







🚁前言
一年一度的毕业季又来了,应届生也要步入社会了,找工作当然是首当其冲的,仅以此篇软文,为广大应届生送上我一点绵薄之力!
🚁方向
首先,我们抓取数据,要有一个方向;方向:爬什么数据?选用什么网站?爬虫过程是否便利?
🚁工具
selenium (获取网页源代码),因为boss是有比较严格的反爬机制的,用request爬取频繁的话,是会被封禁ip的,你们有条件的,可以购买代理!
🚁Selenium
- 下载webdriver(核心武器,不然跑不了)
我用的谷歌浏览器,大家按照自己浏览器的版本下载对应的driver版本,下载地址
BeautifulSoup(解析数据),这里为什么用bs4呢,说xpath说腻了,看过我文章的朋友都知道,基本上都在讲,这次换个花样,也多一种选择
🚁BeautifulSoup
说白了,BeautifulSoup就是Python的一个HTML或XML的解析库,可以用它方便地从网页中提取数据,同比lxml和正则!
官方说明:
BeautifulSoup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。BeautifulSoup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时你仅仅需要说明一下原始编码方式就可以了。BeautifulSoup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速
- 安装(注意后面还有个4)
pip install beautifulsoup4
🚁网站解析
- 第一步打开浏览器调式,找到数据的标签,复制它,对Ctrl+C,这个就是一个公司招聘信息的标签头,后续通过遍历,就可以拿到每个公司的数据。
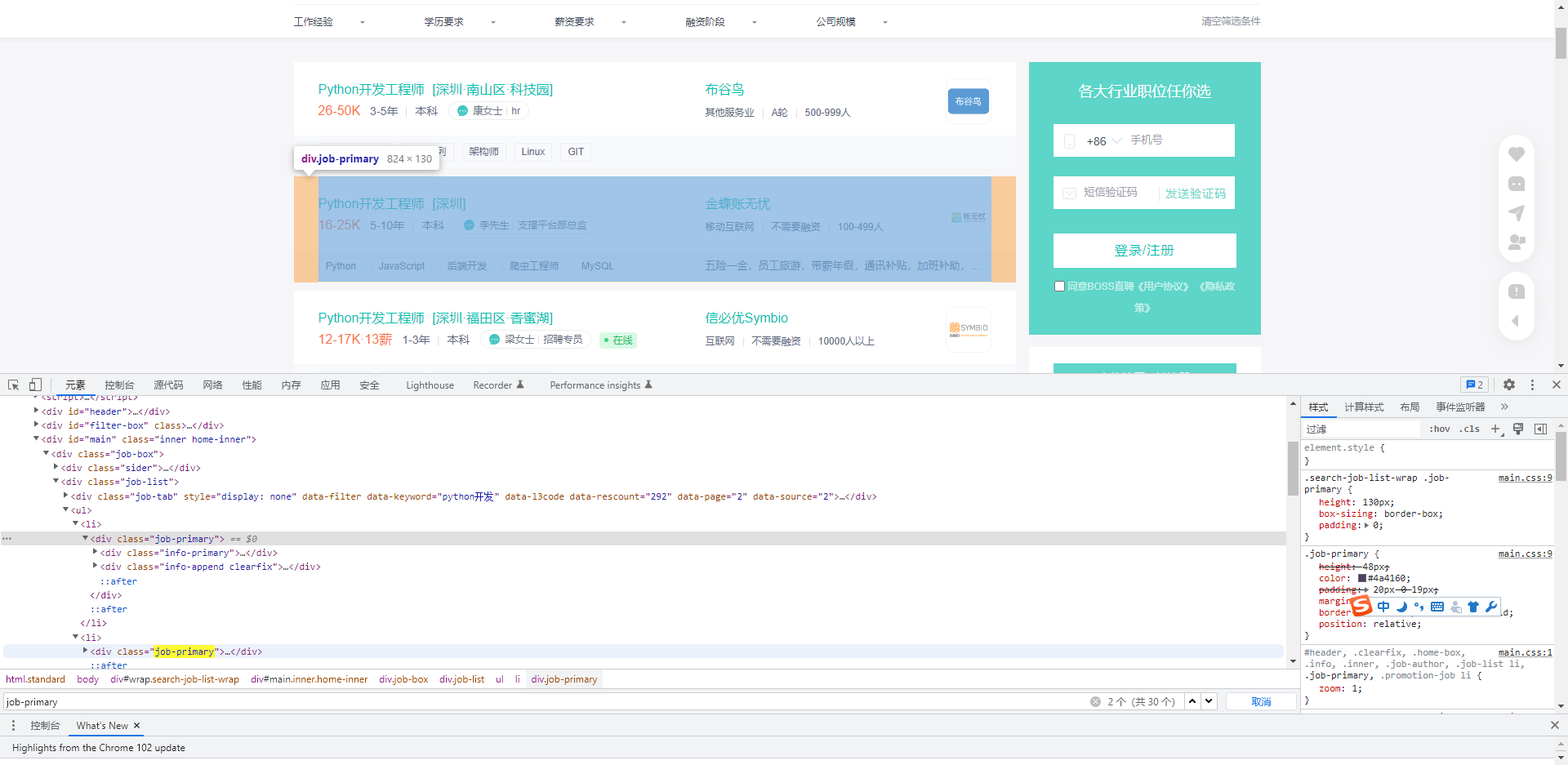
- 以此类推,找到所有数据的html标签,就算完成核心工作了,废话不多说,直接上代码
def parse(job_list,html):
try:
soup = BeautifulSoup(html,"html.parser")
job_all = soup.find_all('div', {"class": "job-primary"})
for job in job_all:
position = job.find('span', {"class": "job-name"}).get_text() #职位
address = job.find('span', {'class': "job-area"}).get_text() #工作地址
company = job.find('div', {'class': 'company-text'}).find('h3', {'class': "name"}).get_text() # 公司
salary = job.find('span', {'class': 'red'}).get_text() #薪水
diploma = job.find('div', {'class': 'job-limit clearfix'}).find('p').get_text()[-2:] # 学历要求
experience = job.find('div', {'class': 'job-limit clearfix'}).find('p').get_text()[:-2] # 工作经验
labels = job.find('a', {'class': 'false-link'}).get_text() # 行业标签
scale = job.find('div', {'class': 'company-text'}).find('p').get_text()[-10:] # 公司规模
job_list.append([position,address,company,salary,diploma,experience,labels,scale])
print(position)
except Exception as e:
print(e)
🚁抓取目标网站
翻页:我们可以通过构造链接,改变page数,来实现翻页的效果
url = "https://www.zhipin.com/c101280600/?query=python%E5%BC%80%E5%8F%91&page="+str(i)+"&ka=page-"+str(i)

前面已经说明,我们用的selenium,所以就轻松抛开那些反爬顾虑,直接大胆放手爬,上代码:
def main():
job_list = [] # 空列表,存放数据
options = ChromeOptions()
options.add_experimental_option('excludeSwitches', ['enable-automation'])
options.add_argument("disable-blink-features=AutomationControlled") # 防止网站发现我们使用selenium
options.add_argument(
'User-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36') # 请求头可加可不加
driver = webdriver.Chrome(options=options)
for i in range(1,5): #
url = "https://www.zhipin.com/c101280600/?query=python%E5%BC%80%E5%8F%91&page="+str(i)+"&ka=page-"+str(i)
driver.get(url)
html = driver.page_source
spider(job_list,html)
#将职位列表信息写入csv文件
headers = ["职位","工作地址","公司全称","薪水","学历","工作经验","行业标签",'公司规模']
with open('招聘信息.csv','w',newline='',encoding='utf8')as f:
j_csv = csv.writer(f)
j_csv.writerow(headers)
j_csv.writerows(job_list)
driver.quit() #关闭浏览器
🚁完整源码
from bs4 import BeautifulSoup
from selenium import webdriver
import csv
import time
from selenium.webdriver import ChromeOptions
def parse(job_list,html):
try:
soup = BeautifulSoup(html,"html.parser")
job_all = soup.find_all('div', {"class": "job-primary"})
for job in job_all:
position = job.find('span', {"class": "job-name"}).get_text()
address = job.find('span', {'class': "job-area"}).get_text()
company = job.find('div', {'class': 'company-text'}).find('h3', {'class': "name"}).get_text()
salary = job.find('span', {'class': 'red'}).get_text()
diploma = job.find('div', {'class': 'job-limit clearfix'}).find('p').get_text()[-2:]
experience = job.find('div', {'class': 'job-limit clearfix'}).find('p').get_text()[:-2]
labels = job.find('a', {'class': 'false-link'}).get_text()
scale = job.find('div', {'class': 'company-text'}).find('p').get_text()[-10:]
job_list.append([position,address,company,salary,diploma,experience,labels,scale])
print(position)
except Exception as e:
print(e)
def main():
job_list = []
options = ChromeOptions()
options.add_experimental_option('excludeSwitches', ['enable-automation'])
options.add_argument("disable-blink-features=AutomationControlled")
options.add_argument(
'User-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36')
driver = webdriver.Chrome(options=options)
for i in range(1,5): # 爬取5页
url = "https://www.zhipin.com/c101280600/?query=python%E5%BC%80%E5%8F%91&page="+str(i)+"&ka=page-"+str(i)
driver.get(url)
html = driver.page_source
parse(job_list,html)
#将jobinfo列表信息写入csv文件
headers = ["职位","工作地址","公司全称","薪水","学历","工作经验","行业标签",'公司规模']
with open('招聘信息.csv','w',newline='',encoding='utf8')as f:
f_csv = csv.writer(f)
f_csv.writerow(headers)
f_csv.writerows(job_list)
driver.quit()
if __name__ == '__main__':
main()
🚁成果

🚁开发
后续开发:岗位要求,岗位职责,工作待遇,公司介绍,敬请期待!
点关注不迷路,本文章若对你有帮助,烦请三连支持一下 ❤️❤️❤️
各位的支持和认可就是我最大的动力❤️❤️❤️

















 8032
8032











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









