






文章目录
Dataset condensation with gradient matching
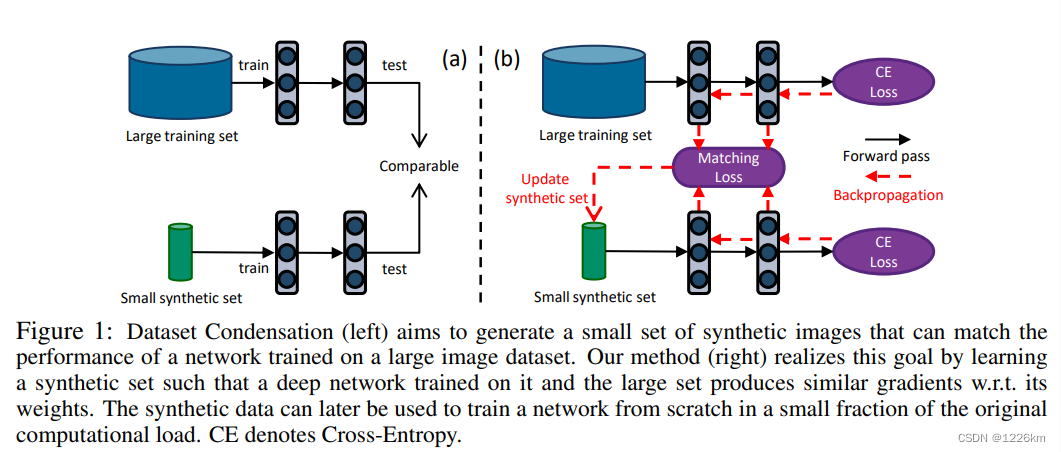
论文:Dataset condensation with gradient matching
代码:VICO-UoE/DatasetCondensation
摘要
- 特点:跨模型
- 目的:将大型数据集压缩成一小部分信息丰富的合成样本,用于从头开始训练深度神经网络
- 目标函数:在原始数据上训练的深度神经网络权重的梯度与合成数据之间的梯度匹配问题
- 基于训练损失计算梯度
方法
2.1 Dataset condensation
-
原始训练数据集 ∣ T ∣ |\mathcal{T}| ∣T∣,由图像及其类标签对组成:
T = { ( x i , y i ) } ∣ i = 1 ∣ T ∣ \mathcal{T}=\{(x_i,y_i)\}|_{i=1}^{|\mathcal{T}|} T={(xi,yi)}∣i=1∣T∣其中,
x ∈ X ⊂ R d x{\in}\mathcal{X}{\subset}{\mathbb{R}^d} x∈X⊂Rd, y ∈ { 0 , . . . , C − 1 } y{\in}\{0,...,C-1\} y∈{0,...,C−1};
X \mathcal{X} X是一个 d d d维输入空间;
C C C是类别数量。 -
本文希望学习一个带有参数 θ \theta θ的可微函数 ϕ \phi ϕ(如深度神经网络),以正确预测未知图像的标签,例如: y − ϕ θ ( x ) y-\phi_\theta(x) y−ϕθ(x)。
-
可以通过最小化训练集中的经验损失项来学习此函数的参数:
θ T = arg min θ L T ( θ ) (1) \theta^\mathcal{T}=\arg\mathop{\min}\limits_{\theta}\mathcal{L}^\mathcal{T}(\theta) \tag{1} θT=argθminLT(θ)(1)其中,
L T ( θ ) = 1 ∣ T ∣ ∑ x , y ∈ T ℓ ( ϕ θ ( x ) , y ) \mathcal{L}^\mathcal{T}(\theta)={1 \over |\mathcal{T}|}\sum_{x,y\in{\mathcal{T}}}\ell{({\phi_\theta}(x),y)} LT(θ)=∣T∣1∑x,y∈Tℓ(ϕθ(x),y);
ℓ ( ⋅ , ⋅ ) \ell{(·,·)} ℓ(⋅,⋅)是特定任务损失(即交叉熵);
θ T \theta^\mathcal{T} θT是 L T \mathcal{L}^\mathcal{T} LT的最小化。 -
所得模型 ϕ θ T \phi_{\theta^\mathcal{T}} ϕθT的泛化性能可以写作 E x ∈ P D [ ℓ ( ϕ θ T ( x ) , y ) ] \mathbb{E}_{x\in{P_D}}[\ell({\phi_{\theta^T}}(x),y)] Ex∈PD[ℓ(ϕθT(x),y)],其中 P D P_D PD为数据分布。
-
合成数据集 ∣ S ∣ |\mathcal{S}| ∣S∣:
S = { ( s i , y i ) } ∣ i = 1 ∣ S ∣ \mathcal{S}=\{(s_i,y_i)\}|_{i=1}^{|\mathcal{S}|} S={(si,yi)}∣i=1∣S∣其中, s ∈ R d , y ∈ Y , ∣ S ∣ ≪ ∣ T ∣ s\in{\mathbb{R}^d},y\in{\mathcal{Y}},|\mathcal{S}|\ll|\mathcal{T}| s∈Rd,y∈Y,∣S∣≪∣T∣。 -
类似于式(1),学习合成数据集后,可以在其上训练 ϕ \phi ϕ:
θ S = arg min θ L S ( θ ) (2) \theta^\mathcal{S}=\arg\mathop{\min}\limits_{\theta}\mathcal{L}^\mathcal{S}(\theta) \tag{2} θS=argθminLS(θ)(2)其中,
L S ( θ ) = 1 ∣ S ∣ ∑ x , y ∈ S ℓ ( ϕ θ ( s ) , y ) \mathcal{L}^\mathcal{S}(\theta)={1 \over |\mathcal{S}|}\sum_{x,y\in{\mathcal{S}}}\ell{({\phi_\theta}(s),y)} LS(θ)=∣S∣1∑x,y∈Sℓ(ϕθ(s),y);
θ S \theta^\mathcal{S} θS是 L S \mathcal{L}^\mathcal{S} LS的最小化。 -
由于合成集 ∣ S ∣ ≪ ∣ T ∣ |\mathcal{S}|\ll|\mathcal{T}| ∣S∣≪∣T∣,本文期望:
式(2)中的优化明显快于式(1);
ϕ θ S \phi_{\theta^\mathcal{S}} ϕθS的泛化性能接近 ϕ θ T \phi_{\theta^\mathcal{T}} ϕθT,即在真实数据分布 P D P_D PD下 E x ∈ P D [ ℓ ( ϕ θ T ( x ) , y ) ] ⋍ E x ∈ P D [ ℓ ( ϕ θ S ( x ) , y ) ] \mathbb{E}_{x\in{P_D}}[\ell({\phi_{\theta^T}}(x),y)]{\backsimeq}\mathbb{E}_{x\in{P_D}}[\ell({\phi_{\theta^\mathcal{S}}}(x),y)] Ex∈PD[ℓ(ϕθT(x),y)]⋍Ex∈PD[ℓ(ϕθS(x),y)] 。 -
其他方法讨论
在(Wang et al.,2018)中提出并在(Suchulutsky&Schonlau,2019;Bohdal et al.,2020;Such et al.,2020)中扩展,Tongzhou Wang, Jun-Yan Zhu, Antonio Torralba, and Alexei A Efros. Dataset distillation. arXiv preprint arXiv:1811.10959, 2018. Felipe Petroski Such, Aditya Rawal, Joel Lehman, Kenneth O Stanley, and Jeff Clune. Generative teaching networks: Accelerating neural architecture search by learning to generate synthetic training data. International Conference on Machine Learning, 2020. Ondrej Bohdal, Yongxin Yang, and Timothy Hospedales. Flexible dataset distillation: Learn labels instead of images. Neural Information Processing Systems Workshop, 2020. Ilia Sucholutsky and Matthias Schonlau. Soft-label dataset distillation and text dataset distillation. arXiv preprint arXiv:1910.02551, 2019.将参数 θ S {\theta^\mathcal{S}} θS作为合成数据 S \mathcal{S} S的函数:
S ∗ = arg min S L T ( θ S ( S ) ) s u b j e c t t o θ S ( S ) = arg min θ L S ( θ ) (3) \mathcal{S}^*=\arg\mathop{\min}\limits_{\mathcal{S}}\mathcal{L}^\mathcal{T}(\theta^\mathcal{S}(\mathcal{S})){\quad}{\quad}\mathsf{subject}{\;}\mathsf{to}{\quad}{\quad}\theta^\mathcal{S}(\mathcal{S})=\arg\mathop{\min}\limits_{\theta}\mathcal{L}^\mathcal{S}(\theta) \tag{3} S∗=argSminLT(θS(S))subjecttoθS(S)=argθminLS(θ)(3)
该方法旨在找到合成图像的最佳集合 S ∗ \mathcal{S}^* S∗,以便在它们上训练的模型 ϕ θ S \phi_{\theta^\mathcal{S}} ϕθS最小化原始数据的训练损失。
优化等式(3)涉及嵌套循环优化和在每次迭代中解决 θ S ( S ) \theta^\mathcal{S}(\mathcal{S}) θS(S)的内部循环以恢复 S \mathcal{S} S的梯度,这需要一个计算昂贵的过程——在 θ \theta θ的多个优化步骤上展开 S \mathcal{S} S的递归计算图(见(Samuel&Tappen,2009;Domke,2012))。
因此,它不能扩展到大型模型或具有许多步骤的精确内环优化器。Kegan GG Samuel and Marshall F Tappen. Learning optimized map estimates in continuouslyvalued mrf models. In 2009 IEEE Conference on Computer Vision and Pattern Recognition, pp. 477–484. IEEE, 2009. Justin Domke. Generic methods for optimization-based modeling. In Artificial Intelligence and Statistics, pp. 318–326, 2012. -
所以,本文提出了数据集压缩的替代公式。
2.2 具有参数匹配的Dataset condensation
-
本文目标是学习 S \mathcal{S} S ,使其上训练的模型 ϕ θ S \phi_{\theta^\mathcal{S}} ϕθS 泛化性能与 ϕ θ T \phi_{\theta^\mathcal{T}} ϕθT 相当,且在参数空间中收敛到相似解(即 θ S ≈ θ T {\theta^\mathcal{S}}\approx{\theta^\mathcal{T }} θS≈θT)。
-
假设 ϕ θ \phi_\theta ϕθ是一个局部平滑函数,相似的权重 ( θ S ≈ θ T ({\theta^\mathcal{S}}\approx{\theta^\mathcal{T }} (θS≈θT)表示局部邻域中相似的映射,从而泛化性能,即 E x ∈ P D [ ℓ ( ϕ θ T ( x ) , y ) ] ⋍ E x ∈ P D [ ℓ ( ϕ θ S ( x ) , y ) ] \mathbb{E}_{x\in{P_D}}[\ell({\phi_{\theta^T}}(x),y)]{\backsimeq}\mathbb{E}_{x\in{P_D}}[\ell({\phi_{\theta^S}}(x),y)] Ex∈PD[ℓ(ϕθT(x),y)]⋍Ex∈PD[ℓ(ϕθS(x),y)]。
局部平滑函数:Local smoothness is frequently used to obtain explicit first-order local approximations in deep networks(e.g. see (Rifai et al., 2012; Goodfellow et al., 2014b; Koh & Liang, 2017)) -
现在,可以将这个目标表述为:
min S D ( θ S , θ T ) s u b j e c t t o θ S ( S ) = arg min θ L S ( θ ) (4) \mathop{\min}\limits_{\mathcal{S}} D(\theta^\mathcal{S},\theta^\mathcal{T}){\quad}{\quad}\mathsf{subject}{\;}\mathsf{to}{\quad}{\quad}\theta^\mathcal{S}(\mathcal{S})=\arg\mathop{\min}\limits_{\theta}\mathcal{L}^\mathcal{S}(\theta) \tag{4} SminD(θS,θT)subjecttoθS(S)=argθminLS(θ)(4)其中,
θ T = arg min θ L T ( θ ) \theta^\mathcal{T}=\arg\mathop{\min}\limits_{\theta}\mathcal{L}^\mathcal{T}(\theta) θT=argθminLT(θ),
D ( ⋅ , ⋅ ) D{(·,·)} D(⋅,⋅)是距离函数。 -
在深度神经网络中, θ T {\theta^\mathcal{T}} θT通常取决于其初始值 θ 0 {\theta_0} θ0。
-
然而,式(4)中的优化旨在仅为初始化为 θ 0 {\theta_0} θ0的一个模型 ϕ θ T \phi_{\theta^\mathcal{T}} ϕθT 获得一组最佳合成图像,而我们的实际目标是生成可以处理随机初始化 P θ 0 P_{\theta_0} Pθ0分布的样本。
-
因此,本文修改式(4)如下:
min S E θ 0 ∼ P θ 0 D ( θ S ( θ 0 ) , θ T ( θ 0 ) ) s u b j e c t t o θ S ( S ) = arg min θ L S ( θ ( θ 0 ) ) (5) \mathop{\min}\limits_{\mathcal{S}} E_{\theta_0{\sim}P_{\theta_0}}D(\theta^\mathcal{S}(\theta_0),\theta^\mathcal{T}(\theta_0)){\quad}{\quad}\mathsf{subject}{\;}\mathsf{to}{\quad}{\quad}\theta^\mathcal{S}(\mathcal{S})=\arg\mathop{\min}\limits_{\theta}\mathcal{L}^\mathcal{S}(\theta(\theta_0)) \tag{5} SminEθ0∼Pθ0D(θS(θ0),θT(θ0))subjecttoθS(S)=argθminLS(θ(θ0))(5)其中, θ T = arg min θ L T ( θ ( θ 0 ) ) \theta^\mathcal{T}=\arg\mathop{\min}\limits_{\theta}\mathcal{L}^\mathcal{T}(\theta(\theta_0)) θT=argθminLT(θ(θ0))。 -
简而言之,在下一节中,本文仅使用 θ S {\theta^\mathcal{S}} θS和 θ T {\theta^\mathcal{T}} θT分别表示 θ S ( θ 0 ) {\theta^\mathcal{S}}(\theta_0) θS(θ0)和 θ T ( θ 0 ) {\theta^\mathcal{T}}(\theta_0) θT(θ0)。
-
求解式(5)的标准方法采用隐式微分(详见(Domke,2012)),其中涉及求解 θ S {\theta^\mathcal{S}} θS的内环优化。
-
由于内环优化 θ S = arg min θ L S ( θ ) \theta^\mathcal{S}=\arg\mathop{\min}\limits_{\theta}\mathcal{L}^\mathcal{S}(\theta) θS=argθminLS(θ)在大规模模型的情况下可能计算昂贵,因此可以采用(Domke,2012)中的反向优化方法,将 θ S {\theta^\mathcal{S}} θS重新定义为不完全优化的输出:
θ S ( S ) = o p t − a l g θ ( L S ( θ ) , ς ) (6) \theta^\mathcal{S}(\mathcal{S})={opt-alg}_{\theta}(\mathcal{L}^\mathcal{S}(\theta),\varsigma) \tag{6} θS(S)=opt−algθ(LS(θ),ς)(6)其中, o p t − a l g opt-alg opt−alg是具有固定steps数( ς \varsigma ς)的特定优化过程。 -
在实践中,不同初始化的 θ T {\theta^\mathcal{T}} θT可以首先在离线阶段训练,然后在式(5)中用作目标参数向量。
-
然而,通过学习回归 θ T {\theta^\mathcal{T}} θT作为目标向量有两个潜在的问题。
(1) θ T {\theta^\mathcal{T}} θT和 θ S {\theta^\mathcal{S}} θS中间值之间的距离在参数空间中可能太大,路径上有多个局部最小陷阱,因此很难达到。
(2) o p t − a l g opt-alg opt−alg涉及有限数量的优化步骤,作为速度和精度之间的权衡,这可能不足以采取足够的步骤来达到最优解。这些问题类似于(Wang et al.,2018)的问题,因为它们都涉及用 S \mathcal{S} S和 θ 0 {\theta_0} θ0参数化 θ S {\theta^\mathcal{S}} θS。
2.3 具有课程梯度匹配的Dataset condensation
- 本文提出了一种基于课程的方法来解决上述挑战。
- 关键思想是:希望 θ S {\theta^\mathcal{S}} θS不仅接近最终的 θ T {\theta^\mathcal{T}} θT,而且在整个优化过程中遵循与 θ T {\theta^\mathcal{T}} θT相似的路径。
- 虽然这可能限制 θ {\theta} θ的优化动态,但本文认为它也可以实现更有指导意义的优化和不完全优化器的有效使用。
- 现在可以将式(5)分解为多个子问题:
min S E θ 0 ∼ P θ 0 [ ∑ t = 0 T − 1 D ( θ t S , θ t T ) ] s u b j e c t t o θ t + 1 S ( S ) − o p t − a l g θ ( L S ( θ t S ) , ς S ) a n d θ t + 1 T − o p t − a l g θ ( L T ( θ t T ) , ς T ) (7) {\min\limits_{\mathcal{S}}}E_{\theta_0\sim{P_{\theta_0}}}[\sum_{t=0}^{T-1}D({\theta_t^\mathcal{S}},{\theta_t^\mathcal{T}})] \\ \mathsf{subject}{\;}\mathsf{to} \\ \theta_{t+1}^\mathcal{S}(\mathcal{S})-{opt-alg}_{\theta}(\mathcal{L}^\mathcal{S}(\theta_t^\mathcal{S}),\varsigma^\mathcal{S}) \quad\quad \mathsf{and} \quad\quad \theta_{t+1}^\mathcal{T}-{opt-alg}_{\theta}(\mathcal{L}^\mathcal{T}(\theta_t^\mathcal{T}),\varsigma^\mathcal{T}) \tag{7} SminEθ0∼Pθ0[t=0∑T−1D(θtS,θtT)]subjecttoθt+1S(S)−opt−algθ(LS(θtS),ςS)andθt+1T−opt−algθ(LT(θtT),ςT)(7)其中, T T T为迭代次数; ς S \varsigma^\mathcal{S} ςS和 ς T \varsigma^\mathcal{T} ςT分别为 θ S {\theta^\mathcal{S}} θS和 θ T {\theta^\mathcal{T}} θT的优化步数。 - 换句话说,本文希望生成一组压缩样本S,使得在其上训练的网络参数 ( θ t S ) ({\theta_t^\mathcal{S}}) (θtS)与每 t t t 次迭代时在原始训练集上训练的网络参数 ( θ t T ) ({\theta_t^\mathcal{T}}) (θtT)相似。
- 在初步实验中,本文观察到用 S \mathcal{S} S参数化的 θ t + 1 S {\theta_{t+1}^\mathcal{S}} θt+1S可以通过更新 S \mathcal{S} S并最小化 D ( θ t S , θ t T ) D({\theta_t^\mathcal{S}},{\theta_t^\mathcal{T}}) D(θtS,θtT)接近于零来成功跟踪 θ t + 1 T {\theta_{t+1}^\mathcal{T}} θt+1T。
- 在
o
p
t
−
a
l
g
opt-alg
opt−alg一步梯度下降优化的情况下,更新规则是
θ t + 1 S ← θ t S − η θ ▽ θ L S ( θ t S ) a n d θ t + 1 T ← θ t T − η θ ▽ θ L T ( θ t T ) (8) {\theta_{t+1}^\mathcal{S}}\leftarrow{\theta_{t}^\mathcal{S}}-{\eta_\theta}{\triangledown_\theta}{\mathcal{L}^\mathcal{S}({\theta_{t}^\mathcal{S}})}\quad\quad{and}\quad\quad{\theta_{t+1}^\mathcal{T}}\leftarrow{\theta_{t}^\mathcal{T}}-{\eta_\theta}{\triangledown_\theta}{\mathcal{L}^\mathcal{T}({\theta_{t}^\mathcal{T}})} \tag{8} θt+1S←θtS−ηθ▽θLS(θtS)andθt+1T←θtT−ηθ▽θLT(θtT)(8)其中, η θ {\eta_\theta} ηθ为学习率。 - 基于本文的观察(
D
(
θ
t
S
,
θ
t
T
)
≈
0
D({\theta_t^\mathcal{S}},{\theta_t^\mathcal{T}})\approx0
D(θtS,θtT)≈0),通过将
θ
t
T
{\theta_t^\mathcal{T}}
θtT替换为
θ
t
S
{\theta_t^\mathcal{S}}
θtS,并在本文剩余部分使用
θ
\theta
θ表示
θ
S
\theta^\mathcal{S}
θS简化式(7):
min S E θ 0 ∼ P θ 0 [ ∑ t = 0 T − 1 D ( ▽ θ L S ( θ t ) , ▽ θ L T ( θ t ) ) ] (9) {\min\limits_{\mathcal{S}}}E_{\theta_0\sim{P_{\theta_0}}}[\sum_{t=0}^{T-1}D({\triangledown_\theta}{\mathcal{L}^\mathcal{S}({\theta_t})},{\triangledown_\theta}{\mathcal{L}^\mathcal{T}({\theta_t})})] \tag{9} SminEθ0∼Pθ0[t=0∑T−1D(▽θLS(θt),▽θLT(θt))](9) - 我们现在有一个单一的深度网络,参数 θ \theta θ在合成集 S \mathcal{S} S上训练,该网络经过优化,使得关于 θ \theta θ的训练样本 L T \mathcal{L}^\mathcal{T} LT上的损失梯度和关于 θ \theta θ的合成样本 L S \mathcal{L}^\mathcal{S} LS上的损失梯度之间的距离最小化(梯度匹配)。
- 这种近似与(Wang et al.,2018)和式(5)相比具有关键优势,即它不需要对先前参数 { θ 0 , . . . , θ t − 1 } \{\theta_0,...,\theta_{t-1}\} {θ0,...,θt−1}进行昂贵的递归计算图展开。
- 本文方法优化速度明显更快,内存效率高,因此可以扩展到最先进的深度神经网络(例如ResNet(He et al.,2016))。
- 讨论
- 合成数据不仅包含样本,还包含其标签 ( s , y ) (s,y) (s,y),理论上可以通过优化式(9)来联合学习。
- 然而它们的联合优化具有挑战性,因为样本的内容取决于它们的标签,反之亦然。
- 因此,本文实验学习为固定标签合成图像,例如每个类一张合成图像。

- 梯度匹配损失
- 式(9)中的匹配损失 D ( ⋅ , ⋅ ) D{(·,·)} D(⋅,⋅)度量关于 θ \theta θ的 L S \mathcal{L}^\mathcal{S} LS和 L T \mathcal{L}^\mathcal{T} LT的梯度之间的距离。
- 当 ϕ θ \phi_\theta ϕθ是一个多层神经网络时,梯度对应于每个全连接层(FC)和卷积层的一组可学习的2D(out×in)和4D(out×in×h×w)权重,其中out、in、h、w是输出和输入通道数、核高度和宽度。
- 匹配损失可以分解为分层损失之和,即
D
(
▽
θ
L
S
,
▽
θ
L
T
)
=
∑
i
=
1
L
d
(
▽
θ
(
l
)
L
S
,
▽
θ
(
l
)
L
T
)
D({\triangledown_\theta}{\mathcal{L}^\mathcal{S}},{\triangledown_\theta}{\mathcal{L}^\mathcal{T}})={\sum_{i=1}^{L}}d({\triangledown_{\theta^{(l)}}}{\mathcal{L}^\mathcal{S}},{\triangledown_{\theta^{(l)}}}{\mathcal{L}^\mathcal{T}})
D(▽θLS,▽θLT)=∑i=1Ld(▽θ(l)LS,▽θ(l)LT),其中
l
l
l 是层索引,
L
L
L 是具有权重的层数,并且
d ( A , B ) = ∑ i = 1 o u t ( 1 − A i ⋅ ⋅ B i ⋅ ∥ A i ⋅ ∥ ⋅ ∥ B i ⋅ ∥ ) (10) d(\mathbf{A},\mathbf{B})=\sum_{i=1}^{out}(1-{{{\mathbf{A}_{i\cdot}{\cdot}\mathbf{B}_{i\cdot}}}\over{\parallel{{\mathbf{A}_{i\cdot}}}\parallel{\cdot}\parallel{{\mathbf{B}_{i\cdot}}}\parallel}}) \tag{10} d(A,B)=i=1∑out(1−∥Ai⋅∥⋅∥Bi⋅∥Ai⋅⋅Bi⋅)(10) 其中,
A i ⋅ {\mathbf{A}_{i\cdot}} Ai⋅、 B i ⋅ {\mathbf{B}_{i\cdot}} Bi⋅是对应于每个输出节点 i i i梯度的平滑向量,对于FC权重是in维度,对于卷积权重是in×h×w维度。 - (Lopez-Paz et al.,2017; Aljandy et al.,2019;朱et al.,2019)通过将所有层上的张量平滑为一个向量,然后计算两个向量之间的距离来忽略分层结构,与该方法相比,本文为每个输出节点进行分组。
- 本文发现,这对于梯度匹配来说是一个更好的距离(参见补充),并且可以在所有层上使用单一的学习率。
实验

















 518
518











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









