



身为在法务、商务等领域工作的职场人,你是否在面对堆积如山的合同审查任务时,感到压力山大?传统的人工合同审查方式,不仅耗费大量时间和精力,还容易因人为疏忽而遗漏重要风险点。如今,AI技术的发展为合同审查带来了全新的解决方案。本文将为你介绍如何借助Dify平台,打造一套高效的合同评审工作流,实现合同秒级解析、风险自动标注,大幅提升工作效率。
一、打工人的深夜噩梦:合同评审的三大痛点
在日常工作中,合同评审常常让打工人苦不堪言。想象一下,某天深夜在加班核对合同条款,面对 100 页的合同文件,一页页翻找,眼睛都看花了。突然发现已经修改N版的内容里,有一条款和公司规定冲突,瞬间头皮发麻。这种场景并非个例。传统合同评审存在诸多痛点:
1、人工逐条核对费时费力:一份合同少则十几页,多则上百页,人工核对每一条条款,需要耗费大量时间和精力,效率极其低下。
2、专业条款容易遗漏风险:合同中涉及的专业条款繁多,不同行业、不同类型的合同,条款内容差异较大。由于知识储备和经验的限制,人工审查时很容易遗漏一些潜在的风险点。
3、不同合同格式难以统一:来自不同合作方的合同,格式千差万别,这给审查工作带来了额外的难度,需要花费更多时间去整理和分析。
二、AI 逆袭时刻:合同评审流水线效果展示
如今,AI 技术的应用为合同评审带来了革命性的变化。借助 Dify 平台搭建的合同评审工作流,让评审工作变得如同工厂流水线一样简单高效:
1、效率提升N倍: 以往需要花费数小时甚至数天才能完成的 100 页合同审查工作,现在仅需 10 分钟就能完成初筛,极大地缩短了工作时间。
2、风险零遗漏:通过预设的检查清单,AI 能够自动比对合同中的关键条款,确保所有风险点都被识别出来,避免了人为疏忽导致的遗漏。
3、格式标准化:输出的结构化评审报告,清晰直观地展示合同审查结果,方便后续的分析和处理。
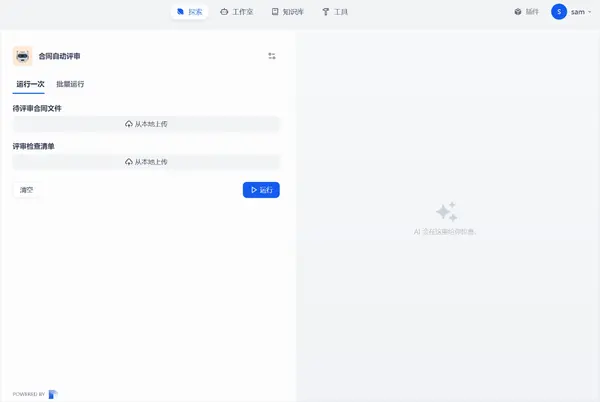
三、手把手教学:5 步搭建智能评审流水线
下面,我们将详细介绍如何使用 Dify 平台,通过 4个步骤搭建起这套智能合同评审流水线。整个工作流的全景为:
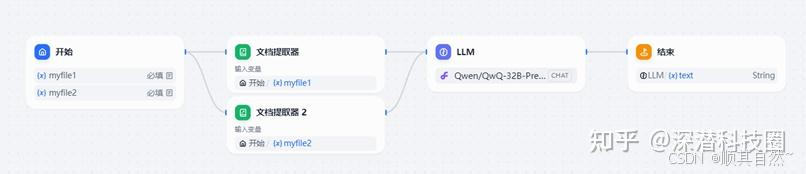
开始节点:上传文件
添加2个文件类型变量,用于将待评审合同和评审检查清单上传到Dify工作流。
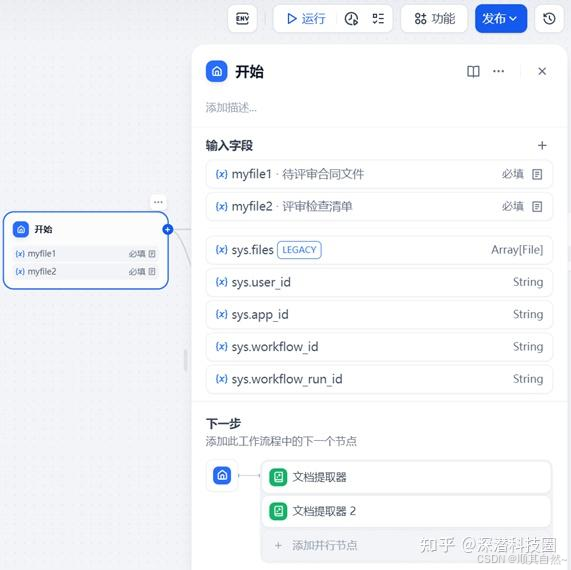
文档提取器节点:智能解析
Dify 平台支持节点并行处理,相当于同时开启了多个 “任务窗口”,大大提高了解析效率。
在合同解析过程中,系统会自动提取合同中的关键信息,如甲方乙方、金额、期限等。
对于检查清单,系统也能自动识别评审要点的编号与内容,为后续的智能评审做好准备。
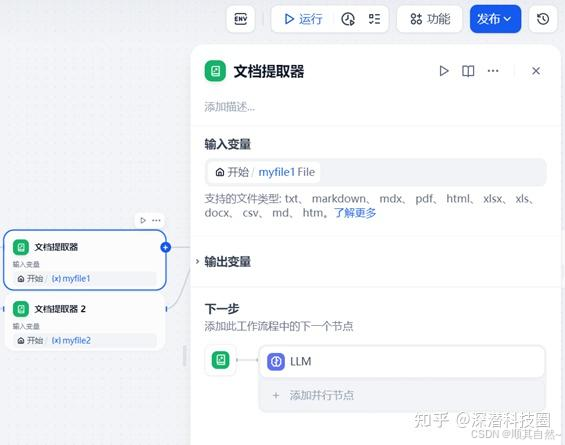
LLM节点:智能评审
在 LLM 配置环节,将检查清单注入上下文,让 AI 能够全面了解评审要求后再对合同内容进行评审。
输出内容采用样例方式进行结构化输出,使得输出结果清晰明了,易于理解。
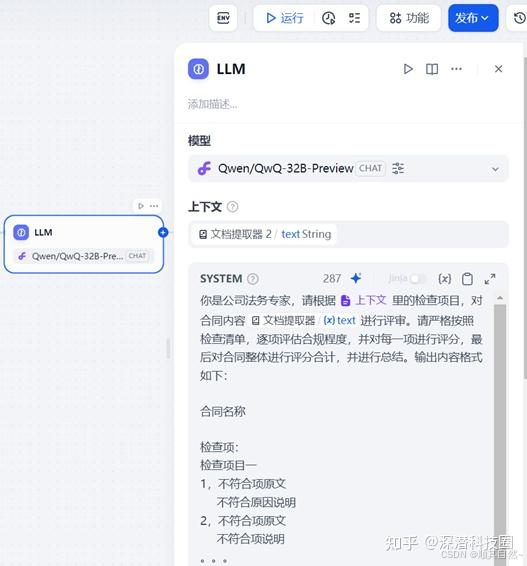
系统提示词样例:
“你是公司法务专家,请根据里的检查项目,对合同内容进行评审。请严格按照检查清单,逐项评估合规程度,并对每一项进行评分,最后对合同整体进行评分合计,并进行总结。输出内容格式如下:
合同名称
检查项:
检查项目一
1,不符合项原文
不符合原因说明
2,不符合项原文
不符合项说明
。。。
检查项评分及修改意见
检查项二
1,不符合项原文
不符合原因说明
2,不符合项原文
不符合项说明
。。。
检查项评分及修改意见
合同总结
合同评审总分及整体评估意见总结“输出节点:结果呈现
将LLM节点的输出文本传递到结束节点的输出变量里。
四、未来进化:合同智能评审的 N 种可能
随着 AI 技术的不断发展,合同评审的未来充满了无限可能:
1、多语言合同支持:在全球化的背景下,多语言合同的审查需求日益增加。合同评审应该支持多种语言,打破语言障碍,实现全球合同的高效审查。
2、自动修订文件:不仅能够识别合同中的风险点,还能根据预设的规则和模板,自动对合同进行修订,提供更加完善的解决方案。
3、集成 OCR 识别扫描件:对于纸质合同,通过集成 OCR技术,实现扫描件的自动识别和审查,进一步扩大 AI 合同评审的应用范围。
4、风险等级智能排序:根据风险的严重程度和影响范围,对识别出的风险点进行智能排序,帮助评审人员优先处理高风险问题。

















 1350
1350

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









