






OpenAI发布会重点:
-
发布了三款新模型:GPT‑4.1、GPT‑4.1 mini 和 GPT‑4.1 nano。
-
模型在各方面均优于 GPT‑4o 和 GPT‑4o mini
-
100 万个 token上下文窗口,更强的长上下文理解能力。
-
模型知识截止日期更新至 2024 年 6 月。
-
能力提升要点:编程、指令遵循、长上下文处理能力
-
以API 的形式发布这三个新模型
-
GPT-4.5 Preview 将于 2025 年 7 月 14 日停用
笔者思考:
本次发布内容没有和最近刚出的Gemini 2.5pro进行对比是一个遗憾,之前有发过Gemini 2.5pro文章,在本文下面有链接,对AI感兴趣的可以文末看一下。
想学习AI的,🔍:ai_service,进👗,告诉我你想解决什么问题
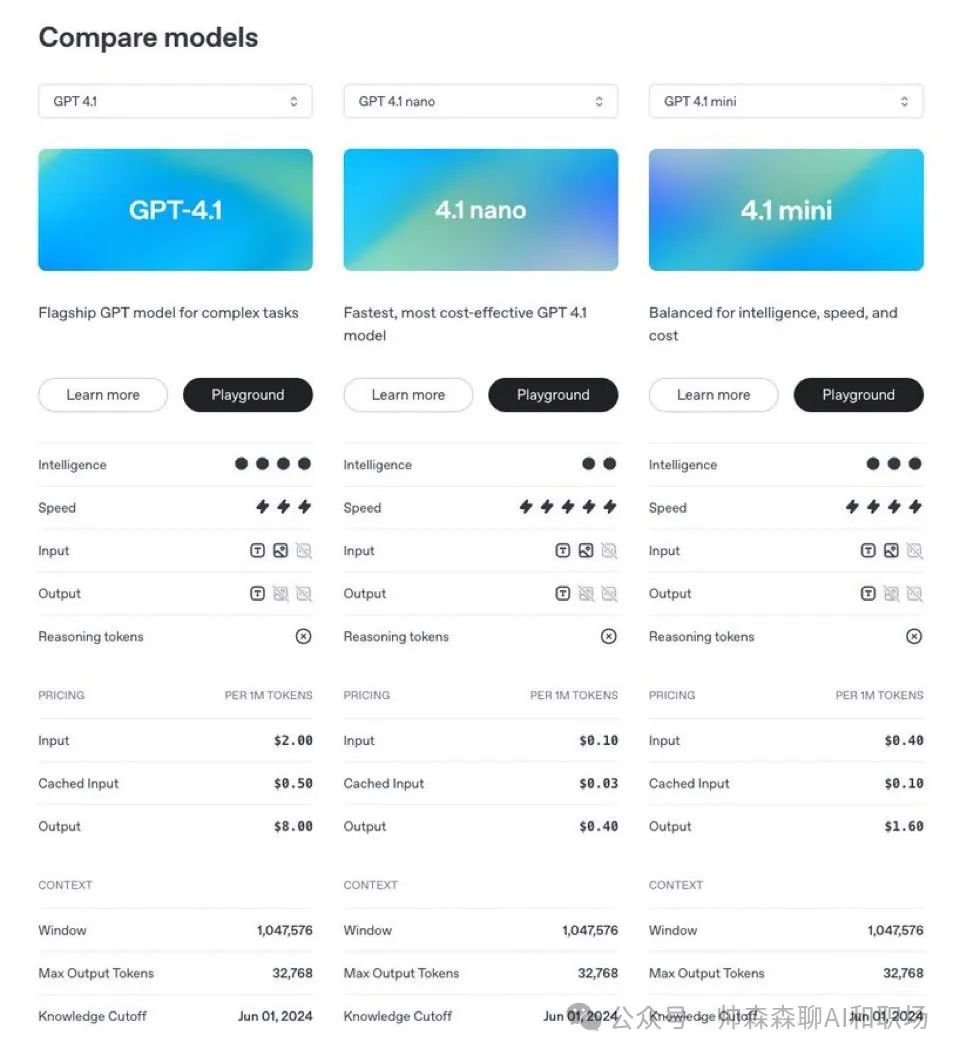
GPT‑4.1 在以下行业标准评估中表现出色:
编程能力:
在 SWE-bench Verified 评测中,GPT‑4.1 取得了 54.6% 的得分,比 GPT‑4o 提高了 21.4 个百分点,比 GPT‑4.5 提高了 26.6 个百分点,成为目前领先的代码生成模型。
指令理解能力:
在 Scale 推出的 MultiChallenge 基准测试(衡量模型指令执行能力)中,GPT‑4.1 取得了 38.3% 的成绩,比 GPT‑4o 提高了 10.5 个百分点。
长文本理解能力:
在 Video-MME 基准测试中(该评测专注于多模态长文本理解),GPT‑4.1 在“长视频、无字幕”类别中取得了 72.0% 的成绩,刷新了业界最高纪录,比 GPT‑4o 提升了 6.7 个百分点。
多模态能力:
GPT-4.1 系列在图像理解方面非常强大,尤其是 GPT-4.1 mini 代表了重大的飞跃,在图像基准测试中经常击败 GPT-4o。
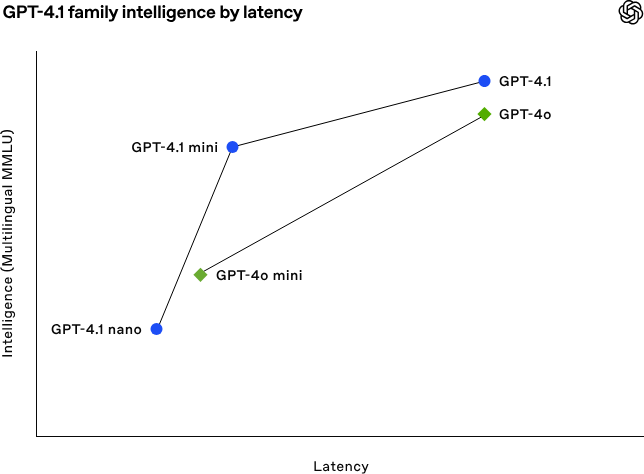
看上图笔者个人推测:本次是性能的优化,能力方面没有突出点,GPT-4o进行工程推理优化变身为GPT-4.1mini,然后GPT-4o经过特定调优,能力稍有提升就是GPT-4.1。
编程能力对比
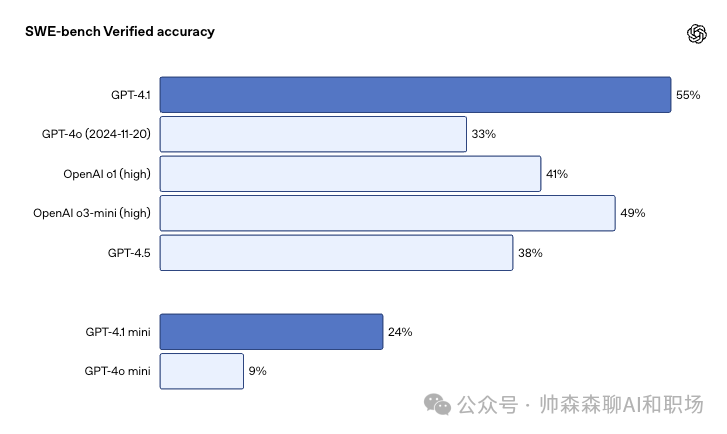
在 SWE-bench Verified 评估中,模型会获得一个代码仓库和一个问题描述,并需生成一个修复补丁来解决该问题。模型表现高度依赖于所使用的提示词和工具。为便于复现和理解我们的结果,我们在此描述了 GPT-4.1 的设置。我们的得分中排除了 500 个问题中的 23 个,因为这些问题的解决方案无法在我们的基础设施上运行;如果保守地将这些题目计为 0 分,总得分将从 54.6% 降为 52.1%。
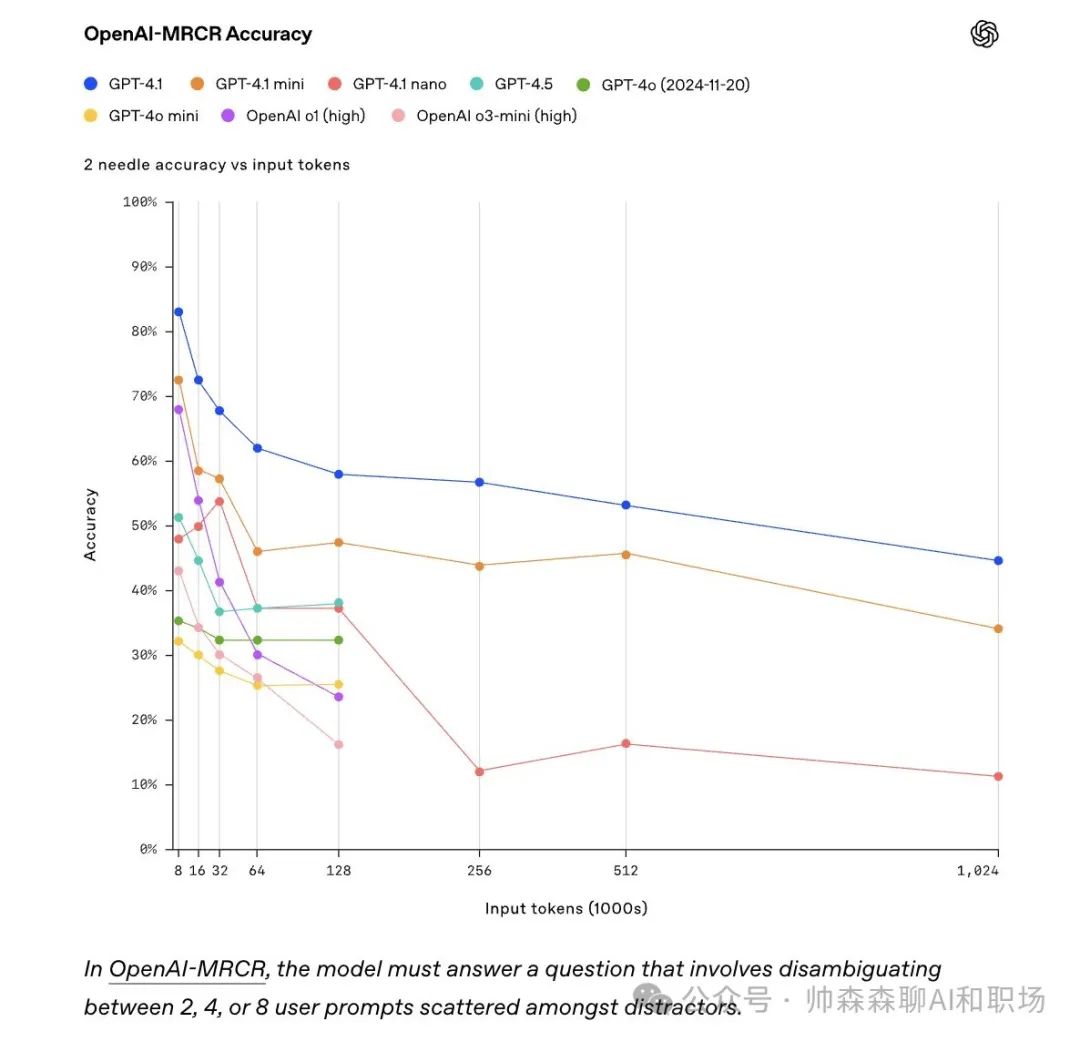
超长上下文处理能力
支持最多 100 万个 token 的上下文处理能力。这对于需要长对话、记忆能力或深入文档处理的应用来说,是一次重大飞跃。而且,它对这些超长上下文的利用效率也更高了。
实例展示
最后,以下是 GPT-4.1 在真实世界中的一个应用示例:
GPT4.1
更多AI内容看👇🏻👇🏻,🔍:ai_service
Deepseek开源后,AI产品二三事:腾讯疯狂、字节知耻后勇

















 1220
1220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









