来产生Region Proposals),绿色部分是Fast R-CNN中就有的。(说白了Faster R-CNN就是在Fast R-CNN的基础上多加了一个RPN用来代替SS产生proposals而已)
Fast R-CNN
因为Faster R-CNN相对Fast R-CNN来说最大的改进就是利用RPN来代替SS产生proposals,除此RPN结构之外,其余的部分基本照搬Fast R-CNN,也就是上图中的绿框的部分,在这里就不再赘述,详细请参考论文。
RPN
这是Faster R-CNN中的关键。回想我们要解决的两个任务:
- 使用RPN网络来产生region proposals;
- RPN要和之前的网络(Fast R-CNN)共享卷积计算;
此处共享卷积部分就是让RPN和Fast R-CNN共享卷积计算(即上图最上面那个绿色的框)。这样,RPN部分也可以利用共享卷积部分提取到的feature map来产生proposals了。
RPN就是在Convs最后一层的基础上添加了额外的卷积层,所以RPN是一个全卷积网络,同时拥有对应的损失函数(后面讲),所以RPN是可以被端到端地训练。RPN的作用就是代替以前的SS来产生一幅图的Region Proposals。
因为RPN部分会生成很多的默认框(anchors),所以要解释RPN就不能不提到anchors。
Anchors
Anchors是RPN中一个重要的概念。在feature map中每个点(注意是每个点!)都会预测k个anchor boxes(论文中 k = 9 k=9 k=9),这些anchor是在输入图像上的,相当于预选的ROI。同时这些anchor都是以feature map的每点为中心(可以映射到输入图上),且其大小和长宽比都是事先固定的(论文中使用了三种大小及长宽比,即k=9),所以这些anchor boxes都是确定的。下面是一个点上的9个anchor boxes:
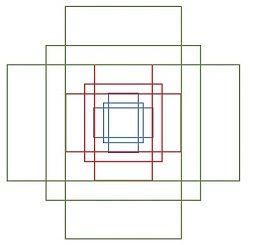
为什么要有多种anchor,就是为了引入多尺度。引入多尺度有三种方式,这一点参看原文中的Figure 1以及下面的解释,这里不再赘述。
Proposals生成
论文中实际上在feature map上使用了 n ∗ n n*n n∗n的sliding window(n=3),所以anchor boxes的中心就是sliding window的中心:

红色的框就是sliding window(注意sliding window只是选择位置,除此之外没有其它作用,和后面的 3 ∗ 3 3*3 3∗3的卷积区分),大小为 n ∗ n n*n n∗n(实现时n=3)。下面来解释这一幅图(Faster中最关键的地方):
以ZF的网络结构为例,Convs提取到的归一化图像(resize过后的图像,即架构中 M ∗ N M*N M∗N的图)的feature map有256个通道。
然后RPN想在这个feature map(视为一张有256个通道的图片)上滑动一个小网络来对其每个点在归一化图像上对应的9个anchor boxes进行打分(判断每个box是否为前景)和回归(每个box的位置修正变换)。对应上图就是2k和4k的输出(k=9),2代表了前景背景,4代表了位置坐标转换的4个值(见R-CNN)。
下面来介绍Proposals的生成过程,如图:
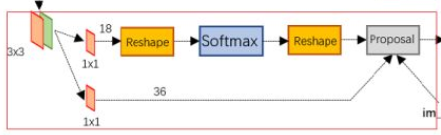
共享卷积部分得到的特征图先经过一个 3 ∗ 3 3*3 3∗3的卷积生成具有256个channel的特征图。(为什么要这么做?论文中也没具体说,目测是为了融合附近pixel的信息,更鲁棒?)
补充:这里有一点我们要特别说明一下,想必大家都知道卷积操作存在感受野。但是这里有个坑,比如一副
8
∗
8
8*8
8∗8的图片卷积后得到一个
4
∗
4
4*4
4∗4的特征图,此时并不是说特征图中的每一个点都是对应输入图片的一个
2
∗
2
2*2
2∗2的区域的!不多解释,具体见下图:

我这里谈感受野是想表达:,feature map中的一个点在输入图像上的感受野是很大一片区域。而这个区域基本上可以包含想要的9个anchor boxes(anchor boxes的大小设定应该是跟原始图像中想要检测的目标大小有关)。即使没有完整的包含anchor box也ok,因为如果找到了目标的中心一大部分信息,也能大致推断出是否是目标以及目标的大致范围(在某篇博客中看到的)。所以通过那256维的特征向量(后面会说)就能包含9个anchor的信息。(这就是特征表示学习的含义)
言归正传,在共享卷积部分得到的特征图经过
3
∗
3
3*3
3∗3的卷积后,对应点(我们现在只看一个点,相当于不滑动卷积核,对理解有帮助)即周围信息其实就变成了一个256维的特征向量(再次强调这个特征向量只是针对feature map中的一个点在归一化图像上的信息)。这个256维的特征向量就会用于分类和回归,它会与
1
∗
1
1*1
1∗1的卷积层相连,一个卷积层的神经元个数是2k(k=9),另一个卷积层的神经元个数是4k。如下:

看完单个点的,再来看完整的

上面所谓的第一个位置,第几个anchor,anchor的哪个参数都是我自己理解的一种方式,实际的排序可能不是这样,这样写只是想说最后那18个卷积核和36个卷积核都有自己的任务:针对同一位置不同Anchor或者同一Anchor的不同的指标(是否是前景,以及位置坐标转换等)
损失函数
损失函数(和Fast R-CNN类似)分为两部分:一个是分类的损失(softmax损失),一个是回归的损失(anchor位置坐标修正, s m o o t h L 1 smooth\ L_1 smooth L1 loss)。如下:
L ( { p i } , { t i } ) = 1 N c l s ∑ i L c l s ( p i , p i ∗ ) + λ 1 N r e g ∑ i p i ∗ L r e g ( t i , t i ∗ ) L\left(\left\{p_{i}\right\},\left\{t_{i}\right\}\right)=\frac{1}{N_{c l s}} \sum_{i} L_{c l s}\left(p_{i}, p_{i}^{*}\right)+\lambda \frac{1}{N_{r e g}} \sum_{i} p_{i}^{*} L_{r e g}\left(t_{i}, t_{i}^{*}\right) L({pi},{ti})=Ncls1i∑Lcls(pi,pi∗)+λNreg1i∑pi∗Lreg(ti,ti∗)
其中i是mini-batch中anchor的索引, p i p_i pi是anchor i是前景的预测概率(网络计算出来的值), p i ∗ p_i^* pi∗是anchor i的真实情况:如果anchor i是前景(通过IOU来确定)则为1,否则为0。
这里又要涉及到如何断定anchor是否为前景:
- 与GT相比,拥有最高的IOU的anchor为前景(可以低于0.7)
- 与任意GT相比,IOU>0.7为前景(正样本)
- 与任意GT相比,IOU<0.3为背景(负样本)
- 其余的非负非正,则没有用。(忽略,不计算损失)
然后是各个损失的详细定义如下:
L c l s ( p i , p i ∗ ) = − log [ p i ∗ p i + ( 1 − p i ∗ ) ( 1 − p i ) ] L_{c l s}\left(p_{i}, p_{i}^{*}\right)=-\log \left[p_{i}^{*} p_{i}+\left(1-p_{i}^{*}\right)\left(1-p_{i}\right)\right] Lcls(pi,pi∗)=−log[pi∗pi+(1−pi∗)(1−pi)]
L r e g ( t i , t i ∗ ) = R ( t i − t i ∗ ) L_{r e g}\left(t_{i}, t_{i}^{*}\right)=R\left(t_{i}-t_{i}^{*}\right) Lreg(ti,ti∗)=R(ti−ti∗)
smooth L 1 ( x ) = { 0.5 x 2 if ∣ x ∣ < 1 ∣ x ∣ − 0.5 otherwise \text { smooth }_{L_{1}}(x)=\left\{\begin{array}{ll}{0.5 x^{2}} & {\text { if }|x|<1} \\ {|x|-0.5} & {\text { otherwise }}\end{array}\right. smooth L1(x)={0.5x2∣x∣−0.5 if ∣x∣<1 otherwise
值得注意的是 N c l s N_{cls} Ncls :是mini-batch的大小(256), N r e g N_{reg} Nreg是anchor位置的数量(论文里是the number of anchor locations,且大约为2400,论文中有讲)。 λ \lambda λ为10,意味着这样两种损失基本上同样重要。实验结果显示,最终结果(mAP)对 λ \lambda λ的值不敏感。
再结合之前说的"最后那18个卷积核和36个卷积核都有自己的任务:针对同一位置不同Anchor或者同一Anchor的不同的指标(是否是前景,以及回归意见等)",可以把网络看成学习了9个前景/背景打分器,9个线性回归器。每个打分器对一个点的某种anchor判断是前景还是背景,每个线性回归器对一个点的某种anchor进行位置修正。
有了打好分的anchor boxes以及初步位置修正的transformation,再结合原图的一些信息就能经由图2中的Proposal层来得到输入图像的Region Proposals(这里面又涉及到NMS,以及剔除超出图像边界的ROI,后面会讲)。这样RPN就代替SS算法产生了输入图像的Region Proposals(也就是ROI),剩下的事情例如在feature map中找到Region Proposals对应的部分和ROI polling等就和Fast R-CNN一模一样了,这里不再赘述。
注:论文中得到的feature map大小为 60 ∗ 40 60*40 60∗40,因为每个点产生9个anchor,所以大约有20000个anchor,去除掉超过原图边框的anchor,大致还剩6000个,再进行NMS(论文中的阈值为0.7),最后剩下大概2000个anchor。
done~
References
- https://arxiv.org/abs/1506.01497
- https://arxiv.org/abs/1504.08083
- https://zhuanlan.zhihu.com/p/31426458
- https://blog.csdn.net/v_july_v/article/details/80170182
- https://zhuanlan.zhihu.com/p/30720870
- https://blog.csdn.net/shenxiaolu1984/article/details/51152614
- https://zhuanlan.zhihu.com/p/49897496
- https://www.cnblogs.com/wangyong/p/8513563.html
- https://zhuanlan.zhihu.com/p/32404424
- https://zhuanlan.zhihu.com/p/28585873














 1853
1853











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









