









文章目录
一.简介
在2010年, NoSql在国内掀起了一阵热潮, 其中风头最劲的莫过于MongoDB了; 对于 大数据量, 高并发, 弱事务的互联网场景, MongoDB则是很好地应用之地。
1. 扩展性
MongoDB是面向文档的数据库, 不是关系型数据库, 这更加方便扩展. 基本思路就是将原来的"行"(row)的概念换成了更加灵活的"文档"(document). 它所采用的面向文档的数据模型使其可以自动在多台服务器之间分割数据. 它还可以平衡集群的数据和负载,自动重排文档
2. 丰富的功能
很难界定什么才算做一个功能, 这里只说一些MongoDB 真正独特的, 好用的工具
- 索引: 支持通用辅助索引, 能进行多种快速查询, 也提供唯一的, 复合的和地理空间索引能力
- 聚合: 支持MapReduce和其他聚合工具
- 存储Javascript: 可以直接在服务端存取Javascript的函数和值
- 文件存储: MongoDB支持用一种容易使用的协议存储大型文件和文件的原数据
然而有些关系型数据库的常见功能MongoDB并不具备. 比如联接(join)和复杂的多行事务.
3. 不牺牲速度
MongoDB使用MongoDB传输协议作为与服务器交互的主要方式(与之对应的协议需要更多的开销, 如 HTTP/REST).它尽可能的将服务器端处理逻辑交给客户端(由驱动程序或者用户的应用程序处理)
二.查询
1. 简单查询
>db.users.find()
四种比较操作符: “
l
t
"
<
小于
,
"
lt" < 小于 , "
lt"<小于,"lte” <= 小于等于, “$ gt” > 大于, “
g
t
e
"
>
=
大于等于
,
另外还有
"
gte" >= 大于等于, 另外还有 "
gte">=大于等于,另外还有"ne” 不相等
例如 查询18~30岁(包含)的用户
>db.users.find({"age" : {"$gte" : 18 , "$lte" : 30}})
2. 指定返回的键
有时并不需要将文档中所有的键/值对都返回.遇到这样的情况, 可以通过find(或者findone)的第二个参数来指定想要的键. 这样做既会节省传输的数据量, 又能节省客户端解码文档的时间和内存消耗
>db.users.find({},{"username" : 1, "email" : 1, "_id" : 0})
上面第二个参数 1:表示返回此键, 0:表示不返回此键

值得注意的是, 如果一个字段里面 是null, 那么使用 >db.c.find({"y" : null}) 查询的话, 可以匹配到位 null的值, 但是还会匹配"不存在的". 所以这种匹配还会返回缺少这个键的所有文档
3. 正则表达式
MongoDB使用Perl兼容的正则表达式(PCRE, 介绍)库来匹配正则表达式, 建议在查询中使用正则表达式前, 先在JavaScript shell 中检查一下语法, 确保匹配与设想的一致. 系统可以接受正则表达式标识(i), 但不一定要有
>db.user.find({"name" : /joey?/i})
四.游标
1. limit, skip, sort
语句比较简单
db.user.find({"username" : "demo"}).limit(50).sort({"number": -1})
值得注意的是: 避免使用skip略过大量的结果. 用skip略过少量的文档还是不错的. 但是要是数量非常多的话, skip就会变得很慢(几乎每个数据库都有这个问题, 不仅仅是MongoDB), 所以要尽量避免. 通常可以内置查询条件, 来避免过大的skip, 或者利用上次的结果来计算下一次的查询
五.索引
mongodb的索引几乎与传统的关系型数据库索引一模一样, 绝大多数的优化索引技巧也同样适用于MongoDB; 创建索引的缺点就是每次插入, 更新 和删除时都会产生额外的开销.每个集合默认的最大索引个数为64个.
db.people.ensureIndex({"username" : 1}) "1"表示索引方向, 正序还是倒序, 单索引方向无关紧要
1. 索引内嵌文档中的键
为内嵌文档的键建立所以和为普通的键创建索引没有什么区别.
db.blog.ensureIndex({"comments.date" : 1})
2. 为排序创建索引
随着集合的增长, 需要针对查询中大量的排序做索引. 如果对没有索引的键调用sort, MongoDB需要将所有数据提取到内存来排序, 因此 无索引排序是有个上限的, 那就是不可能在内存里面做T级别数据的排序. 一旦集合大到不能在内存中排序, MongoDB就会报错.
3. 使用explain 和 hint
和mysql一样, MongoDB也有检查执行语句细节的关键字
重点关注的是COLLSCAN、IXSCAN、keysExamined、docsExamined 等关键字。(每个版本也会不同)
keysExamined 和 docsExamined 越大代表没有建索引或者索引的区分度不高。请确认索引的创建字段。
1、COLLSCAN:代表该查询进行了全表扫描;
2、IXSCAN:代表进行了索引扫描;
3、FETCH: 根据索引指向的文档的地址进行查询(相当于mysql中的回表查询)
4、PROJECTION_COVERED:映射覆盖,不需要回表查询
5、SORT: 需要再内存中排序,效率不高
6、keysExamined:代表索引扫描条目;
7、docsExamined:代表文档扫描条目。
db.xxx.find().explain();
[
{
'queryPlanner': {
'plannerVersion': 1,
'namespace': "download.user", ---命令空间
'indexFilterSet': false,
'parsedQuery': {
},
'queryHash': "8B3D4AB8", --- 一个十六进制字符串用于表明query shape的hash
'planCacheKey': "8B3D4AB8",
'winningPlan': {
'stage': "COLLSCAN", --- 阶段名称 全表扫描, 每个阶段都有每个阶段特有的信息。 例如,IXSCAN 阶段将包括索引边界以及特定于索引扫描的其他数据。
'direction': "forward"
},
'rejectedPlans': [
]
},
'ok': 1.0,
'$clusterTime': {
'clusterTime': Timestamp(1661909254,4),
'signature': {
'hash': BinData(0,"Gy0G7+q+Cho5dvqs0mUDaUEcuKs="),
'keyId': NumberLong(7102478106182549505)
}
},
'operationTime': Timestamp(1661909254,4)
}
]
db.xxx.find({_id: 72286850}).explain();
[
{
'queryPlanner': {
'plannerVersion': 1,
'namespace': "download.goods",
'indexFilterSet': false,
'parsedQuery': {
'_id': {
'$eq': 72286850
}
},
'queryHash': "A300CFDE",
'planCacheKey': "A2B33459",
'winningPlan': {
'stage': "IDHACK"
},
'rejectedPlans': [
]
},
'ok': 1.0,
'$clusterTime': {
'clusterTime': Timestamp(1661909797,7),
'signature': {
'hash': BinData(0,"s1T75UpG6n4y+vR/MOWLt5GnKvQ="),
'keyId': NumberLong(7102478106182549505)
}
},
'operationTime': Timestamp(1661909797,7)
}
]
如果发现MongoDB用了非预期的索引, 可以用hint强制使用某个索引. 多数情况下 这种指定没什么必要. MongoDB的查询优化器非常智能, 会替你选择该用哪个索引.初次做某个查询时, 查询优化器会同时尝试各种查询方案. 最先完成的被确定使用, 其他的则终止掉.
db.source_audit_tag.find({"_id": 72286850}).hint({"_id": 1});
聚合工具中的明星 - MapReduce
count, distinct, group 能做的上述事情 MapReduce都能做. 它会拆分问题, 再将各个部分发送到不同的机器上, 让每台机器都完成一部分, 当所有机器都完成的时候, 在把结果汇集起来形成最终完整的结果. MapReduce虽然操作方便, 但代价就是速度: group不是很快, MapReduce 更慢
固定集合
MongoDB除了可以动态创建集合外, 还可以创建固定大小的集合, 只是需要事先创建
db.createCollection("fixation_coll", {capped: true, size: 100000, max: 5});
固定集合很像环形队列, 如果空间不足, 则会删除最早插入的文档, 为新文档插入腾出空间. 这就意味着固定集合在新文档插入的时候自动淘汰最早的文档
固定集合默认是没有索引的, 即使"_id"上也没有索引. 它有俩点优势,
1. 在固定集合插入文档时, 速度极快,因为无需分配额外的空间,
2. 在按照插入的顺序输出时的查询速度也很快
使用场景就很类似日志的存储, 也可以用在存储少量的文档场景中
六.复制
MongoDB不仅可以用复制来应对故障切换, 数据集成, 还可以用来做读扩展, 热备份 或作为离线批处理的数据源.
1.主从复制
主从复制时MongoDB最常用的复制方式, 这种方式非常灵活, 可用于备份, 故障恢复, 读扩展等,可以自行下载安装包试试
主节点启动:
./mongod --dbpath=/Users/csdn/software/mongodb-4.2/data/ --logpath=/Users/csdn/software/mongodb-4.2/data/mongodb.log --bind_ip=0.0.0.0 --port=27017 --logappend&
目前还没有能够从从节点复制的机制, 一个集群中有多少个从节点并没有明确的限制, 但是上千个从节点对单个主机点发起查询也会让其吃不消. 所以实际中, 不超过12个从节点的集群就可以运转良好了.
2.副本集
副本集(Replica Set) 就是有自动恢复功能的主从集群. 主从集群和副本集最为明显的区别是副本集没有固定的"主节点":
整个集群会选举出一个"主节点", 当其不能工作时,则变更到其他节点.
任何时间,集群只有一个活跃节点, 其他的都为备份节点.有几种不同类型的节点可以存在副本集中
- standard
这种就是常规节点, 它存储一份完整的数据副本, 参与选举投票, 有可能成为活跃节点
- passive
存储了完整的数据副本, 参与投票, 不能成为活跃节点
- arbiter
仲裁者只参与投票, 不接收复制的数据集, 也不能成为活跃节点
3.主从节点复制原理
主节点的操作记录称为`oplog`(`operation log` 的简写). `oplog`存储在一个特殊的数据库中, 叫做`local`.
`oplog`就在其中的`oplog.$main`集合里面. `oplog`中的每个文档都代表主节点上执行的一个操作.
需要重点强调的是oplog只记录改变数据库状态的操作. 比如, 查询就不再存储在oplog中. 这是因为oplog只是作为从节点与主节点保持数据同步的机制
另外要注意的是, oplog存储在固定集合中. 由于新操作也会存储在oplog里, 它们会自动替换旧的操作.
3.1 同步
从节点第一次启动时,会对主节点数据进行完整的同步.从节点会复制主节点上的每个文档. 同步完成后, 从节点开始查询主节点的oplog并执行这些操作, 以保证数据是最新的.
如果从节点的操作已经被主节点落下很远了, 从节点就跟不上同步了.从节点发生了宕机或者疲于应付读取时就会出现这种情况.
当从节点跟不上同步时, 复制就会停下, 从节点需要重新做完整的同步. 而完整的同步代价是高昂的. 所以需要尽量避免,方法就是配置足够大的oplog
七.分片
分片(sharding)是指将数据拆分, 将其分散存在不同的机器上的过程. 有时也用分区(partitioning)来表示这个概念. MongoDB支持自动分片, 可以摆脱手动分片的管理困扰. 集群自动切分数据,做负载均衡.
MongoDB自动分片
MongoDB分片的基本思想就是将集合切分成小块.这些块分散到若干片里面,每个片只负责总数据的一部分.而应用不必知道哪片对应哪些数据,
所以分片之前要运行一个路由进程, 该进程名为mongos.这个路由器知道所有数据存放的位置,所以应用可以链接它来正常发送请求.
而在没有分片时,客户端连接mongo进程.
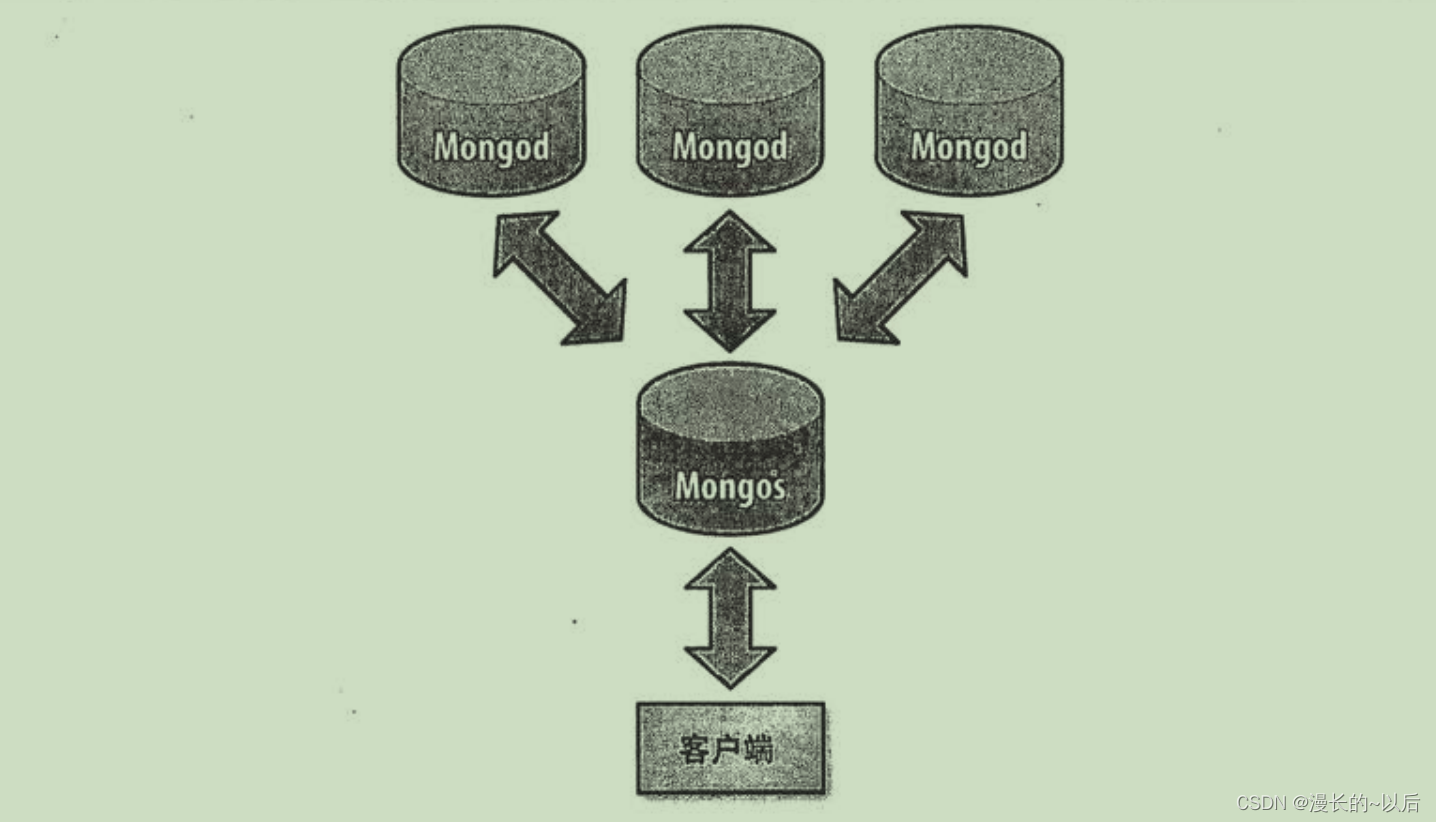
问题1: 何时分片?
常见问题就是什么时间开始分片呢. 出现下面的信号时, 就要考虑使用分片了
- 机器的磁盘不够用了
- 单个
mongod已经不能满足写数据的性能需要了 - 想将大量数据放在内存中提高性能
问题2: 怎么分片?
设置分片时, 需要从集合里面选一个键, 用该键的值作为数据拆分的依据, 这个键称为片键(shard key)
问题3: 递增片键还是随机片键?
片键的选择决定了插入操作在片之间的分布情况.
例: 如果选择像"timestamp" 这样的键, 这个值很可能不断增长, 就会将所有数据发送到一个片上(就是包含某个时间以及以后 [2022-09-16, 无穷]).
也就是顺序插入.顺序插入的好处是按照片键查询会非常高效;但不适合写入负载很高的情况,因为都集中在一个分片
所以需要处理负载比较高的情况, 就是均匀分散负载到各个片, 就得选择分布均匀的片键.
选择片键并创建片键很像建索引, 因为二者原理类似,事实上, 片键也是最常用的索引.
八.处理技巧
批量插入比单条插入效率更高
一次批量插入只是单个的TCP 请求, 也就是避免了许多零碎的请求所带来的开销. 由于无需处理大量的消息头, 这样能减少插入时间.
插入文档的大小限制
批量插入的消息最大长度为16MB, 单条文档插入消息的不超过4MB(mongodb 1.8版本). (4MB 是个多大的空间呢, 要知道整部<<战争与和平>>也才3.14MB)
注入式攻击
MongoDB只是简单的将文档原样存入数据库中, 插入时并不执行代码, 所以这块没有注入式攻击的可能. 副作用就是允许插入无效的数据.
关于删除
语句: > db.users.remove()
上面的语句会删除集合中所有文档, 但不会删除集合本身, 原有的索引也会保留
删除数据是永久性的, 不能撤销, 也不能恢复. 删除文档通常会很快, 但是要清除整个集合, 直接删除集合(drop, 然后重建索引)会更快;
链接池
Java, Python 和 Ruby 这几个语言的驱动程序都使用了连接池, 为了提高效率, 这些驱动程序和服务器建立了多个连接(一个连接池), 并将请求分散到这些连接中去
参考
<<MongoDB权威指南>>
https://blog.csdn.net/mijichui2153/article/details/115680742
















 891
891











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











