









 本文深入讲解AlexNet、ZF-Net、VGG-Net、Inception系列、ResNet及DenseNet等经典卷积神经网络的设计理念与核心改进,剖析网络结构、计算方法及性能提升策略。
本文深入讲解AlexNet、ZF-Net、VGG-Net、Inception系列、ResNet及DenseNet等经典卷积神经网络的设计理念与核心改进,剖析网络结构、计算方法及性能提升策略。
文章目录
概要介绍
本文主要讲解到目前为止一些经典的卷积神经网络(CNN),这些网络或其衍生网络经常作为其他复杂网络的backbone,因此,熟悉这些常见的基本网络还是非常有必要的。本文主要关注的是卷积神经网络的设计哲学,不仅仅局限于某一种网络,还会介绍每一种网络相比之前网络的改进以及为什么要这么做。总之,本文的主要内容就是:ConvNets Design Philosophy - From AlexNet to DenseNet
声明,本文的部分内容摘自CS231n的课件,我一年多前做的一个PPT和一些其他博主的优秀博客,在文章的最后会给出参考链接。
本篇文章需要一些预备知识:基本的微积分,基本的机器学习知识(比如线性分类器,损失函数,过拟合,欠拟合等),基本的优化方法(如SGD等),反向传播等。
首先给出本文的介绍内容

在介绍基本卷积神经网络之前,我们先来简单回顾一下CNN的基本知识和计算方法,下图是卷积操作的示意图:
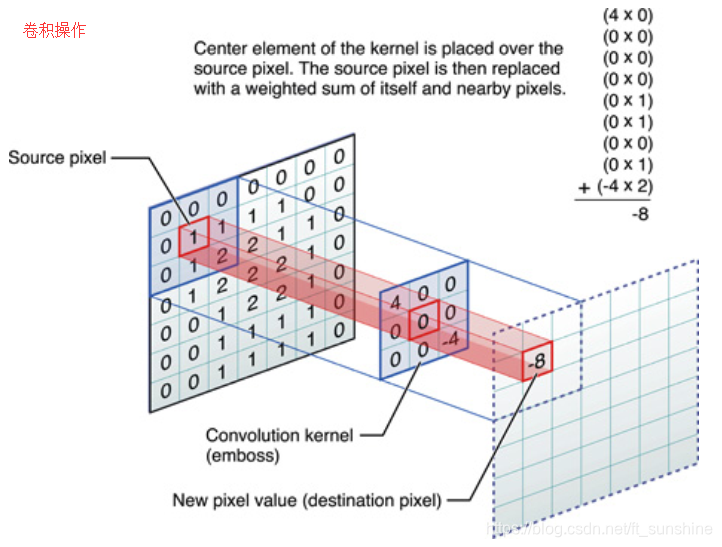
如果还不是特别清楚,见下面的动图(这个图是当年帮助我入门的图,哈哈哈哈哈哈):
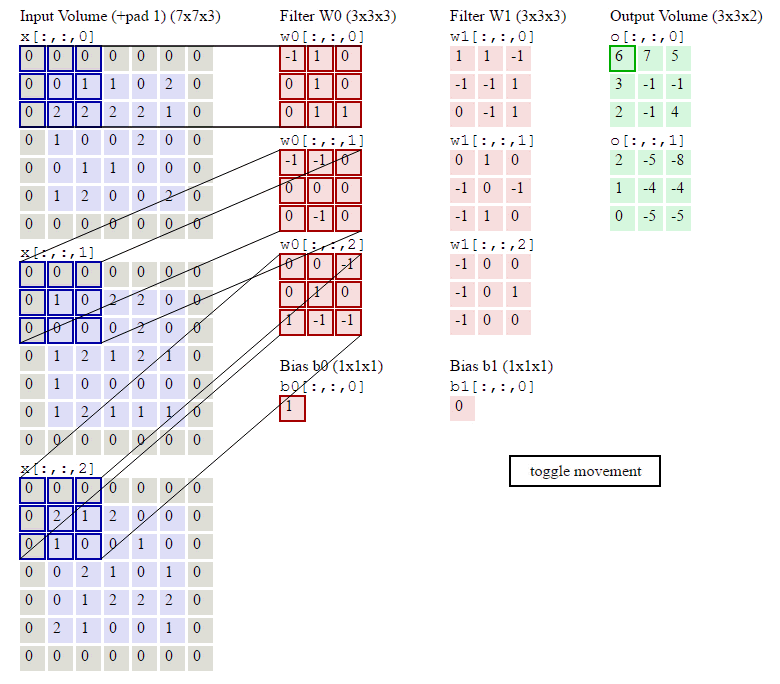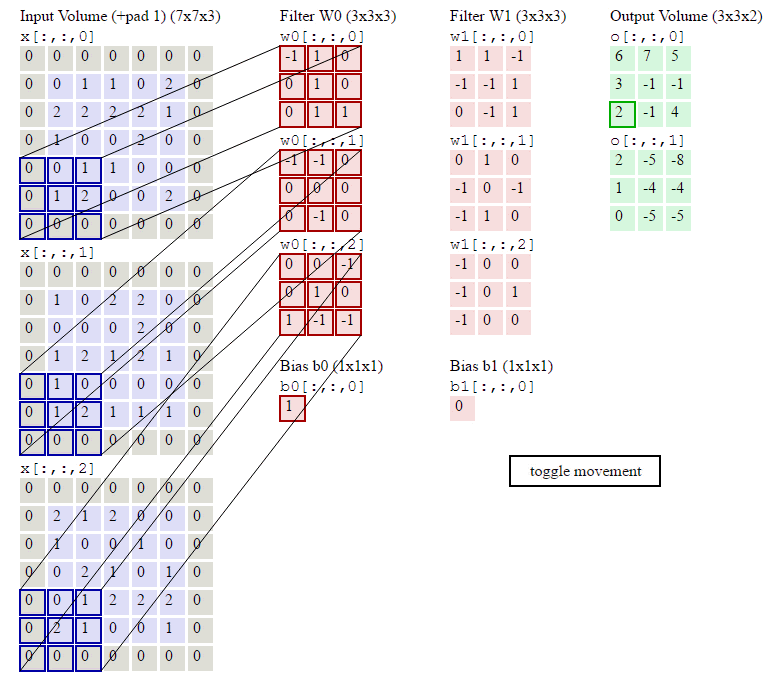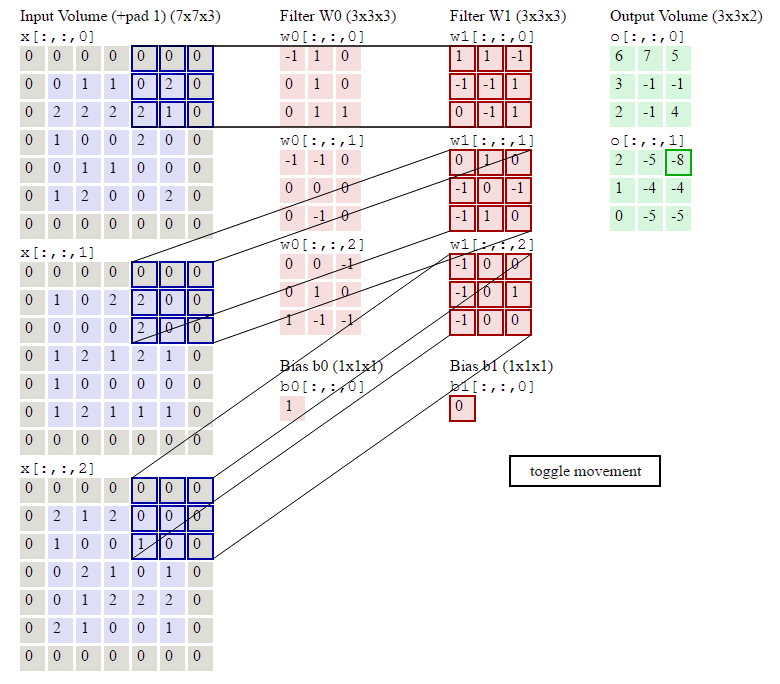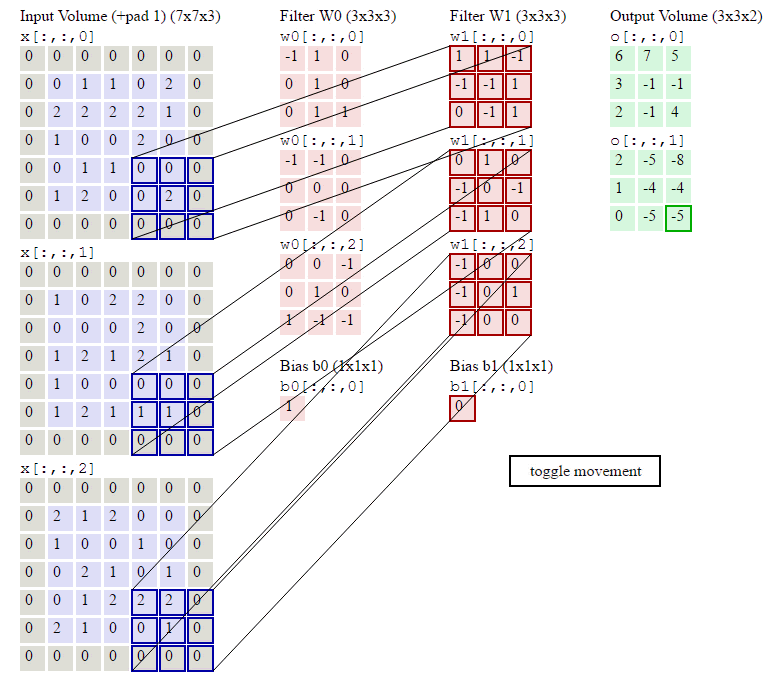
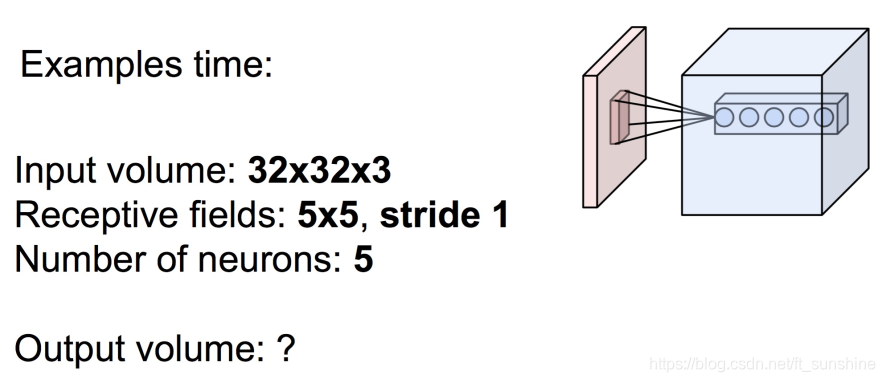
在了解了什么是卷积操作之后,我们还要知道与卷积操作有关的一些计算,如下:已知输入数据为
32
∗
32
∗
3
32*32*3
32∗32∗3,卷积核为
5
∗
5
5*5
5∗5,步长为
1
1
1,神经元的个数为
5
5
5,现在问这个卷积操作的输出是什么样的?
输出结果的volumn(不知道怎么翻译好,大概就是尺度,形状的意思)为:
28
∗
28
∗
5
28*28*5
28∗28∗5,计算过程如下:
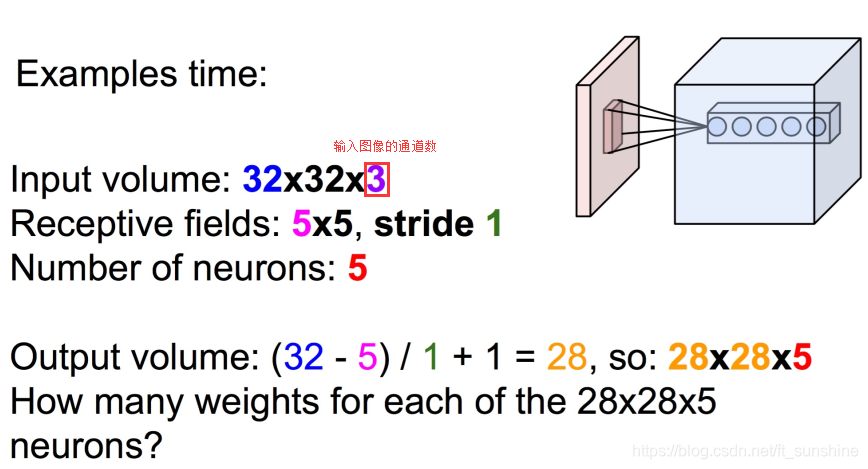
那么对于每个神经元(例子中为5个),其参数量为多少呢?

好了,在了解了基本卷积过程和其运算之后,下面我们开始具体介绍一些基本的卷积神经网络。
基本卷积神经网络(CNN)
AlexNet
AlexNet(2012)的主要贡献就是在2012年的ImageNet比赛中一举以碾压优势夺冠,开启了用卷积神经网络做图像处理的先河。
AlexNet的网络结构如下:
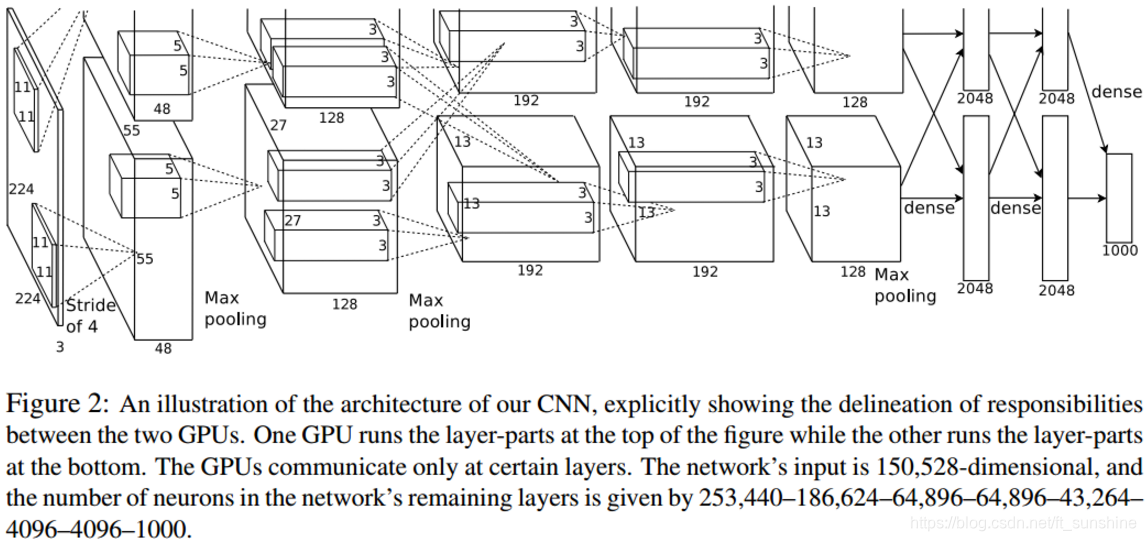
下面还是来关注一下有关AlexNet的卷积操作计算问题(按照上面给出的计算方法是可以算出来的)
layer1:卷积层

layer2:最大池化层(注意:池化层是没有参数的,这一层的参数量为0!)

下面是AlexNet的详细结构图和参数,以及AlexNet当时的一些创新点

ZF-Net
ZF-Net(2013),额。。。。这个实在没啥好讲的,其只是对AlexNet做了一点小小的改进。比如将AlexNet的卷积核改小,增加每一层的神经元个数等。
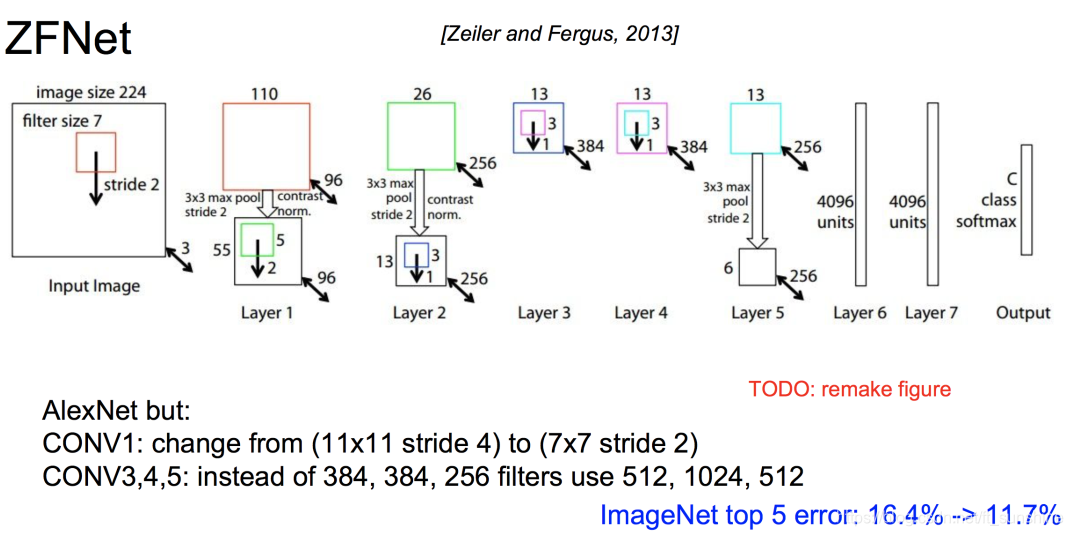
上图中的16.4% -> 11.7%代表的是卷积神经网络在ImageNet数据集上的错误率(人类在这个数据集上的错误率大概为5%)
VGG-Net
其实VGG-Net(2014)也算是一个小里程碑,VGG-Net现在也很常见,其对比与Alex-Net的主要改进为:更小的卷积核,更深的网络,VGG-Net的网络架构如下:

那么现在有个问题,VGG-Net的两个改进,为什么会能提高网络的性能呢?
使用更小的卷积核是当前在保证网络精度的情况下,减少参数的趋势之一,在VGG16中,使用了 3 3 3个 3 ∗ 3 3*3 3∗3卷积核堆叠(stack)来代替 7 ∗ 7 7*7 7∗7卷积核,使用了 2 2 2个 3 ∗ 3 3*3 3∗3卷积核堆叠来代替 5 ∗ 5 5*5 5∗5卷积核。使用更小的卷积核堆叠来代替一个大的卷积核,这样做的主要目的是:
- 在保证相同感受野的情况下
- 提升网络的深度
- 提升网络的非线性表达能力(层数多)
- 降低网络模型的参数量
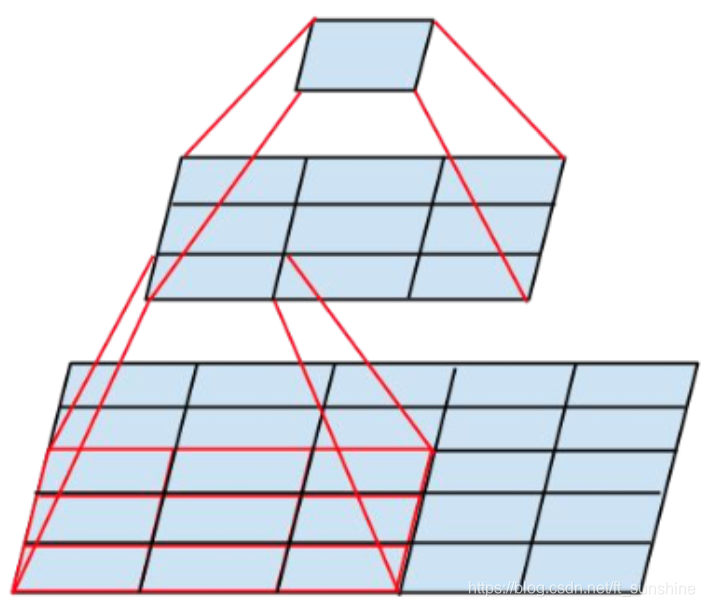
以下简单地说明一下小卷积( 3 ∗ 3 3*3 3∗3)对于 5 × 5 5×5 5×5网络感知野相同的替代性。
如图所示:
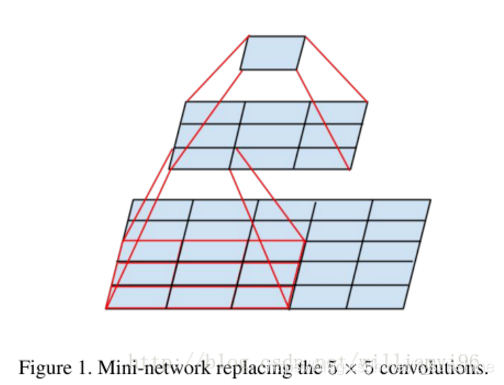
由上图可以看出,
2
2
2个
3
∗
3
3*3
3∗3的卷积核(stack)和
1
1
1个
5
∗
5
5*5
5∗5的卷积核的感受野是相同的,关于
3
3
3个
3
×
3
3×3
3×3卷积核对于
7
×
7
7× 7
7×7卷积核的替代性思考方式同上。
下图就是使用更小的卷积核的堆叠来代替大卷积核的原因:

注:上图中的参数量的计算按照上面给出的计算方法也是可以算出来的。
下图是VGG-Net的整体网络结构图和详细参数。

|
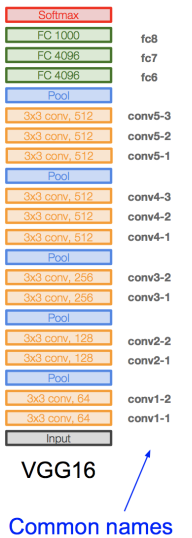
|
Inception系列
Inception系列是google发布的若干网络结构,命名都叫Inception-V
x
x
x,下面主要介绍以下四部分:

Inception-V1:GoogLeNet
在GoogLeNet(2014)之前,网络的设计思路是一直在stack(堆叠)层数,当时的假设是网络越deeper,网络的performance越好。到了2014年,GoogLeNet横空出世,GoogLeNet改变了这个假设:除了增加深度,还增加了网络的宽度。GoogLeNet的结构如下:

下面我们一步步来推倒出Inception module的设计,先来看初始版本的Naive Inception module。Naive Inception module就是对同一个输入,用不同大小的卷积核去卷积,然后分别把它们的结果给concatenate(注意这里要求不同卷积操作输出的feature map的大小要相同,不然没法特征拼接呀)起来。但这样有个问题:计算量太大了!

注:上图
3
∗
3
3*3
3∗3卷积的
p
a
d
d
i
n
g
=
1
padding=1
padding=1,
5
∗
5
5*5
5∗5卷积的
p
a
d
d
i
n
g
=
2
padding=2
padding=2(为保证不同卷积操作输出的特征图大小一样,以便于后面的特征拼接)
Naive Inception module的计算量的计算过程如下,可见Naive Inception module的计算量是相当大的(这还只是一层)。

那么我们应该如何减少计算量呢?用的是什么理念和思想呢?
这就不得不提到从2014年一直延续至今的神经网络设计思想:bottleneck。使用bottleneck(即 1 ∗ 1 1*1 1∗1的卷积核)来进行特征降维,减少特征图的层数,从而减少计算量。
bottleneck的过程如下面两张图片所示:

|

|
所以到这里,Naive Inception module就升级为了Inception module。

此时这一个Inception module的计算量为358M ops,相比之前的854M ops,使用“bottleneck”的Inception module的计算量降低了一半多!
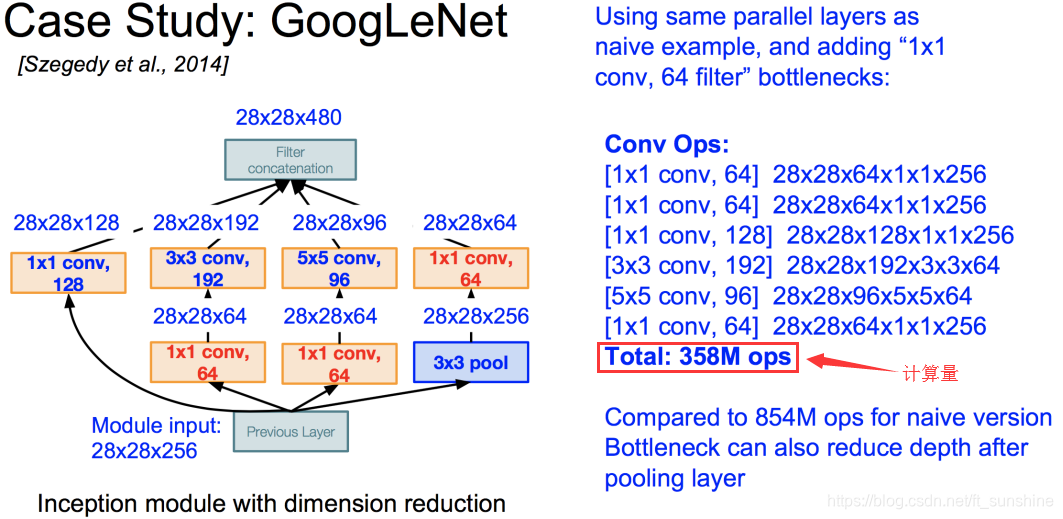
到这里,Inception module的结构就介绍完了,而GoogLeNet的架构就是多个Inception module一层一层地stack(堆叠)出来的,下面是GoogLeNet的整体架构的介绍。
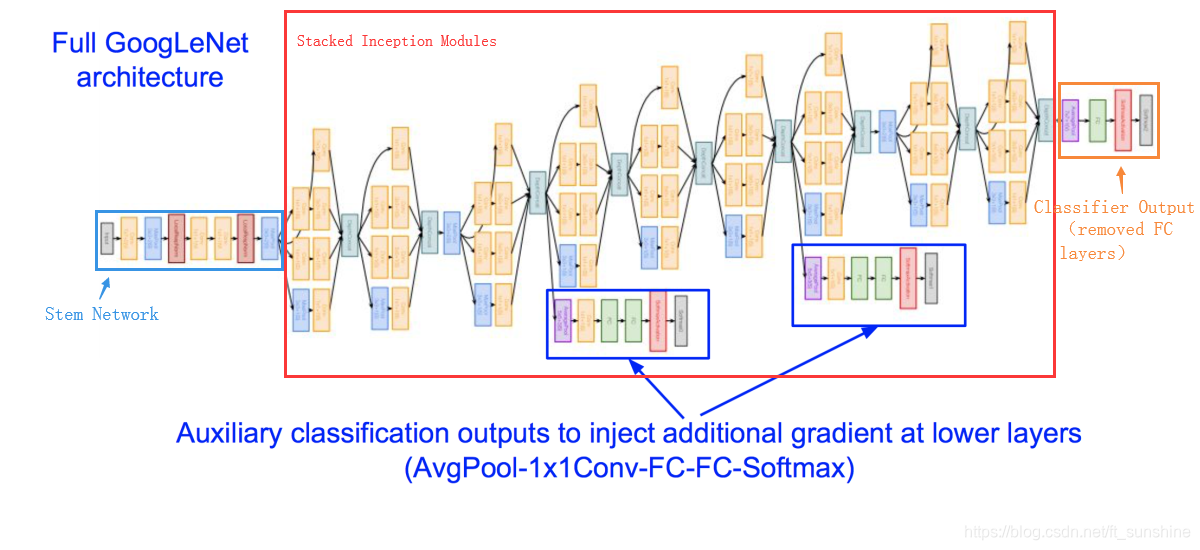
注:上图中可以看到有三个分类输出头,为什么要用三个classifier呢?结合GoogLeNet的论文,我个人认为有以下几点原因:
- 一般认为深度越深,越有可能产生梯度消失的问题。这里深度不同的三个classifier可以有效缓解梯度消失问题,即浅层的classifier也可以回传误差,缓解梯度消失问题。
- CNN深度越深的层,提取的特征语义信息越丰富,深度越浅的层提取的特征更基础,包含更多的位置信息,所以并不是深度越深的层提取的特征一定好于较浅层提取的特征。这里在不同深度的层上面都加了一个output layer,可以做一个模型的ensemble,这可能会提升模型的效果。
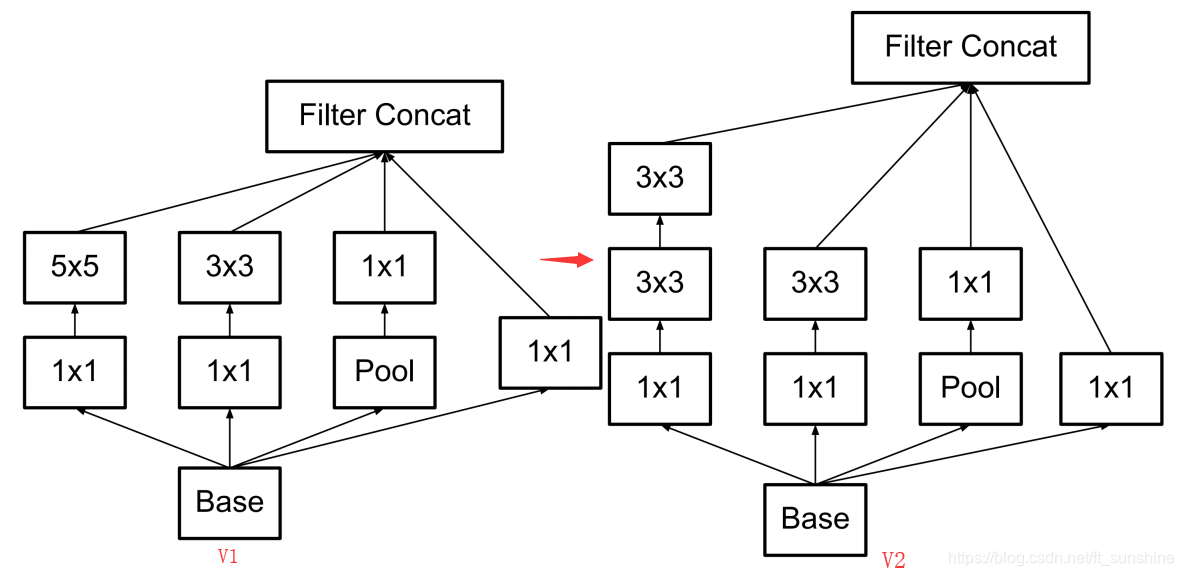
Inception-V2:An Improved Version of Inception-V1
Inception-V2主要有两点改进:
- Add Batch Normalization based on Inception-V1.
- Replace 5x5 and 7x7 conovolutional kernels with 3x3.
其结构如下:
|
|
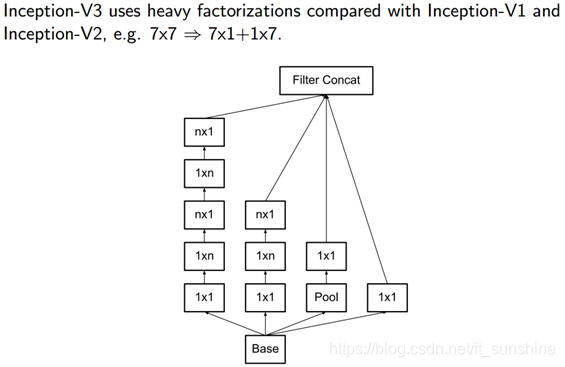
Inception-V3:Factorizing NxN into 1xN and Nx1
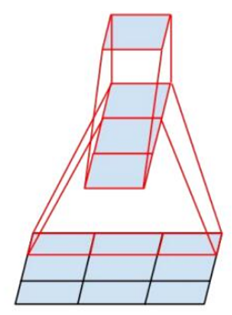
既然之前的一个 7 ∗ 7 7*7 7∗7的卷积核可以分解为 3 3 3个 3 ∗ 3 3*3 3∗3的卷积核,那么能不能分解的更小一点呢?可以验证,任意 n ∗ n n*n n∗n的卷积核都可以通过 1 ∗ n 1*n 1∗n卷积后接 n ∗ 1 n*1 n∗1卷积来代替。
将一个较大的( n ∗ n n*n n∗n)二维卷积分解为两个较小的一维卷积,这种非对称的卷积结构拆分,节省了大量的参数,其结果对比将一个大卷积核拆分为几个相同的小卷积核 ,效果更明显。
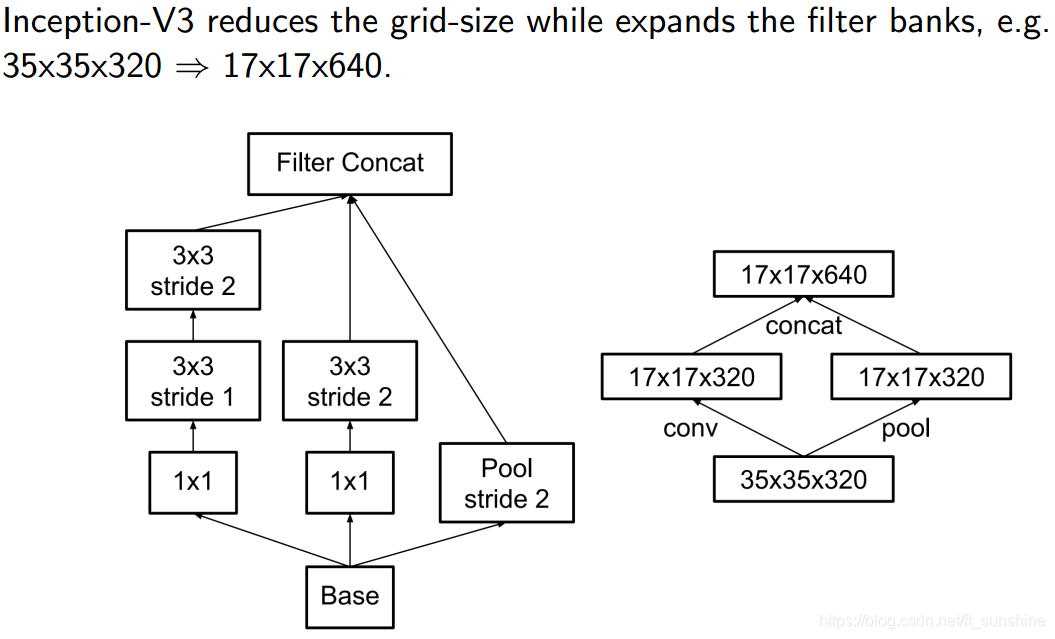
Inception-V3的结构如下:
|
|
|
Inception-V4:Inception with skip connections
- Inception-V4 introduces skip connections (ResNet) compared with previous Inception series.
即Inception-V4大概就相当于之前的Inception + ResNet,因为后面马上就要介绍ResNet,所以这里就不再详细介绍Inception-V4了,只给出其结构图,如下:
ResNet
- Very deep networks using residual connections
ResNet(2016)之后,CNN真正到了层数能超过100层(常用ResNet 50,101,152)的时代(甚至训了一个1202层的ResNet,,,吓人)。训练很深的神经网络有一个问题,深度太深,梯度回传困难,很容易发生梯度消失或者爆炸的问题,就是这个原因一直阻碍人们stack更深的网络(因为训不了),很深的模型在模型优化的时候会非常难。
那么如何解决deeper model训练优化困难的问题呢?
solution: 引入残差,使模型训练更easy => 更深的模型性能表现更好这个愿望终于实现了!
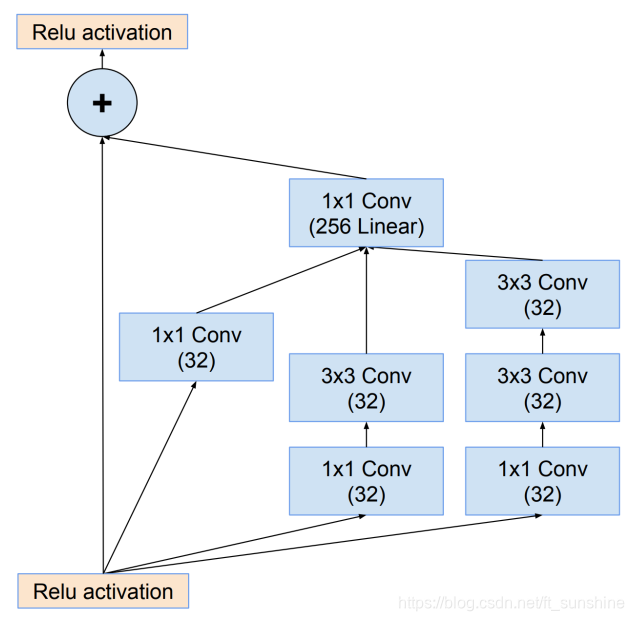
Residual Block的结构如下:
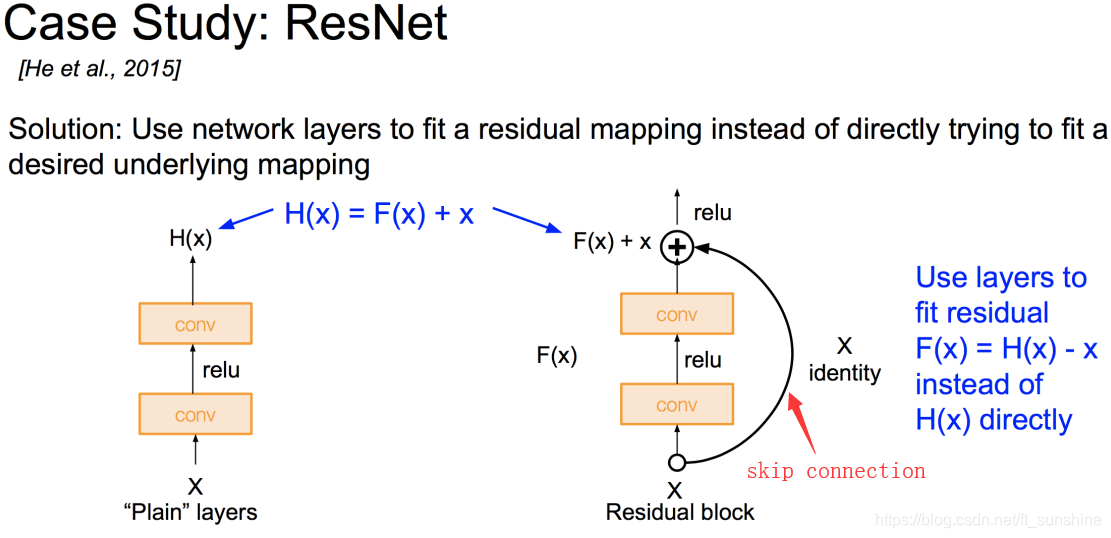
如上所示,ResNet实际上并没有直接学 H ( x ) H(x) H(x),而是学了个残差 F ( x ) = H ( x ) − x F(x) = H(x) - x F(x)=H(x)−x。如果了解BP算法(反向传播算法)的话,可能比较好理解反向传播的本质就是链式求导,而ResNet学习的是残差,这样的话在求偏导时就不会出现导数为0的情况(学了一个残差,所以要对残差求偏导)。所以使用ResNet,我们可以训练更深的网络。
ResNet的结构如下:
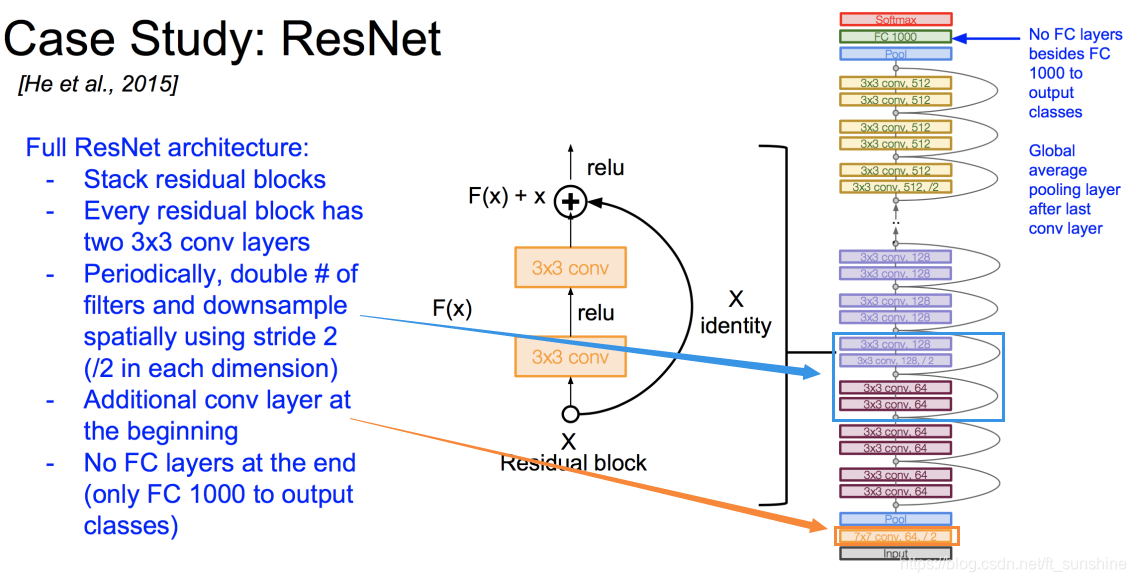
当然,想优化还可以继续优化……

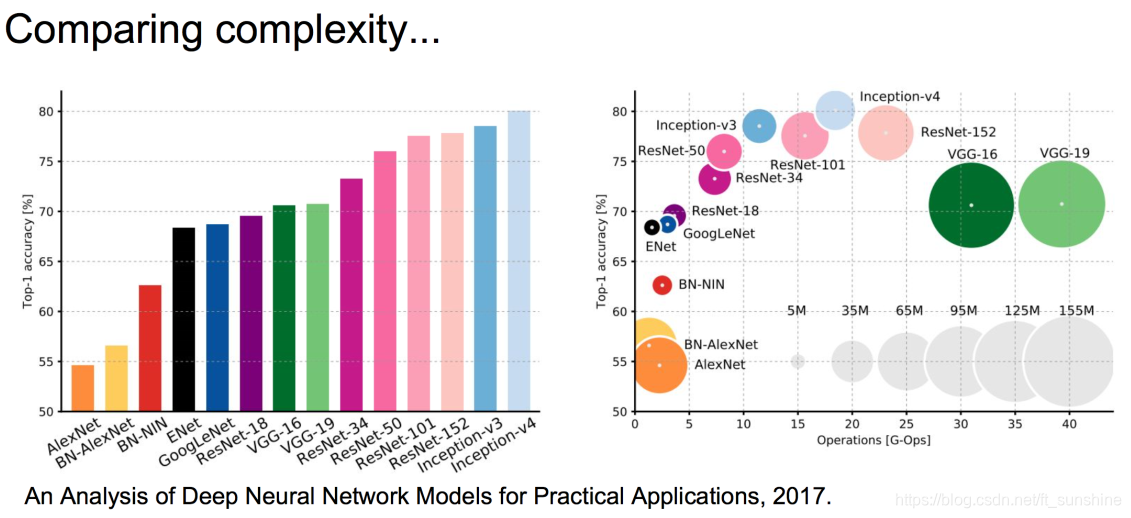
下面是以上所讲网络模型的性能分析图:
DenseNet
终于到最后一个了,为啥CSDN不能发表情包!难以表达我现在的心情(手动笑哭 * 50)
现在我们有三种方式来处理不同卷积层之间的特征图:
- Standard Connectivity
- Residual/Skip Connectivity
- Densenet: Dense Connectivity
这三种方式的图示如下:
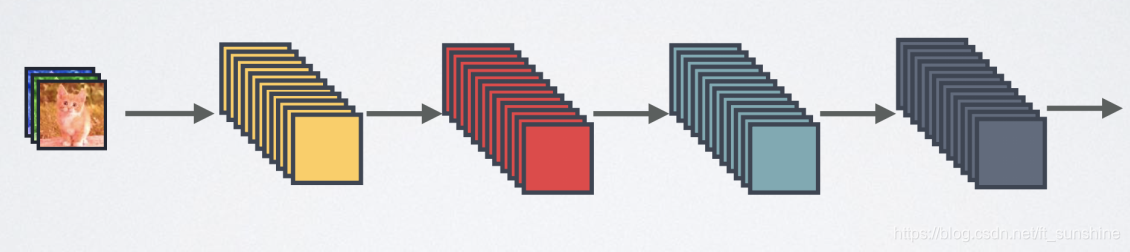 Standard Connectivity Standard Connectivity
|
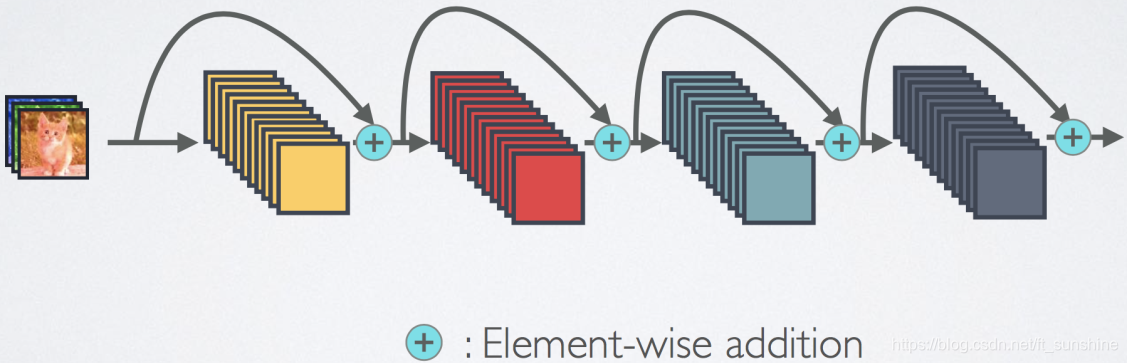 Residual/Skip Connectivity Residual/Skip Connectivity
|
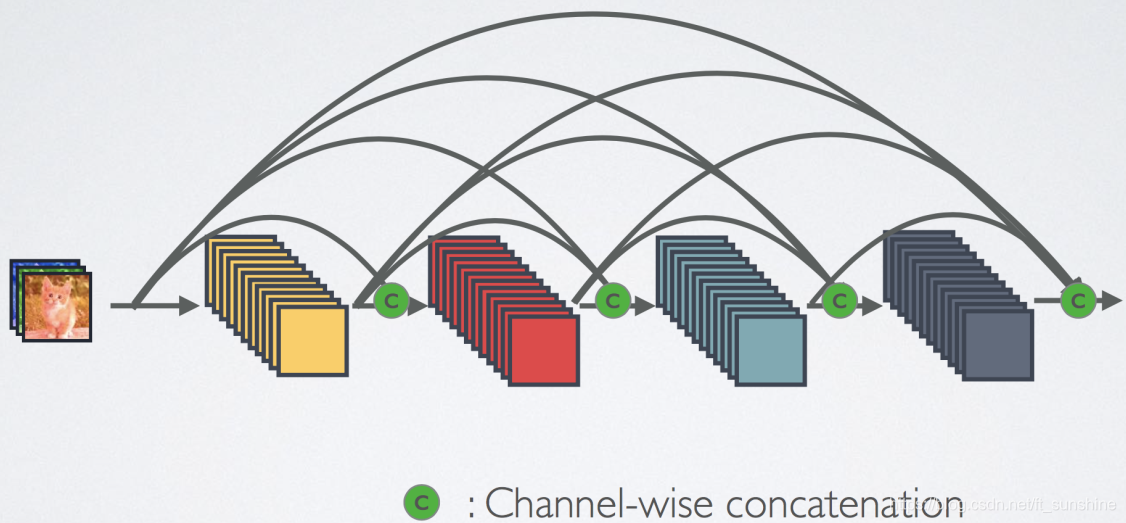 Densenet: Dense Connectivity Densenet: Dense Connectivity
|
DenseNet的思想是某一层的输入是其前面每一层的输出,即将不同层得到的特征图进行融合作为某一层的输入,这样CNN的每一层就可以得到前面不同层提取的特征(浅层位置等基础信息,深层语义信息),这样网络的表达能力会更好。图示如下:

大家看到这里可能会想,如果每一层的特征图都这样堆叠下去,那么特征图的层数不就无限增长了吗,这样特征的维度就会爆炸!
solution: 用之前提到的
1
∗
1
1*1
1∗1卷积啊!bottleneck降维
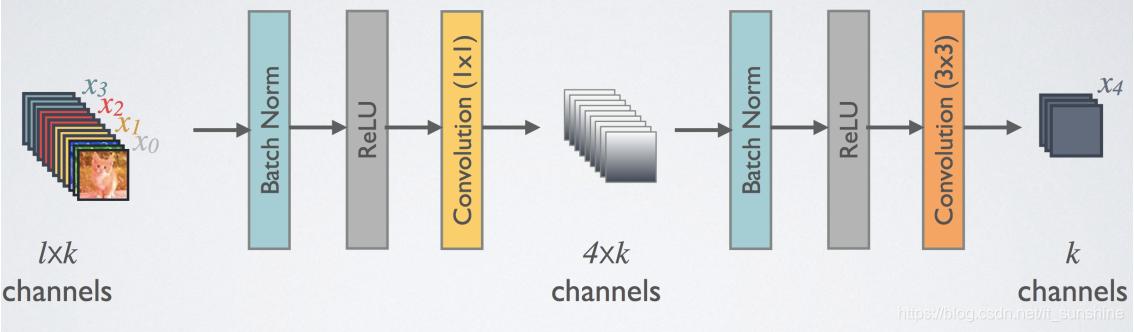
下图是Dense Blocks的结构图,在每个Dense Blocks内部,每层的feature map的大小是一致的(方便特征融合),不同Dense Blocks之间有Pooling层用于减小feature map的大小。
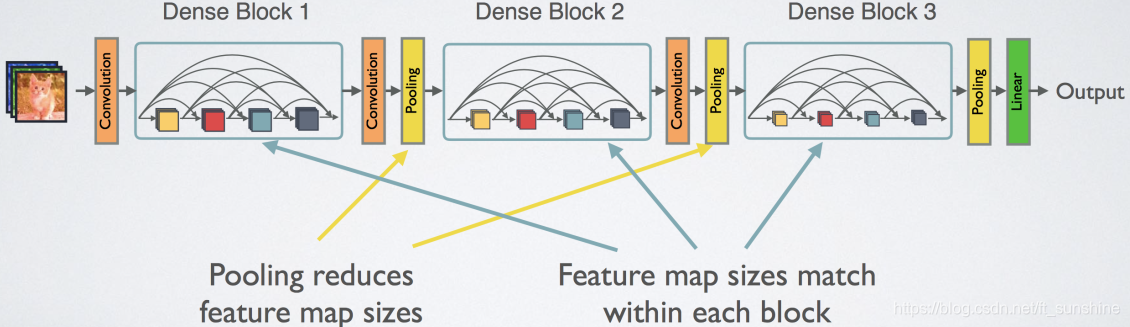
至此,DenseNet也算介绍完了,上面就是目前较为常见的基础CNN网络的介绍,重点关注每种网络的设计理念和思想。
欢迎大家有问题积极讨论,谢谢。

















 1746
1746

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









