







本文提出了一种用于数据效率学习的训练集合成技术,称为“数据集凝聚”(Dataset),它学习将大数据集压缩成一个小的信息合成样本集,用于从头开始训练深度神经网络。我们将这个目标表述为在原始数据和合成数据上训练的深度神经网络权值的梯度之间的梯度匹配问题。
方法
1.1 数据浓缩

即要使得在浓缩数据集上的训练模型结果的损失要近似于在数据集上的训练结果。(公式的含义就是,当模型在真实数据集上取得的损失最小时,与在浓缩数据集上取得最小损失的模型,这两个模型要比较接近)
1.2 参数匹配的数据集浓缩

与前面表达的意思相同,就是要使获得的
θ
S
\theta^S
θS与
θ
T
\theta^T
θT距离尽可能小。而且这个
θ
S
\theta^S
θS不能仅仅在一个
θ
0
\theta_0
θ0上训练得到的模型与
θ
T
\theta^T
θT距离小,而是要在所有的模型初始化下,训练出来的
θ
S
\theta^S
θS都要与
θ
T
\theta^T
θT尽可能接近,这涉及到训练时浓缩数据集泛化的问题。(每个数据浓缩论文都会讲这点)
1.3 基于梯度匹配的数据集凝聚
1.2提出的方法是直接计算两个模型之间的距离,作者这里提出,直接匹配训练的梯度(跟直接匹配模型差不多)。

将min改为梯度与梯度之间的距离,代替模型与模型之间的距离。
具体算法如下:

外部大轮次用于训练不同的
θ
0
\theta_0
θ0初始化,在初始化模型后,进行T步迭代更新
θ
0
\theta_0
θ0,最内部的循环for c=0,..., C-1 do是对每一个标签的浓缩数据集进行训练,通过在真实样本和浓缩样本都取样出标签为c的样本,共同丢入模型得到损失,然后计算得到的损失对应的梯度的距离,并更新浓缩数据集,在对C个标签都训练了一次浓缩数据集后,使用浓缩数据集反向传播,更新
θ
0
\theta_0
θ0至
θ
1
\theta_1
θ1,继续重复这个过程,在
θ
1
\theta_1
θ1上训练浓缩数据集,并在最后更新
θ
1
\theta_1
θ1…
在执行完T-1步后,重新换一个
θ
0
\theta_0
θ0,重复这个大过程(浓缩数据集继续学习)。
实验结果
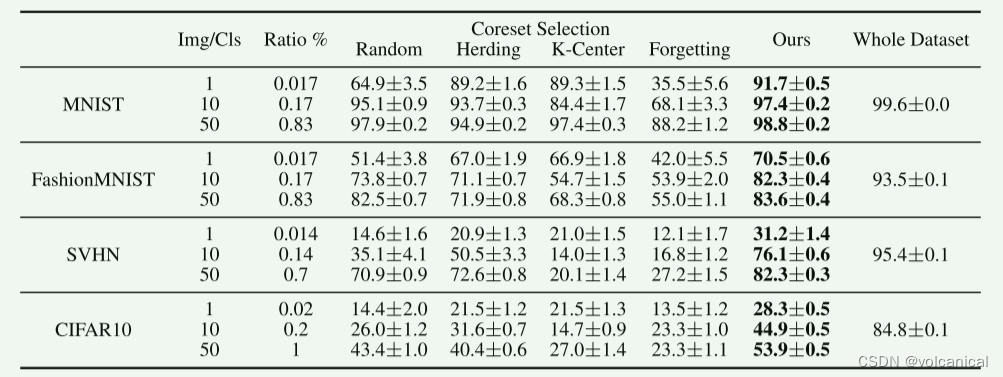
- Random 随机选样本
- Herding 聚类中心样本
- K-center 选择中心点附近的点
- forgetting 选择训练过程中容易遗忘的训练样本。

















 518
518











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











