







 Ariane是一款开源的64位(可配置为32位)处理器,采用6级流水线设计,包括PC生成、指令取指、指令解码等阶段。分支预测通过BHT和BTB实现,预测分支方向和目标地址。指令解码处理压缩指令并对指令进行对齐和解压缩。整个设计旨在支持操作系统高效运行。
Ariane是一款开源的64位(可配置为32位)处理器,采用6级流水线设计,包括PC生成、指令取指、指令解码等阶段。分支预测通过BHT和BTB实现,预测分支方向和目标地址。指令解码处理压缩指令并对指令进行对齐和解压缩。整个设计旨在支持操作系统高效运行。
- 总体设计
Ariane处理器是一个开源的顺序单发射64位处理器(也可以配置成32位处理器),实现了RV64GC指令集。它有六级流水:
PC Generation
Instruction Fetch
Instruction Decode
Issue Stage
Execute Stage
Commit Stage
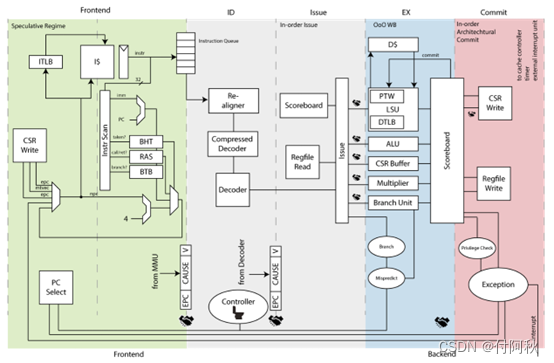
图 1 Ariane内核结构
其中,前两级流水被称为处理器的前端,后四级流水被称为处理器的后端。Ariane处理器的目标是在合理的速度和IPC(Instruction per Cycle)下,运行一个完整的操作系统。为了达到期望的速度,cva6内核采用了6级流水线的设计。在访问命中的情况下,IMEM或L1 ICache的访问延时为1 cycle,DMEM或L1 DCache的访问延时为3 cycle.
- Frontend
2.1 PC Generation
2.1.1 PC生成
PC程序计数器,负责产生下一个程序地址,进行逻辑寻址,如果逻辑到物理的映射改变了,指令应该刷新流水线和TLB。TLB是缓存PTE的cache,PTE是用于存储物理存储器和虚拟存储器映射的多级页表中的表项。
Next PC的来源如下:
(0)Default assignment/replay instruction,
(1)Branch Predict taken,分支预测
如果BHT和BTB在一个正确的PC上预测出了一个分支,PC Gen会将下一个 PC值设置为上述分支预测到的地址,并通知IF阶段。在后续的不同阶段都需要通知 (例如在对预测失败进行纠正时)。
(2)Control flow change request (misprediction),控制流变更请求(预测失败)
如果分支预测器预测错误,就会发生控制流更改请求。预测失败可能是预测错误,也可能出现分支无法识别的情况,需要清洗流水线,获取正确的地址。
(3) Return from environment call,从环境呼叫返回
(4) Exception/Interrupt,异常/中断
如果发生异常(或中断),PC Gen将生成下一个PC作为traps向量基地址的一部分。根据处理器的工作模式(ariane目前不支持cva6用户模式异常),traps向量基地址可能会不同。CSR单元会找出traps的位置,并计算出正确的地址传输给PC Gen
(5)Pipeline Flush because of CSR side effects,CSR段异常进行流水线冲洗
(6)Debug
Debug优先级最高,因为它可以中断任何控制流请求。它也是控制流更改的唯一来源,实际上可以同时发生任何其他强制控制流更改。调试单元报告更改PC的请求以及更改CPU的PC。
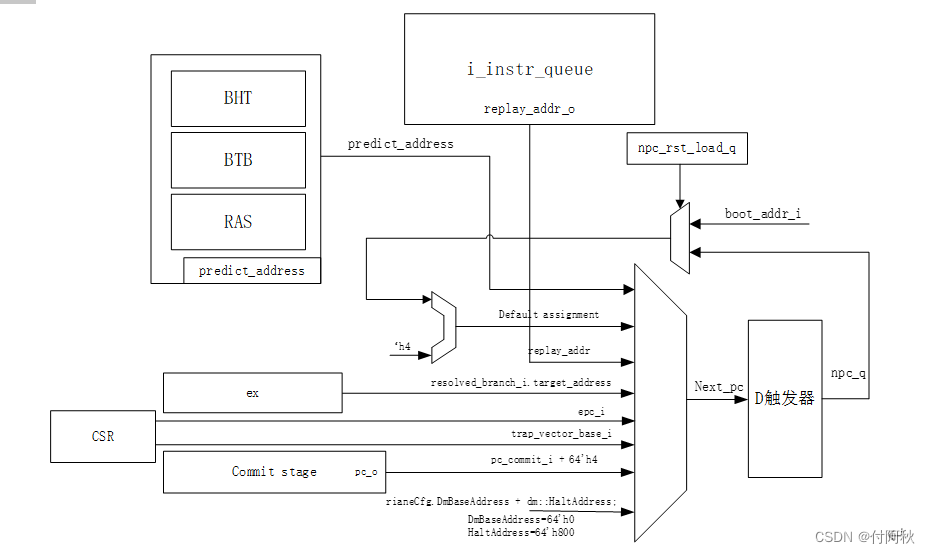
图 2 PC生成
2.1.2 Branch Prediction
分支预测之所以能够实现,是由分支指令的特性决定的,因为分支预测本质上是对分支指令的结果进行预测,而在一般的RISC指令集中,
分支指令包含两个要素:
1、方向,对于一个分支指令来说,它的方向只可能有两种,一种是发生跳转(taken),另一种是不发生跳转(not taken)。
2、目标地址,目标地址在指令中有两种存在形式。
(1)PC relative,也称做直接跳转(direct)。在指令中直接以立即数的形式给出一个相对于PC的偏移值(offset),当前分支指令的PC值(或者分支指令的下一条指令的PC值)加上这个偏移值就可以得到分支指令的目标地址。
(2)Absolute,也称做间接跳转(indirect)。分支指令的目标地址来自于一个通用寄存器的值,这个寄存器的编号由指令给出。由于寄存器的值是会经常变化的,因此这种类型的分支指令很难对目标地址进行预测,但程序当中大部分间接跳转的分支指令都是用来调用子程序的Call/Return类型的指令,而这种类型的指令由于有着很强的规律性,是容易被预测的。
2.1.2.1分支历史表
PHT(Pattern History Table,分支历史表)(ariane中这个部件称为BHT(Branch History Table))是一个包含部分PC值对应的两位饱和计数器的值的表格,一般是在流水线的提交(Commit)阶段更新,即在分支指令要离开流水线的时候进行更新。所有的分支预测数据结构都驻留PHT中。它用PC的适当位数索引,包含关于预测目标地址的信息,以及可配置宽度饱和计数器(saturation counter)(默认为2)的结果,其预测结果用于后续阶段的跳转(或不跳转)。 compress字段用于16位压缩指令集实现分支时候使用。
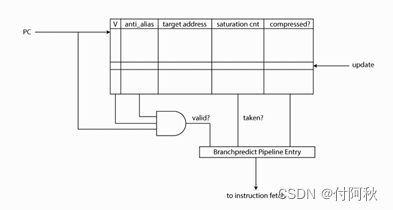
图 3 PHT预测原理图
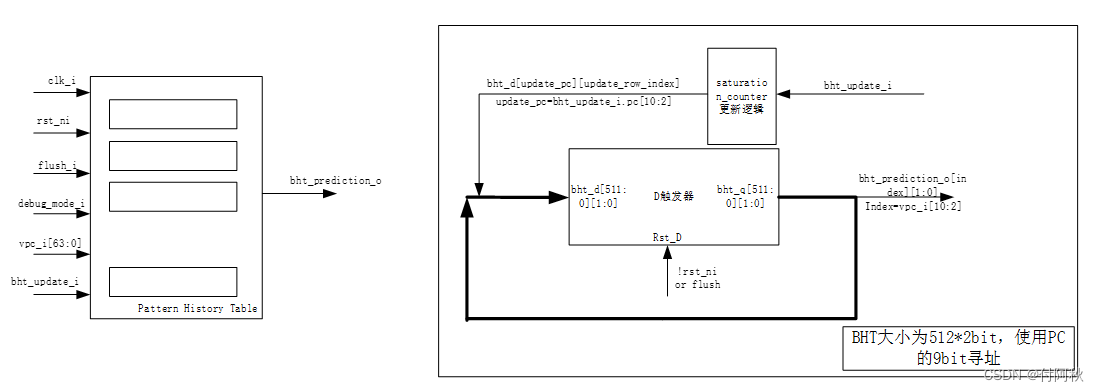
图 4 PHT电路链接关系
2.1.2.2分支指令的方向预测
两位饱和计数器是一种分支方向预测的实现方法,根据前两次的执行结构预测本次的方向,是一种很简单的分支预测方法。
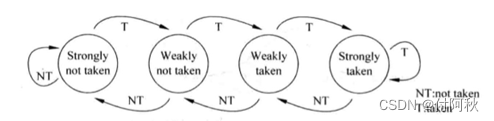
图 5 二位饱和计数器
在图中,PHT是一个表格,在其中存放着所有PC值所对应的两位饱和计数器的值,例如图4.10中使用PC值当中的k位来寻址PHT,因此PHT的大小就是2^k x 2bit。
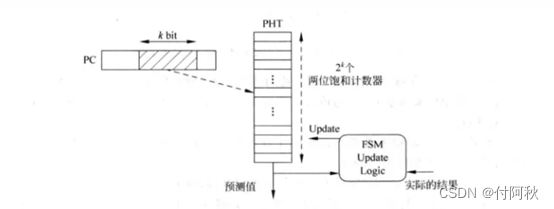
图 6 PHT方向预测结构图
对于分支指令有规律的(如TNTNTN),可以使用一个分支历史寄存器(Branch History Register,BHR)来记录一条分支指令在过去的历史状态进行分支预测。其他分支方向预测的实现方式还有基于全局历史的分支预测、竞争的分支预测。
2.1.2.2分支指令的目标地址预测
对于直接跳转(PC-relative)类型的分支指令来说,它的目标地址有两种情况:
(1)不发生跳转,目标地址 = 当前分支指令的PC值 + Sizeof(fetch group)。
(2)发生跳转,目标地址 = 当前分支指令的PC值 + Sign_extend(offset)。
BTB
由于分支预测是基于PC值进行的,不可能对每一个PC值都记录下它的目标地址,所以一般都使用Cache的形式,使多个PC值共用一个空间来存储目标地址,这个Cache称为BTB(Branch Target Buffer,分支目标缓冲区),图表示了采用直接映射结构的BTB的示意图。
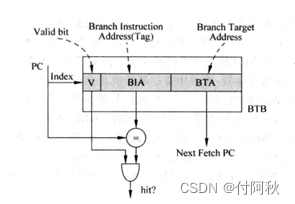
图 7 BTB预测原理图
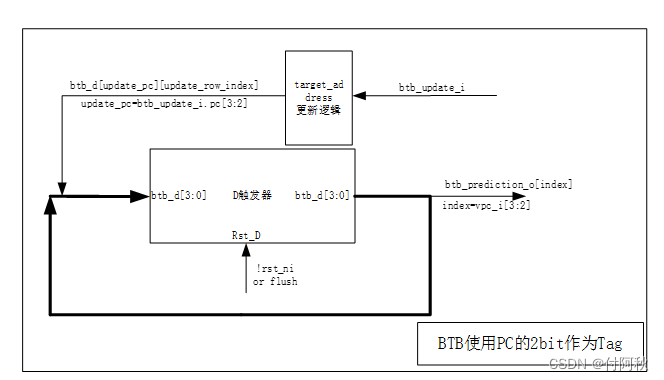
图 8 BTB电路链接关系
多个PC共用一个空间来存储目标地址,会用Tag来区分。除了提供预测结果外,BTB还会更新其错误预测的信息。
寻址位数Index为2,取PC[3:2]。
Tag位数32-2-2=28位。
分支结果和分支目标地址在相同的运算单元中计算,因此对目标地址的错误预测与对分支方向的错误预测代价相当。在PHT中,多个PC共用会出现干扰,这种情况称为别名(aliasing)。为了防止别名发生(或者至少使它更不可能发生),需要使用一些标记位,并在每次访问时进行比较。 tag、index和offset三者组合就可以确定一个唯一的地址了。因此,当我们根据地址中index位找到cache line后,取出当前cache line对应的tag,然后和地址中的tag进行比较,如果相等,这说明cache命中。如果不相等,说明当前cache line存储的是其它地址的数据,这就是cache缺失(cache miss)。
对于间接跳转。CALL指令一般用于调用子程序。一条CALL指令调用的子程序是固定的,也就是说一条CALL指令对应的目标地址是固定的,因此可以使用BTB对CALL指令的目标地址进行预测,如图4.38所示给出了一个例子。
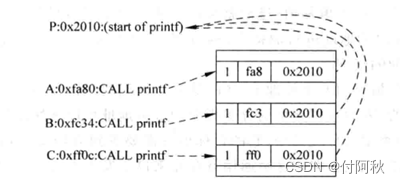
图 9 printf指令调用
但是对于一个子函数来说,例如printf函数,有很多地方都可以调用它,因此printf函数执行到最后一条Return指令的时候,返回的地方是会变化的。正因为Return指令的目标地址是不确定的,因此无法使用BTB对它的目标地址进行预测,但是可以看出,Return指令的目标地址总是等于最近一次执行的CALL指令的下一条指令的地址,如图所示。
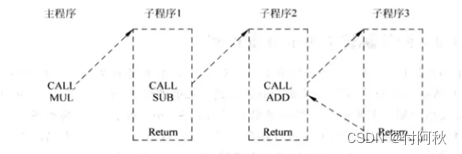
图 10 return/cell指令调用
根据Return指令的上述特点,可以设计一个存储器,保存最近执行的CALL指令的下一条指令的地址,这个存储器是后进先出的,称之为RAS(Return Address Stack)
RAS(Return Address Stack,返回地址堆栈),在间接跳转指令中,大部分都是对子程序调用的CALL/Return指令,在这部分的分支预测中,子程序的嵌套使用RAS进行存储和返回。
2.2 Instruction Fetch
2.2.1取指
指令取指阶段IF从PC Gen阶段获取其信息。此信息包括关于分支预测的信息,当前PC值,以及该请求是否有效(valid)等。IF阶段请求MMU在PC的基础上进行虚拟地址到物理地址的转换,并调用I$(指令缓存,ICache)接口。
IF阶段向I$接口发出信号,表示它想要对内存进行取指请求。根据I$的状态,可以允许或不允许。如果允许,指令会被放入缓存FIFO中。cva6允许I$中最多有2件未完成的事务,如果多于2件,IF阶段则不会向PC Gen发送新的请求。
2.2.2 Instruction Scan
该子模块旨在对指令类型做一个初步的判断,是纯组合逻辑。

图 12 instr_scan代码接口
以instr_scan代码为例进行说明,输入为指令,输出是对指令类型的判断:
代码路径:core/frontend/instr_scan.sv

2.2.3 Instruction Queue
该队列用于处理器前端的IF阶段和后端的ID阶段之间的指令通信,解耦合(使得两者关联性下降),将指令前端和处理器后端分开。
由于压缩指令的存在,取指可能最多存在两条指令(两个完整16位指令)。同时该队列还实现了一个并串转换,使得后端只处理一条指令,与压缩指令相关。指令队列中内部有两个FIFO,fifo_instr用来存指令,fifo_address用来存分支预测的地址。该指令队列用了Replay机制。
Replay机制:如果取指之后指令队列满了,没有成功放入队列中,那么处理器的IF阶段会选择重新取指。
queue深度可以从0到2**32任意取值,cva6中设置深度为4,数据宽度默认32bit,address queue数据宽度为64bit。
三、Instruction Decode
指令解码是处理器后端的第一个流水线阶段。它的主要目的是从IF阶段获得的数据流中提取指令,解码后发送到Issue(发射)阶段。
随着压缩指令的引入,ID阶段变得更加复杂:它必须搜索传入的数据流寻找潜在的指令,重新对齐,并(在压缩指令的情况下)解压缩它们。此外,我们将在此阶段结束时知道被解码的指令是否为分支指令,它将此信息送到Issue(发射)阶段。
3.1 Instruction Re-aligner
这个模块的输入是32-bit对齐的cache block,其功能是从中提取出指令。由于cva6支持压缩指令集,所以一次输入中最多可以包含两条指令:

图 13 5种指令情况
如上图所示,一个cache block内的指令有可能出现以下5种情况:
1、输入的cache block是一条完整的32bit指令。
2、输入的cache block的位域[31:16]是一条32bit指令的低16bit;位域[15:0]是一条32bit指令的高16bit。
3、输入的cache block的位域[31:16]是一条32bit指令的低16bit;位域[15:0]是一条完整的16bit指令。
4、输入的cache block的位域[31:16]是一条完整的16bit指令;位域[15:0]是一条32bit指令的高16bit。
5、输入的cache block的位域[31:16]是一条完整的16bit指令;位域[15:0]是一条完整的16bit指令。
如果上一条是Branch指令且发生了跳转(taken),我们有可能需要从一个非32-bit对齐(但是16-bit对齐)的地址进行取指。
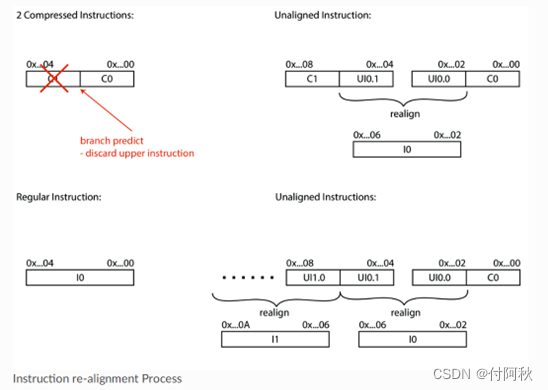
图 14 连续指令出现的4种情况
如上所述,指令重对齐模块检查传入的数据流是否压缩指令。压缩指令的最后一位不等于11,而普通32位指令的最后两位为11。解码阶段的复杂性主要来自:压缩指令会使普通指令32bit不对齐(16bit是对齐的)。这可能在指令完全解码之前进行两次内存访问,因此,我们需要确保指令FIFO有足够的空间来保存指令的第二部分。因此,指令重对齐模块需要跟踪前一条指令是未对齐的还是被压缩的,以正确地决定如何处理即将到来的指令。
在cva6代码中,重排列模块被放在Frontend。
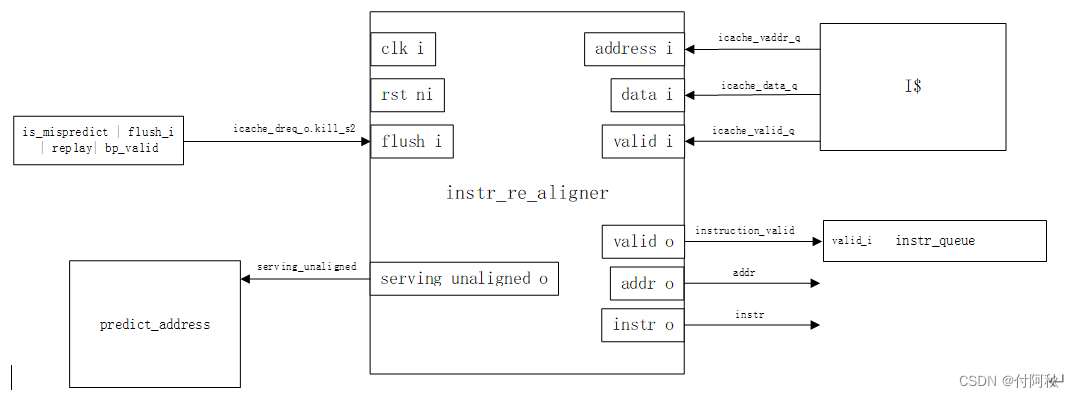
图 15 instr_re_aligner链接关系
3.2 Compressed Decoder
对于压缩指令集,还需要解压所有的压缩指令。通过组合电路来完成,该电路将一个16位的压缩指令扩展到其等效的32位。所有的压缩指令都有一个等价的32位指令

图 16 compressed decode接口
compressed_decoder:检查它们是否被压缩,如果被压缩则进行扩展
完全组合逻辑,根据instr[1:0]直接判断是否为压缩指令并进行扩展输出。对应压缩指令在文件riscv_pkg.sv
3.3 Decoder
解码器会接收原始指令数据,或接收16位对应的未压缩等价指令(该模块会根据情况对指令进行保存,同样会接收16位压缩指令,用于保存),并解码它们。它将原始比特转换为Ariane中最基本的控制结构,即scoreboard (记分牌):
PC:指令PC
FU:使用功能单元
OP:各功能单元要执行的操作
RS1:注册源地址1
RS2:注册源地址2
RD:注册目的地址
Result:对于未完成的指令,该字段还保存立即指令
Valid:结果有效
Use I Immediate: 我们应该使用立即操作符作为操作数b吗?
Use Z Immediate:将立即数z作为操作数a
Use PC:如果我们需要使用PC作为操作数a,则异常中设置PC
Exception:发生异常
Branch predict:分支预测scoreboard数据结构
Is compressed:表示压缩指令,如果需要进行跳转,则在提交阶段需要此信息,例如:+4,+2
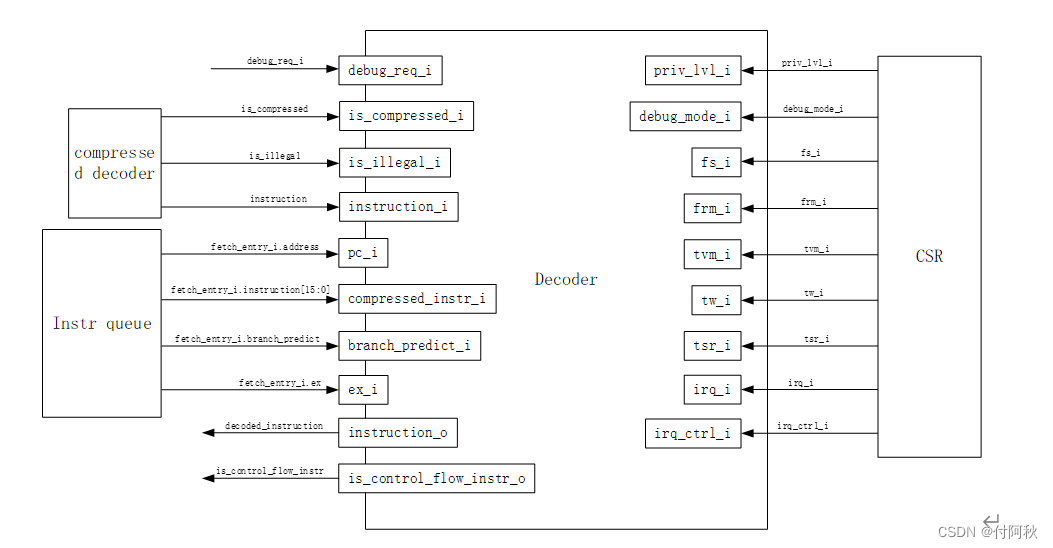
图 17 Decoder链接关系
四、Issue Stage
Issue(发射)阶段的目的是接收解码后的指令并将其发送给各个功能单元(FU,Functional Unit)。此外,Issue(发射)阶段跟踪所有发出的指令、功能单元状态并接收来自执行阶段的回写数据。
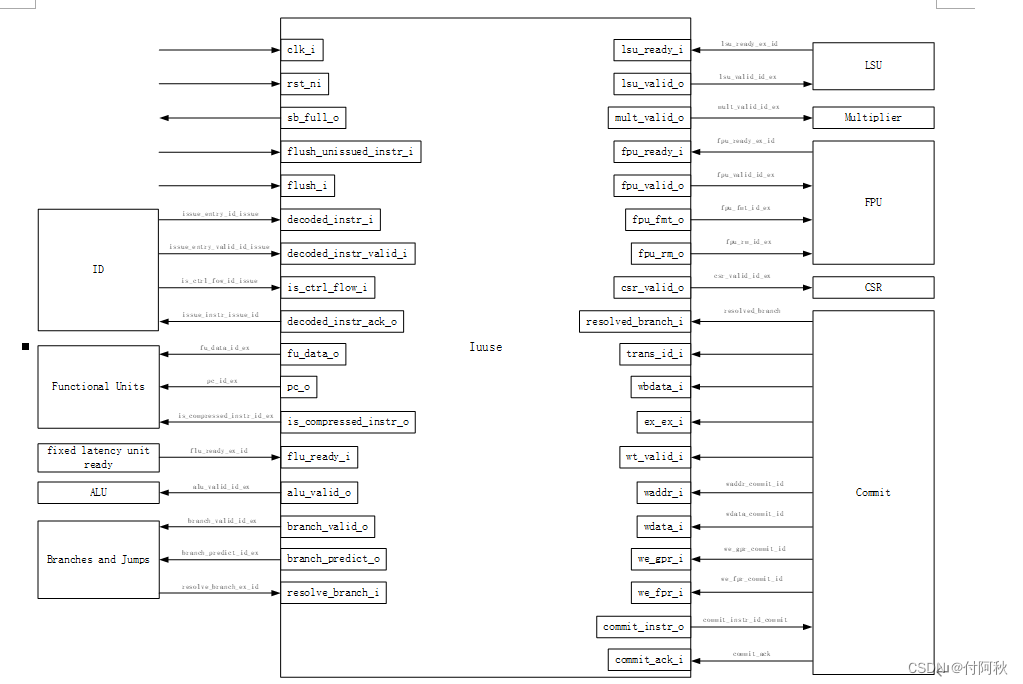
图 18 Issue链接关系
Issue(发射)阶段包含CPU的寄存器文件。通过使用scoreboard,记录发出了哪些指令、指令所在的功能单元以及指令回写到哪个寄存器。如果将执行大致分为四步:发射、读源操作数、执行、写回目的操作数。那么Issue stage负责处理其中三步:发射、读源操作数、写回目的操作数。

图 19 Issue包含的3个阶段
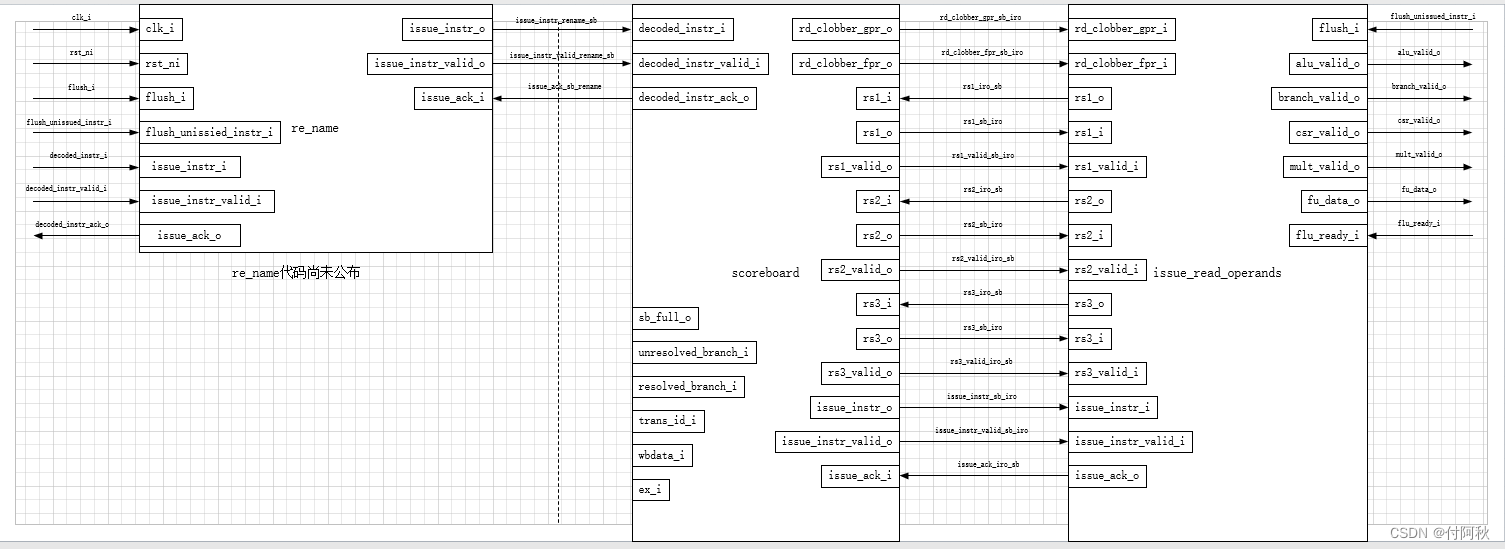
图 20 re_name--Scoreboard--issue_read_operands
4.1 Issue
当Issue(发射)阶段得到一个新的解码指令时,它检查所需的功能单元是否空闲或将在下一个周期中空闲。然后它检查它的源操作数是否可用、当前有无其他被发射的指令会写入相同的目的寄存器,即检查是否存在:
| 信号名称 | 信号功能描述 |
| 结构冒险 | 对应的FU是否空闲、或者是否即将在下个cycle空闲。 |
| RAW数据冒险 | 源操作数是否已经准备好了 |
| WAW数据冒险 | 是否没有其他正在发射的指令会写回到同一个目的寄存器 |
| 控制冒险 | Issue stage追踪指令以保证没有发射未解决的分支指令。此处逻辑在目前的硬件上需要简化。我们一次只允许执行一条分支指令,这种做法使得在发生分支误预测的时候能很容易地恢复。 |
ariane处理器的寄存器重命名尚在开发中,虽然REG_ADDR_SIZE = 6,但实际上最高位恒为0,相当于只有32个物理寄存器。
Issue Stage与多个FU独立地通信。具体来说,Issue Stage需要监控FUs的valid、ready信号,无条件地接受并存储FU的写回的数据。指令按顺序发射,每个FUs的写回可能是乱序的。因此,需要为不同的问题阶段分配ID(称为事务ID)。ID类似于记分牌将存储这条指令的结果的唯一位置。ID(有足够的位来唯一地表示记分牌中的每个槽,与其他数据一起传递给相应的功能单元。
这种方案允许FUs的操作完全独立于发射逻辑。它们可以以不同的顺序返回不同的事务。只要在结果旁边显示了对应的ID,Scoreboard就知道把它们放在哪里。这种方案甚至允许FUs缓冲并完全乱序地处理对它们有意义的结果。(与寄存器重命名操作有关)rename代码目前未完善。
4.2 Read Operands
读操作数和发射指令在同一个流水级进行,但可以把他们抽象成两个不同阶段。Scoreboard知道哪个寄存器会被写入,它可以处理操作数之间的转发路径(forwarding path)。Cva6的设计目标是使两条指令之间没有气泡。操作数会来自于寄存器,或者转发路径(Scoreboard通过查询“rd_clobber”信号可以处理forwarding path)。

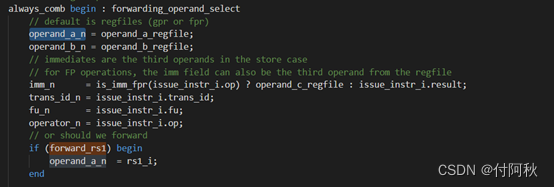
操作数选择逻辑是经典的优先级选择,scoreboard的结果优先于寄存器,因为功能单元总是产生最新的结果。为了获得正确的寄存器值,我们需要轮询Scoreboard的两个源操作数。在read operands中定义了逻辑寄存器,目前使用32个(有支持64个逻辑寄存器的结构):
GPR(通用逻辑寄存器):
位宽:64
读口:2
写口:2
x0固定为0
FPR(浮点逻辑寄存器):
位宽:64
读口:3(针对混合乘加指令)
写口:2
4.3 Scoreboard
Scoreboard通过FIFO实现,具有一个读端口和一个写端口,具有有效和确认信号。如果Scoreboard尚未满,指令解码将直接写入Scoreboard。Commit(提交)阶段查找已经完成的指令并更新体系结构状态。这意味着发生异常(exception),会更新寄存器或CSR文件。scoreboard 会在流水线中进一步进行增量处理,目的是跟踪所有解码、发出和提交的指令。scoreboard 条目控制操作数的选择、分派和执行。
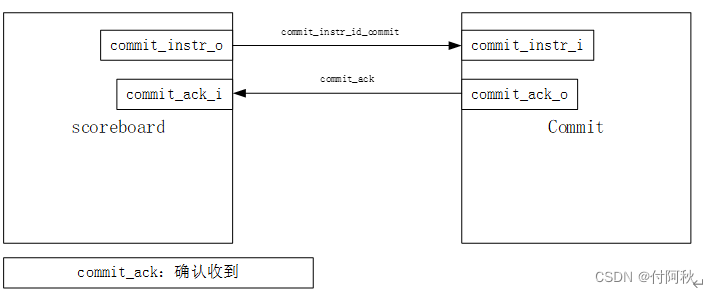
图 21 scoreboard-commit
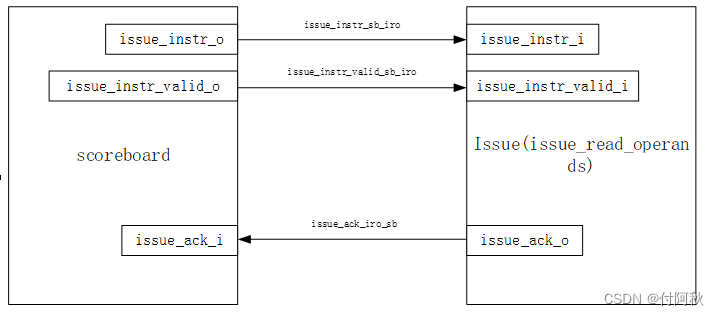
图 22 scoreboard-Issue
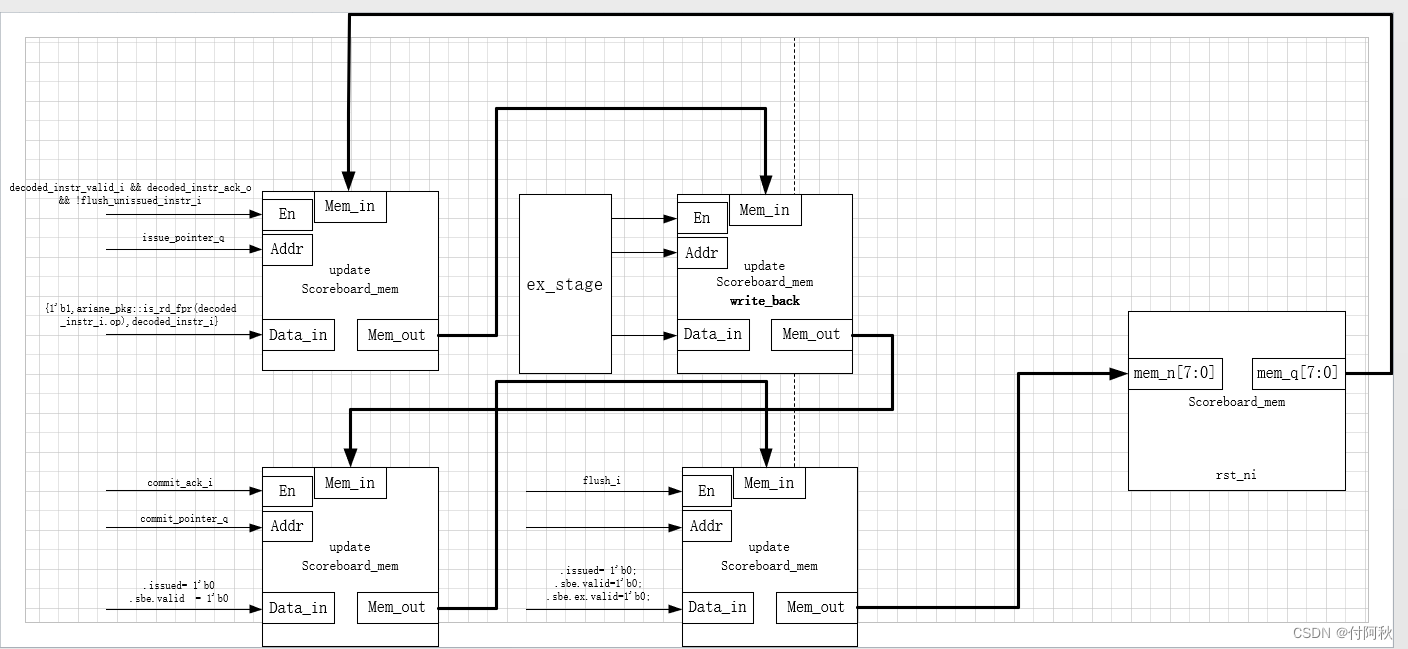
图 23 scoreboard的更新

图 24 scoreboard的输出信号
目前学到这里了,在知乎上也有一个很心细的博主,在我学习期间给了我很大帮助,里面的内容包含更多细节和基础知识:Ariane处理器源码剖析(一):Introduction - 知乎

















 5774
5774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









