






文章目录
Dataset Condensation with Differentiable Siamese Augmentation
论文:Dataset Condensation with Differentiable Siamese Augmentation
代码:VICO-UoE/DatasetCondensation
摘要及介绍
- 提出可微Siamese增强
- 该方法能够有效地利用数据增强来合成更多信息的合成图像,从而在使用增强训练网络时获得更好的性能。
- DSA在每次训练迭代中,对采样的真实和合成Data应用相同的随机采样数据转换,并且还允许通过可微数据转换反向传播关于合成Data的损失函数的梯度。
- 如图1(右)所示,对采样的真实和合成batches应用相同程度的旋转。
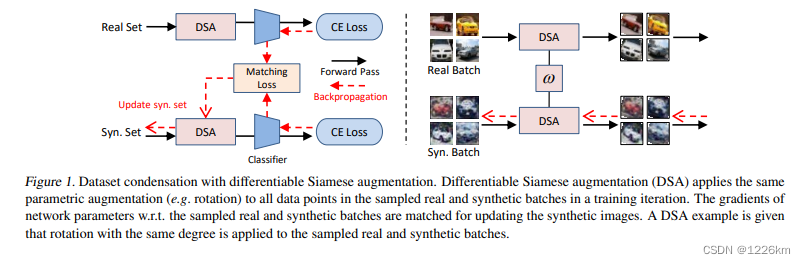
- 在训练中同时对真实和合成图像应用各种数据转换(例如顺时针旋转15°)具有三个关键优势:
(1)可以通过多种方式增强真实训练图像中的信息,并将这种增强的知识转移到合成图像中,从而更有效地利用这些信息。
(2)在真实图像和合成图像之间共享相同的转换,允许合成图像学习真实图像中的某些先验知识(例如,物体通常水平地在地面上)。
(3)一旦学习了合成图像,它们就可以与各种数据增强策略一起使用,以训练不同的深度神经网络架构。
方法
3.1 Dataset Condensation Review (DC)
Dataset condensation with gradient matching
数据集蒸馏论文(三):Dataset condensation with gradient matching
目标:在原始数据上训练的深度神经网络权重的梯度与合成数据之间的梯度匹配问题
重点:计算真实、合成Data上损失函数梯度之间的距离,用于更新合成Data
E
x
∈
P
D
[
ℓ
(
ϕ
θ
T
(
x
)
,
y
)
]
⋍
E
x
∈
P
D
[
ℓ
(
ϕ
θ
S
(
x
)
,
y
)
]
(1)
\mathbb{E}_{x\in{P_D}}[\ell({\phi_{\theta^T}}(x),y)]{\backsimeq}\mathbb{E}_{x\in{P_D}}[\ell({\phi_{\theta^\mathcal{S}}}(x),y)] \tag{1}
Ex∈PD[ℓ(ϕθT(x),y)]⋍Ex∈PD[ℓ(ϕθS(x),y)](1)
min
S
D
(
▽
θ
L
(
S
,
θ
t
)
,
▽
θ
L
(
T
,
θ
t
)
)
(2)
{\min\limits_{\mathcal{S}}}D({\triangledown_\theta}{\mathcal{L}(\mathcal{S},{\theta_t})},{\triangledown_\theta}{\mathcal{L}(\mathcal{T},{\theta_t})}) \tag{2}
SminD(▽θL(S,θt),▽θL(T,θt))(2)其中,
L
(
S
,
θ
t
)
=
1
∣
S
∣
∑
x
,
y
∈
S
ℓ
(
ϕ
θ
t
(
s
)
,
y
)
{\mathcal{L}(\mathcal{S},{\theta_t})}={1 \over |\mathcal{S}|}\sum_{x,y\in{\mathcal{S}}}\ell{({\phi_{\theta_t}}(s),y)}
L(S,θt)=∣S∣1∑x,y∈Sℓ(ϕθt(s),y)
L
(
T
,
θ
t
)
=
1
∣
T
∣
∑
x
,
y
∈
T
ℓ
(
ϕ
θ
t
(
x
)
,
y
)
{\mathcal{L}(\mathcal{T},{\theta_t})}={1 \over |\mathcal{T}|}\sum_{x,y\in{\mathcal{T}}}\ell{({\phi_{\theta_t}}(x),y)}
L(T,θt)=∣T∣1∑x,y∈Tℓ(ϕθt(x),y)
3.2. Differentiable Siamese Augmentation (DSA)
- 有效地同时利用数据增强与DC
- 方法一:在学习后对合成图像应用数据增强。然而,其性能提升可以忽略不计(在第4节中演示),因为合成图像没有优化以进行增强。
- 方法二:在学习合成图像的同时应用数据增强,这可以通过重写式(2)来制定:
min S D ( ▽ θ L ( A ( S , ω S ) , θ t ) , ▽ θ L ( A ( T , ω T ) , θ t ) ) (3) {\min\limits_{\mathcal{S}}}D({\triangledown_\theta}{\mathcal{L}{(\mathcal{A}(\mathcal{S},\omega^\mathcal{S}),\theta_t)}},{\triangledown_\theta}{\mathcal{L}{(\mathcal{A}(\mathcal{T},\omega^\mathcal{T}),\theta_t)}}) \tag{3} SminD(▽θL(A(S,ωS),θt),▽θL(A(T,ωT),θt))(3)其中, A \mathcal{A} A 表示一系列图像转换,其保留了输入的类标签,如裁剪、颜色增强、翻转,分别使用 ω S \omega^\mathcal{S} ωS 和 ω T \omega^\mathcal{T} ωT 对合成和真实训练Data进行参数化。
Siamese Augmentation
- 在标准数据增强中,独立地对每个图像从预定分布 Ω \Omega Ω 中随机采样 ω \omega ω 。
- 然而,在我们的例子中,随机采样 ω S \omega^\mathcal{S} ωS 和 ω T \omega^\mathcal{T} ωT 没有意义,因为这会导致式(2)中的模糊梯度匹配问题。
- 例如,在裁剪的情况下,将需要/合成图像的特定区域/产生/与/从不同训练迭代中真实图像的不同裁剪中生成的/特定区域/匹配的/梯度。
- 因此,这种方法会导致对合成图像的平均效应和信息丢失。
- 为了解决这个问题,本文改为在合成和真实训练集中使用相同的变换,即 ω S = ω T \omega^\mathcal{S}=\omega^\mathcal{T} ωS=ωT。
- 因此,本文后续部分使用一个符号 ω \omega ω。
- 由于两个集合具有不同数量的图像 S ≪ T \mathcal{S}\ll\mathcal{T} S≪T,并且它们之间没有一对一的对应关系,本文随机采样单个变换 ω \omega ω,并在每次训练迭代时将其应用于小批量对中的所有图像。
- 这也避免了小批量中的平均效应。
- 这种策略使得两个集合之间的对应关系(例如合成和真实集的15°顺时针旋转之间)以及更有效的方法来利用真实训练图像中的信息,并以更有组织的方式将其提炼到合成图像中,而不会产生平均效应。
Differentiable Augmentation
- 求解式(3)对于
S
\mathcal{S}
S 涉及通过反向传播计算关于合成图像的匹配损失
D
D
D 的梯度
∂
D
(
⋅
)
∂
S
\partial{D}(\cdot) \over \partial \mathcal{S}
∂S∂D(⋅) :
∂ D ( ⋅ ) ∂ S = ∂ D ( ⋅ ) ∂ ▽ θ L ( ⋅ ) ∂ ▽ θ L ( ⋅ ) ∂ A ( ⋅ ) ∂ A ( ⋅ ) ∂ S {\partial{D}(\cdot) \over \partial \mathcal{S}}={\partial{D}(\cdot) \over \partial\triangledown_\theta\mathcal{L}(\cdot)}{\partial\triangledown_\theta\mathcal{L}(\cdot) \over \partial\mathcal{A}(\cdot)}{\partial\mathcal{A}(\cdot) \over \partial\mathcal{S}} ∂S∂D(⋅)=∂▽θL(⋅)∂D(⋅)∂A(⋅)∂▽θL(⋅)∂S∂A(⋅)因此,关于合成图像 S \mathcal{S} S 的变换 A \mathcal{A} A 必须可微。 - 传统上,用于数据增强的变换不是以可微的方式实现的,因为优化输入图像不是它们的重点。
- 请注意,图像的所有标准数据增强方法都是可微的,可以实现为可微层。
- 因此,本文将它们实现为深度神经网络训练的可微函数,并允许误差信号反向传播到合成图像。
3.3 Training Algorithm
- 为了确保生成的合成图像可以使用任意随机初始化的参数从头开始训练深度神经网络,本文使用了一个具有K次迭代的外环。
- 在每次外部迭代中,我们从分布 P θ 0 P_{\theta_0} Pθ0 中随机初始化网络参数(即 θ 0 ∼ P θ 0 {\theta_0}{\sim}P_{\theta_0} θ0∼Pθ0),并从头开始训练它们。
- 在内循环 t t t 中,我们从仅包含 c c c 类样本的真实集和合成集中随机采样图像变换 ω \omega ω 和小批量对 B c T B_c^{\mathcal{T}} BcT、 B c S B_c^{\mathcal{S}} BcS,分别计算它们关于模型参数的平均交叉熵损失和梯度。
- 然后计算式(3)中的梯度匹配损失,并使用具有 ς S \varsigma_\mathcal{S} ςS 梯度下降步长和 η S \eta_\mathcal{S} ηS 学习率的随机梯度下降优化来更新合成数据 S c \mathcal{S}_c Sc 。
- 本文对内循环 t t t 中的每个类 c c c 重复上述步骤。
- 或者,更新模型参数 θ t \theta_t θt 以最小化/具有 ς θ \varsigma_\theta ςθ 梯度下降步长和 η θ \eta_\theta ηθ 学习率的/增强合成数据上的/交叉熵损失。
讨论
- 本文观察到,使用来自多个类的小批量会导致训练中收敛速度较慢。
- 原因是当梯度 △ θ L \triangle_\theta\mathcal{L} △θL 是多个类的样本平均时,合成数据的{图像/类对应}更难从梯度中检索。

实验
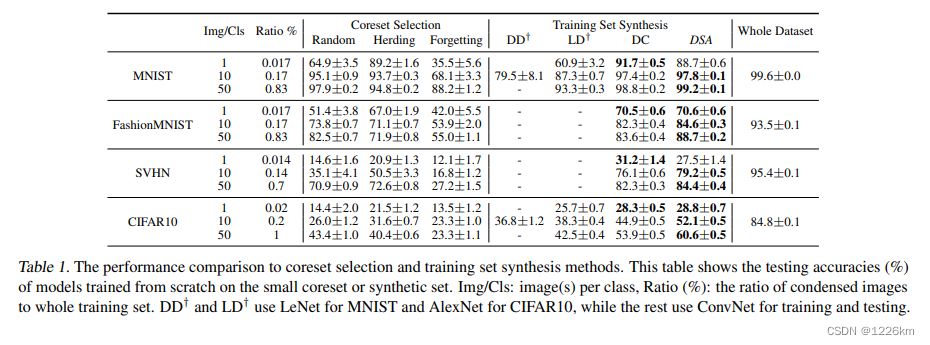
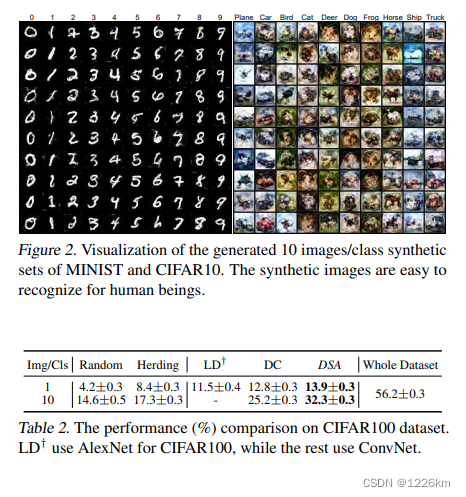
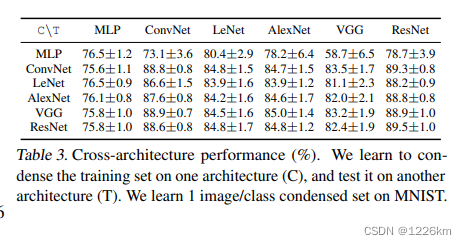


















 346
346











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









