










《Representing and Recommending Shopping Baskets with Complementarity, Compatibility, and Loyalty》论文笔记
摘要
本文研究了杂货店商品的表示学习和推荐问题。通过仔细调查了杂货交易数据,并观察到三种重要的模式:一是同一购物篮子内的产品在功能(互补性:Complementarity)方面相互补充;二是用户倾向于购买与其偏好(兼容性:Compatibility)相匹配的产品;三是相当一部分用户随着时间的推移反复购买相同的产品(忠诚度:Loyalty)。与传统的电子商务环境不同,互补性和忠诚度在杂货购物领域尤为突出。这将可以全面地利用互补性和兼容性挖掘一种新的表示学习方法,以及一种新的个性化推荐系统,除了用户的总体偏好和需求之外,还推荐“必须购买”的购买。做这些研究不仅提高了公共和私人交易数据的产品分类和推荐性能,涵盖了各种杂货店类型,而且还揭示了消费者购买偏好、必要性和忠诚度之间关系。
简介
从在线杂货购物平台(如Amazon Fresh、Instacart)再到自动结帐的实体杂货店(如Amazon Go),最年来的技术创新使人们的杂货购物体验发生了巨大变化。作为最频繁的购物活动之一,大量的杂货交易数据可以从多个来源收集。由于这方面的技术创新积累和大量数据收集,促使了包括个性化产品推荐、零售销售预测、零售库存优化和个性化促销策略在内的各种预测任务成为研究者们的关注热点。为了理解这些任务,作者试图探索用户购物篮中的语义,并开发有效的产品表示和购买预测技术。

许多现代和传统的推荐系统技术依赖于从交互数据中学习项目的潜在表示。一个例子是一个协同过滤算法、因子分解机等潜在因素模型,其中用户-产品(user-item)交互矩阵由低维用户和项目因子分解而来。这些方法通常试图全局恢复原始交互信息,但可能无法捕获项的微妙和细粒度语义。受自然语言处理(nlp)任务中提出的单词嵌入技术的启发,电子商务中最新的项目表示技术得到了发展。一般来说,这些方法旨在学习表示法,该表示法可以有效地从同一用户的购物篮子内或购物篮子之间恢复产品共现。在前面手工制作的特性设计中,这些方法会自动发现产品的有用(在推荐方面)表示。这些技术在现实世界的电子商务应用中都得到了广泛的采用。
作者研究了并将上述技术应用于杂货交易数据。文中指出,杂货店购物与传统的电子商务应用不同,主要是在于杂货店购物的规律性和必要性问题。这种杂货店的购物行为与电子商城的细微差别,需要独立研究并构建领域特定的表示和推荐算法。特别考虑用户购物篮中的以下模式:
•互补性。用户在同一篮子中购买多个相关产品以满足特定需求。这些产品在功能上是相辅相成的。例如,购物者可以一起为聚会购买塑料杯/叉/刀/盘和啤酒(图1)。这种产品之间的互补性是至关重要的,因为它不仅捕捉到产品的潜在功能,而且还揭示了用户在每个购物篮子中的意图。
•兼容性。与大多数电子商务类别一样,在杂货店购物中,用户偏好和产品属性之间的兼容性至关重要。此外,上述潜在的互补性功能可能也需要符合用户的偏好(例如,塑料杯和餐具更可能出现在派对爱好者的购物篮子里)。这种产品相互凝聚的关系激励作者在购物表征学习模型中全面考虑产品间的互补性和用户与产品间的兼容性。
•忠诚度。杂货交易中一个明显的模式是,用户往往对某些产品表现出“忠诚”,即重复购买同一产品,而很少在不同的替代品之间切换品牌。这种行为通常与传统推荐模型中隐含的假设相反:通常,如果两个产品具有相似的表示,并且与用户的偏好(或需求)相匹配,则可以推荐其中一个。
然而,如果一个用户对一个产品忠诚,那么它的替代品被购买的可能性就很低。事实上,简单的以用户为中心的产品购买频率成为推荐食品杂货产品的竞争基准,因为用户最忠诚的产品可以根据这些统计数据“记忆”。
当然,这样的基线缺乏泛化能力,因为它无法捕获产品语义。因此,一个合适的杂货店推荐算法应该平衡商品与商品的互补性、用户与商品的兼容性和用户对商品的忠诚度。这项研究中的主要目标是在杂货购物领域利用上述属性,并开发一个框架来理解用户购买的语义。其中所学习到的表示是可概括解释的,并且支持像自动产品分类和大规模购物的个性化推荐这样的任务。
本文贡献如下:
•受互补性和兼容性混淆的启发,专注于杂货交易数据中的核心组件(产品、产品、用户)同一购物篮子的三元组,即同一篮子中从用户处购买的两个产品,并提出了一个表示学习模型triple2vec,从整体上恢复上述互补性和相容性。
•在这些产品和用户表示的基础上,提出了一种新的个性化购物推荐算法adaLoyal
。该方法能够自适应地平衡用户的“必须购买”产品与从低维表示中推断出的偏好。
•对两个公共和两个专有数据集进行了广泛的实验,这些数据集涵盖各种杂货店类型,包括传统的实体超市、便利店和在线杂货购物平台。
•基于实验的定量结果,证明了所提出的triple2vec模型能够生成有意义(就产品分类任务而言)和有用(就推荐任务而言)的产品表示。特别是,通过应用adaLoyal,可以显著提高各种嵌入学习方法的性能。由adaLoyal估计的产品忠诚的有效性也可以在定性分析中得到验证。
•通过对提出的方法进行定量和定性分析,揭示了关于用户购物行为的重要和有趣的见解。主要的见解包括:1)与跨购物篮关系相比,购物篮内的商品对商品的互补性对于学习有意义的产品表示更为有用;2)建模用户的产品忠诚度和重复购买在杂货店产品推荐任务中至关重要,并且这种忠诚度在不同用户、商店类型和产品类别的情况下是不同的。
前提背景
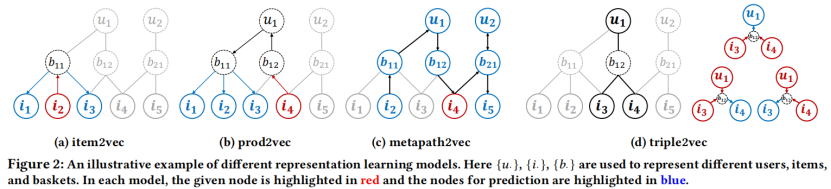
目前很多种先进的产品表示学习方法都是基于skip-gram框架的。本质上,它们通过区分不同的“上下文窗口”来寻找有助于预测上下文(相关)产品或用户的项表示形式。在杂货店购物篮的场景下,不同的算法的实现方式,如图2所示,将它们作为异构图(图2)上统一的于skip-gram框架的不同实例。该图的节点由不同的产品、用户、用户和还有篮子构成。这里有两种不同类型的链接:1)item to basket,表示一个产品包含在一个购物篮子中;2)user to basket,表示一个购物篮子是由用户购买的。在该图上,可以将几个现有的表示学习目标作为学习节点表示,其最大化最大似然估计(log likelihood)利用目标节点
v
v
v来预测上下文节点
C
v
C_v
Cv 即,
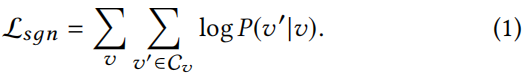
P
(
v
′
∣
v
)
P(v'|v)
P(v′∣v)表示为
P
(
v
′
∣
v
)
=
e
x
p
(
f
v
T
g
v
′
)
∑
v
′
′
e
x
p
(
f
v
T
g
v
′
′
)
P(v'|v)=\frac{exp(f_v^Tg_{v'})}{\sum_{v''}exp(f_v^Tg_{v''})}
P(v′∣v)=∑v′′exp(fvTgv′′)exp(fvTgv′),其中
f
v
f_v
fv和
g
v
g_v
gv是图中某个节点
v
v
v的K维向量表示。
下面简单介绍一下其他三种基准算法:
•item2vec.skip-gram框架可以直接应用到购物篮级别的这个图上,在这个图中,将一个特定的产品作为目标节点,而将同一购物篮中的其他产品作为上下文节点。这有一个前提假设:在同一购物篮子中购买的产品具有相似的语义,这直观地支持篮子内/捆绑包内的产品推荐。然而,这种共同购买关系可能不足以捕捉到用户对产品的个性化偏好。
• prod2vec.在prod2vec中,给定一个目标产品,上下文节点被定义为同一用户最近购买的购物篮子中的产品,而不是直接对购物篮子应用等式(1)。与item2vec不同,item2vec方法关注的是购物篮子内的共同购买关系,不考虑用户,而这种方法强调每个用户的跨购物篮子产品到产品的关系。
• metapath2vec.如前所述,交易日志可以转换为异构网络。因此,可以在这里应用最先进的网络嵌入学习方法,例如metapath2vec。在这个场景中,需要定义一个对称的元路径方案:item→basket→user→basket→item,并基于该方案生成不同的随机步行者(random-walker)。具体地说,从一个随机积开始,采样一系列节点组成一个随机游走器,其中每个节点连续链接到这个元路径上的前一个节点。然后我们选择一个给定的节点,并在公式(1)中将其周围的节点定义为“上下文”
C
v
C_v
Cv。一个具体的例子如图2c所示;这里我们对一个random-walker(i2,b11,u1,b12,i4,b21,u2,b21,i5,…)进行采样,用红色突出显示随机选择的目标节点i4,用蓝色突出显示其周围的节点。请注意,此item→basket→user→basket→item meta-path通常捕获同一用户购买的产品的语义,但不显式地反映产品共购关系。
triple2vec: Representations from Triples
不同于现有的基于skip_gram的产品表示,这个工作专注于每个项目(item,item,user)的密切关系,以不同的角度表示在同一购物篮中的两个产品。用于训练的交易数据由一系列这类三元组(triples)组成训练样本:
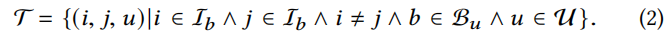
然后定义每个三元组的表示商品之间的内聚关系得分:

其中,
f
i
f_i
fi,
g
i
g_i
gi是产品的两个向量表示集合,
h
u
h_u
hu是用户的向量表示集合。等式3中的第一项对同一篮子中两个产品之间的互补性进行建模,即两个产品是否在共现方面表现出相似的语义;第二和第三项用于捕获产品和用户之间的兼容性,即产品(潜在)属性与用户偏好的匹配程度。较高的内聚性得分表示三个节点之间的连接更紧密。最后,通过最大似然训练优化三元组的嵌入向量表示
τ
\tau
τ。
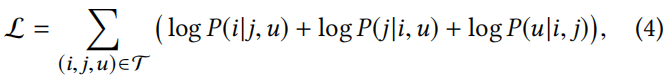
其中
P
(
i
∣
j
,
u
)
=
e
x
p
(
s
i
,
j
,
u
)
∑
i
′
e
x
p
(
s
i
′
,
j
,
u
)
P(i|j,u)=\frac{exp(s_{i,j,u})}{\sum_{i'}exp(s_{i',j,u})}
P(i∣j,u)=∑i′exp(si′,j,u)exp(si,j,u)和
P
(
u
∣
i
,
j
)
=
e
x
p
(
s
i
,
j
,
u
)
∑
u
′
e
x
p
(
s
i
,
j
,
u
′
)
P(u|i,j)=\frac{exp(s_{i,j,u})}{\sum_{u'}exp(s_{i,j,u'})}
P(u∣i,j)=∑u′exp(si,j,u′)exp(si,j,u),本质上,对于
τ
\tau
τ中的每一个三元组,我们迭代“剔除”一个节点,并使用其他两个节点来预测它。图2显示了一个说明性的示例,突出显示了本文提出的triple2vec模型和基于skip-gram模型之间的差异。
Negative Sampling.与基于skip-gram模型一样,噪声对比估计(NCE)可以应用于方程(4)中的softmax函数的近似和加速训练。如,在等式(4)中
l
o
g
p
(
i
∣
j
,
u
)
logp(i|j,u)
logp(i∣j,u)可以用下边的式子代替:
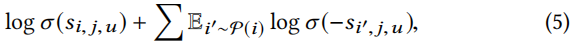
也就是从一个预定义好的分布
p
(
i
)
p(i)
p(i)中,采样出N个负样本,其中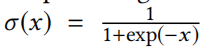
在TensorFlow中采用log-均匀分布(log-uniform),要求商品按受欢迎程度排序,每种商品被采样到的概率为
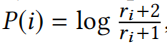
,其中表示i商品的排序。在本实验中,所有的表示学习方法都使用了这种负采样技术,与均匀采样策略相比,实验效果来看,它在加速了模型的收敛,并提高了量化性能。
商品表示与个性化推荐:注意到上边的triple2vec算法找中学习训练中能学习出商品的两个向量表示集
f
i
f_i
fi和
g
i
g_i
gi。这两个嵌入表示从不同的角度描述产品的功能和属性,但这两者之间的内积捕获了产品之间的交叉产品关系项到项的互补性。
因此,对于独立评估产品语义的任务(如产品分类、竞品搜索),使用加法合成
f
i
+
g
i
f_i+g_i
fi+gi作为每个产品i的最终表示,实验表明,对大多数任务都有轻微的促进作用。然而,对于需要考虑跨项目关系的预测性任务(如产品间推荐、互补性产品搜索),我们考虑两个产品i、j的内积得分
f
i
T
g
i
f_i^Tg_i
fiTgi。
可以考虑两种不同的推荐场景:个性化的下一个购物篮子产品推荐和购物篮子内产品推荐.
代码
def model_constructor(self, opt='sgd'):
n_user = self.n_user
n_item = self.n_item
HIDDEN_DIM = self.HIDDEN_DIM
LEARNING_RATE = self.LEARNING_RATE
N_NEG = self.N_NEG
u = tf.placeholder(tf.int32, [None])
i = tf.placeholder(tf.int32, [None])
j = tf.placeholder(tf.int32, [None])
user_emb = tf.get_variable("user_emb", [n_user, HIDDEN_DIM],
initializer=tf.random_uniform_initializer(-0.01, 0.01))
item_emb1 = tf.get_variable("item_emb1", [n_item, HIDDEN_DIM],
initializer=tf.random_uniform_initializer(-0.01, 0.01))
item_emb2 = tf.get_variable("item_emb2", [n_item, HIDDEN_DIM],
initializer=tf.random_uniform_initializer(-0.01, 0.01))
b_item = tf.get_variable("item_bias", [n_item, 1],
initializer=tf.constant_initializer(0))
b_user = tf.get_variable("user_bias", [n_user, 1],
initializer=tf.constant_initializer(0))
i_emb = tf.nn.embedding_lookup(item_emb1, i)
j_emb = tf.nn.embedding_lookup(item_emb2, j)
u_emb = tf.nn.embedding_lookup(user_emb, u)
input_emb_i = j_emb + u_emb
loss_i = tf.reduce_mean(tf.nn.nce_loss(weights=item_emb1, biases=b_item[:,0],
labels=tf.reshape(i, (tf.shape(i)[0], 1)), inputs=input_emb_i,
num_sampled=N_NEG, num_classes=n_item))
input_emb_j = i_emb + u_emb
loss_j = tf.reduce_mean(tf.nn.nce_loss(weights=item_emb2, biases=b_item[:,0],
labels=tf.reshape(j, (tf.shape(j)[0], 1)), inputs=input_emb_j,
num_sampled=N_NEG, num_classes=n_item))
input_emb_u = i_emb + j_emb
loss_u = tf.reduce_mean(tf.nn.nce_loss(weights=user_emb, biases=b_user[:,0],
labels=tf.reshape(u, (tf.shape(u)[0], 1)), inputs=input_emb_u,
num_sampled=N_NEG, num_classes=n_user))
trainloss = tf.reduce_mean([loss_i, loss_j, loss_u])
if opt == 'sgd':
myOpt = tf.train.GradientDescentOptimizer(LEARNING_RATE)
elif opt == 'adaGrad':
myOpt = tf.train.AdagradOptimizer(LEARNING_RATE)
elif opt == 'adam':
myOpt = tf.train.AdamOptimizer(LEARNING_RATE)
elif opt == 'lazyAdam':
myOpt = tf.contrib.opt.LazyAdamOptimizer(LEARNING_RATE)
elif opt == 'momentum':
myOpt = tf.train.MomentumOptimizer(LEARNING_RATE, 0.9)
else:
print('optimizer is not recognized, use SGD instead.')
sys.stdout.flush()
myOpt = tf.train.GradientDescentOptimizer(LEARNING_RATE)
optimizer = myOpt.minimize(trainloss)
模型源码非常简节,咋一看跟论文上讲到的公式(3)并不匹配,甚至不出现任何公式计算,巧妙之处就在于这里,结合噪声对比估计(NCE)以及加分结合律就能完美的实现公式(3)的功能,不复赘述。
还有一个忠诚度模块就不翻译了(不是我关注的重点,关键是懒)。
实验
数据集的基本情况

在分类任务上的对比效果

在个性化推荐系统中的表现:















 564
564











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









