






参考文献和网络
论文阅读摘要及代码细节
【PETR:用于3D多视角目标检测的位置嵌入变换】
- 论文
本文提出了一种用于多视角3D目标检测的位置嵌入变换。PETR将3D坐标的位置信息编码为图像特征,以产生3D位置感知特征。对象查询可以感知3D位置感知特征并实现端到端的目标检测。在标准NuScenes数据集上,PETR实现了SOTA性能(50.4%NDS和44.1%mAP)。
PETR针对的是DETR3D网络在预测中存在的问题:参考点坐标的预测值不够精确,会使得采样特征超出特征区域;只有投影点上的图像特征会被采集,因此网络不能进行全局视角的表征学习;并且,过于复杂的特征采样过程阻碍了检测器的实际应用。
论文的思路是通过某种方式,将多视角的2D特征转换为3D感知特征,从而实现一个简洁高效的特征提取及目标预测框架。这里的“某种方式”,就是指编码3D位置嵌入。
为了实现这一目标,论文做了以下工作:
- 将不同视角共享的相机视锥体离散化到网格空间中。
- 通过不同的相机参数对坐标进行变换,获得3D世界坐标。
- 将从backbone中提取的2D图像特征和3D坐标输入一个简单的3D位置编码器,从而产生3D位置感知特征。
- 3D位置感知特征与变换解码器中的Object Query交互,更新Object Query,进一步采用OQ来预测目标类别和bbox。
总体而言,网络的结构是较为简单的,即2D多视角图像输入backbone,得到特征图。相机视椎体离散化为3D网格,网格坐标通过相机参数转换并生成3D世界坐标。然后2D特征和3D坐标进行拼接,共同输入3D位置编码器,从而产生3D位置感知特征(这里具体的做法是通过1x1卷积对2D特征降维,通过FC+ReLU+FC的级联对3D特征位置嵌入,然后相加并通过全连接层展开),这一特征输入Transformer解码器,用于更新Object Query,最后,更新完成的Object Query用于预测。
- 实验
| 实验细节 | 具体参数 | 说明 |
| 数据集 | NuScenes | 由6个摄像机、1个Lidar和5个Radar采集1000个场景的多视角数据 |
| 评估指标 | NDS,mAP,mATE,mASE,mAOE,mAVE,mAAE | |
| Backbone | 提取特征 | ResNet,Swin-T,VoVNetV2 |
| 优化器 | AdamW | 权重衰减率=0.01 |
| 超参数 | 学习率0.0002,以余弦退火衰减 | |
| 训练策略 | 多尺度训练 | 短边[640, 900],长边1600 |
| 训练环境 | V100 | 8台V100,BS=8,Epoch=24 |
实际训练【如何组织多视角数据集】
PETR的代码采用了mmdet3d的框架,在projects/mmdet3d_plugin中对数据集和模型进行了添加。
- 多视角数据集加载PIPELINE
Args:
results (dict): Result dict containing multi-view image filenames.
Returns:
dict: The result dict containing the multi-view image data. \
Added keys and values are described below.
- filename (str): Multi-view image filenames.
- img (np.ndarray): Multi-view image arrays.
- img_shape (tuple[int]): Shape of multi-view image arrays.
- ori_shape (tuple[int]): Shape of original image arrays.
- pad_shape (tuple[int]): Shape of padded image arrays.
- scale_factor (float): Scale factor.
- img_norm_cfg (dict): Normalization configuration of images.返回results的[img_filename]参数是一系列filename的列表,相应的,其他关键字对应的参数也是多视角数据的列表。
【MV-S2S:用于抽象对话摘要的具有会话结构的多视角Seq2Seq模型】
- 论文
文本摘要是自然语言处理中最具挑战性和趣味性的问题之一。尽管对于新闻报道或百科全书式文章等结构化文本的摘要已经引起了广泛关注,对于对话——即人机交互的关键部分,其中信息最重要的部分分散在不同说话者的不同话语中——的摘要研究仍然较少。本工作提出了一种多视角Seq2Seq模型,首先提取不同视角下的非结构化日常聊天中的会话结构,然后利用多视角解码器合并不同视角以生成对话摘要。在大规模对话摘要语料库上的实验表明,我们的方法无论是在自动评估还是在人工评价方面都达到了SOTA效果。
论文的主要贡献包括:1)利用丰富的对话结构,如结构化视角(话题视角与对话阶段视角)、通用视角(全局视角和局部视角)来进行抽象会话摘要。2)设计了多视角Seq2Seq模型,包含一个对话编码器以编码不同视角信息,和一个拥有多视角注意力机制的多视角解码器,生成对话摘要。3)在大型对话摘要数据集SAMSum上进行了实验,证明了论文方法的高效性。4)进行了误差分析,讨论了当前方法面临的具体挑战。
论文结构图:
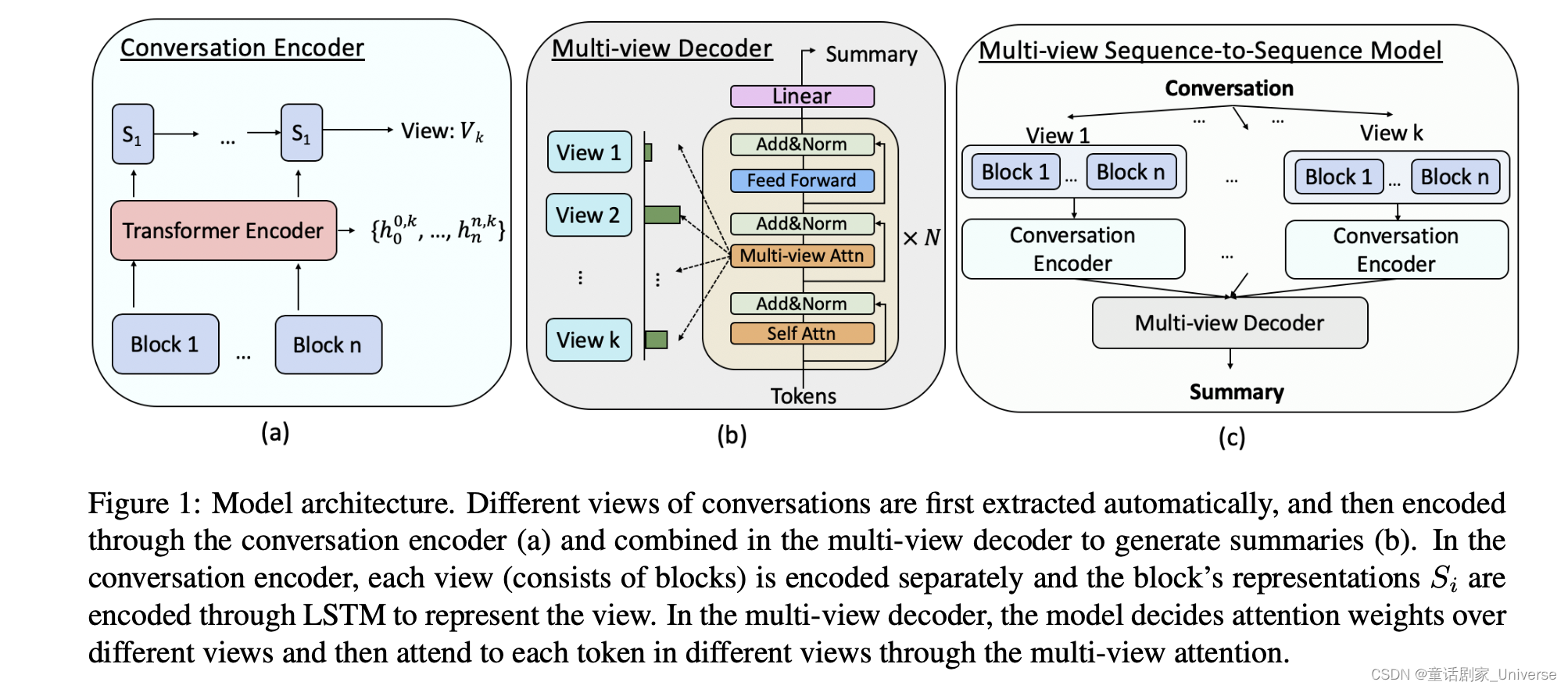
可以看出,网络主要是对每个视角分别进行对话编码,然后统一送进多视角解码器,在多视角解码器中采用多视角注意力机制进行解码,最后实现摘要。
- 实验
| 实验细节 | 具体参数 | 说明 |
| 数据集 | SAMSum | 2019年提出的大型对话摘要语料库 |
| 评估指标 | ROUGE Score(ROUGE1,ROUGE2,ROUGE-L) | |
| 超参数 | 学习率0.003 |
代码待补充
【BIRADS:基于多视角CNN的高分辨率乳腺癌筛查】
- 论文
自然图像深度学习的进展使得人们对于将类似技术应用到医学图像的兴趣激增。最初,大多数尝试集中于将医学图像替换自然图像作为CNN的输入,但却没有考虑过两种图像之间的根本差异。具体而言,医学图像中的检测需要非常精细的细节,而自然图像检测重点需要粗糙的结构。这种差异使得直接使用为自然图像开发的现有网络体系是不够的,因为它们会在处理过程中大幅下采样图像以减少内存开销。这种下采样隐藏了做出准确预测所需要的细节。此外,医学成像中的一次测验(exam)通常伴随着一系列视角,而这些视角需要通过融合才能得出正确的结论。在本论文中,我们旨在使用一个多视角深度CNN,其能够处理一组高分辨率医学图像。我们在大型x光成像的乳腺癌检测数据集(具有886000张图像的BI-RADs)上进行评估,重点研究了训练集规模和图片大小对于预测精度的影响。结果表明,模型性能随着训练集大小增加,在原始分辨率下具有最优性能。
本论文主要进行的工作包括:
- 建立了一个大规模数据集,从作者机构中收集了201698例(886437张)针对乳腺癌部位的x光检查片。
- 设计了一个新型DCN网络,可以处理多视角的x光检查片并在不下采样的前提下使用高分辨率原图。这一网络的名称叫做MV-DCN。
- 研究了数据集尺寸和图片分辨率对于x光片预测的性能,这可以对未来医学成像DCM的优化提供指导。
该文章中使用的4个视角分别是L-CC、R-CC、L-MLO和R-MLO,也就是颅尾和内侧斜视图的左右方位。论文构建的多视角DCN为二阶段网络,在第一个阶段,一系列卷积和池化层会分别用于每个视角,这些来自不同视角所提取的表征被拼接为一个向量作为第二阶段的输入,即全连接层和softmax层用以预测结果。网络采用梯度随机下降和反向传播进行训练,为了避免过拟合,网络还使用了正则化技术、随机裁剪、Dropout策略等方法。
论文还提及了一些避免因为下采样而损失医学图像的细节,因为和多视角无关所以不做记录。
- 实验
| 实验细节 | 具体参数 | 说明 |
| 数据集 | BIRADS数据集 | 由论文所在机构收集,共包含129208名19-99岁之间患者的x光片。 |
| 评估指标 | macAUC | |
| 数据预处理 | 通过mean和std进行归一化处理,对图片进行翻转处理 |
代码待补充
【TMC:基于动态证据融合的可信多视角分类】
- 论文
现有的多视角分类算法致力于通过利用不同的视角来提升精度,通常会集成到下游任务的通用表征之中。尽管这样做很高效,但确保多视角集成和最终决策的可靠性也十分关键(特别是对于噪音、损坏和不可分布数据)。动态评估不同样本每个视角的可信度可以提供可靠的集成(Integration),这可以通过不确定性估计来实现。基于这一思想,论文提出了一种创新的多视角分类算法,即TMC,通过在证据水平上动态集成不同的视角,为多视角学习提供了新的范式。TMC可以通过考虑来自每个视角的证据来提高分类的可靠性。具体而言,论文引入了变分狄利克雷以表征类别概率的分布,将不同视角的证据进行参数化,并与Dempster-Shafer理论进行结合。统一的学习框架引入了精确不确定性,并且相应赋予了模型可靠性和鲁棒性以抵御可能的噪声和破坏。论文理论和实验结果都验证了模型在准确性、鲁棒性和可信度方面的有效性。
论文提到,现有的多视角方法通常假定每个视角具有相同的值,或者会为每个视角学习固定的权重因子。这两种方法的基本假设是需要每个视角的数据具有相同的质量和重要性,但实际中往往不能达到,即每个视角的质量因样本而异。
使用量化不确定性分析方法可以评估预测结果的可信度,但现有的方法通常只能应用于单一视角的数据。为了促进Trusted Learning,本文提出了一种新的多视角分类方法,以集成多视角信息并进行可信决策。模型不像之前的方法那样利用不同视角所产生的特征,而是在证据level上利用多视角,从而产生稳定、合理的不确定性估计,提高分类的可靠性和鲁棒性。
由于本文接近于机器学习,对研究没有太多参考价值,所以不详细叙述。
【MVPE:利用DNN从步态视频中自动检测健康问题】
- 论文
本研究的目的是开发一种使用DNN自动检测步态相关健康问题的系统。方法:系统以患者视频作为输入,并使用基于DNN的方法估计其3D身体姿态。分类器能够分析生成的3D身体姿态时间序列,这一分类器的输入是步态视频,包含4组:健康、帕金森、中风和骨科问题。本系统消除了对于复杂重型设备和大型实验室空间的要求,可以应用于家庭环境中。另外,本系统不需要依赖特征工程的领域知识,因为它可以从输入数据中提取语义和高级特征。
步态分析是对于人类行走姿态的系统性研究,旨在识别步态模式的异常,推测其原因并提出合适的治疗方法。论文的主要工作包括:
- 提出了一种用于检测基于步态的健康问题的自动系统,其数据来源于由普通数码相机所拍摄的步态视频。
- 设计了一种基于DNN的模型以从视频中估计3D身体姿态,并且对照基于标记的运动捕捉系统验证结果。
- 创建了一个基于DNN的分类器,从所估计的3D身体姿态中检测健康问题。
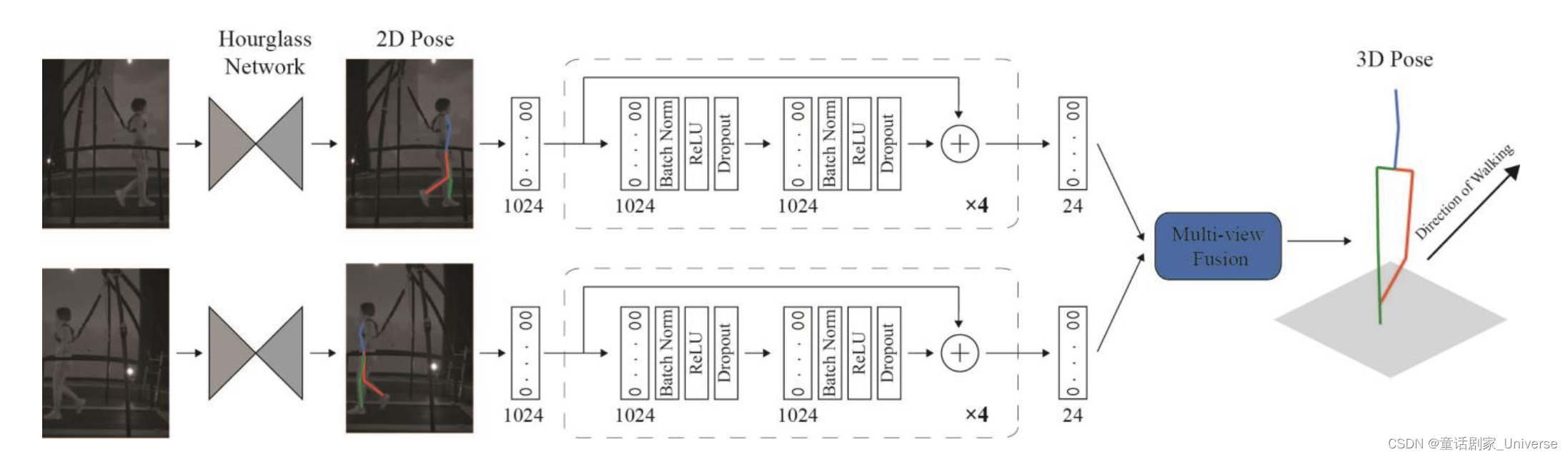
论文结构图:

论文方法包含两个DNN,第一个是姿态估计器,将视频作为输入并为每一帧视频估计相应的3D身体姿态,从而构建24个(3个方向x8个关节)时间序列。每个时间序列都表示一个关节在x、y或z方向上的位置;第二个是分类器,将估计后的时间序列作为输入,并分类到4个类别中的一个。
在第一阶段,首先会对每个视角单独估计3D姿态,然后转换为全局坐标并进行多视角融合。 如下所示:
- 实验
| 实验细节 | 具体参数 | 说明 |
| 数据集 | 步态数据集 | 包括23个帕金森患者、22个中风患者、25个骨科患者和25名健康者的步态视频。视频由2台数码相机从侧面进行记录。 |
| 1st DNN | Hourglass | 使用Hourglass网络来进行2D姿态估计,该网络是目前人体姿态估计上的SOTA模型。 |
| 优化器 | Adam | |
| 训练策略 | 首先用数据集对Hourglass进行fine-tune,然后对网络先进行单视角训练、再进行多视角训练,最后对分类器也从头训练。 | |
| 实验环境 | 1台Tesla K40c |
【ImVoxelNet:用于单目和多视角通用3D目标检测的图像到体素投影】
- 论文
这篇论文中,我们将基于RGB的多视角3D目标检测看作一个端到端的优化问题。为了解决这一问题,我们提出了ImVoxelNet,该网络是一个基于位姿单目或多视角RGB图像的全卷积3D目标检测方法。在训练和推理过程中,每个多视角输入的单目图像的数量可以变化,而且实际上每个多视角输入的数目都是独立的。ImVoxelNet可以成功地处理室内和室外的场景,这使其具有通用性。具体而言,这一网络在Kitti和NuScenes数据集上分别实现了SOTA结果。
论文所进行的工作包括:
- 建立了第一个仅基于姿态RGB图像的端到端多视角3D目标检测模型。
- 提出了一个既可以用在单目、也可以用在多视角上的全卷积3D目标检测器。
- 对于特定领域头,论文方法在室内和室外数据集上均取得了SOTA结果。
论文结构图:
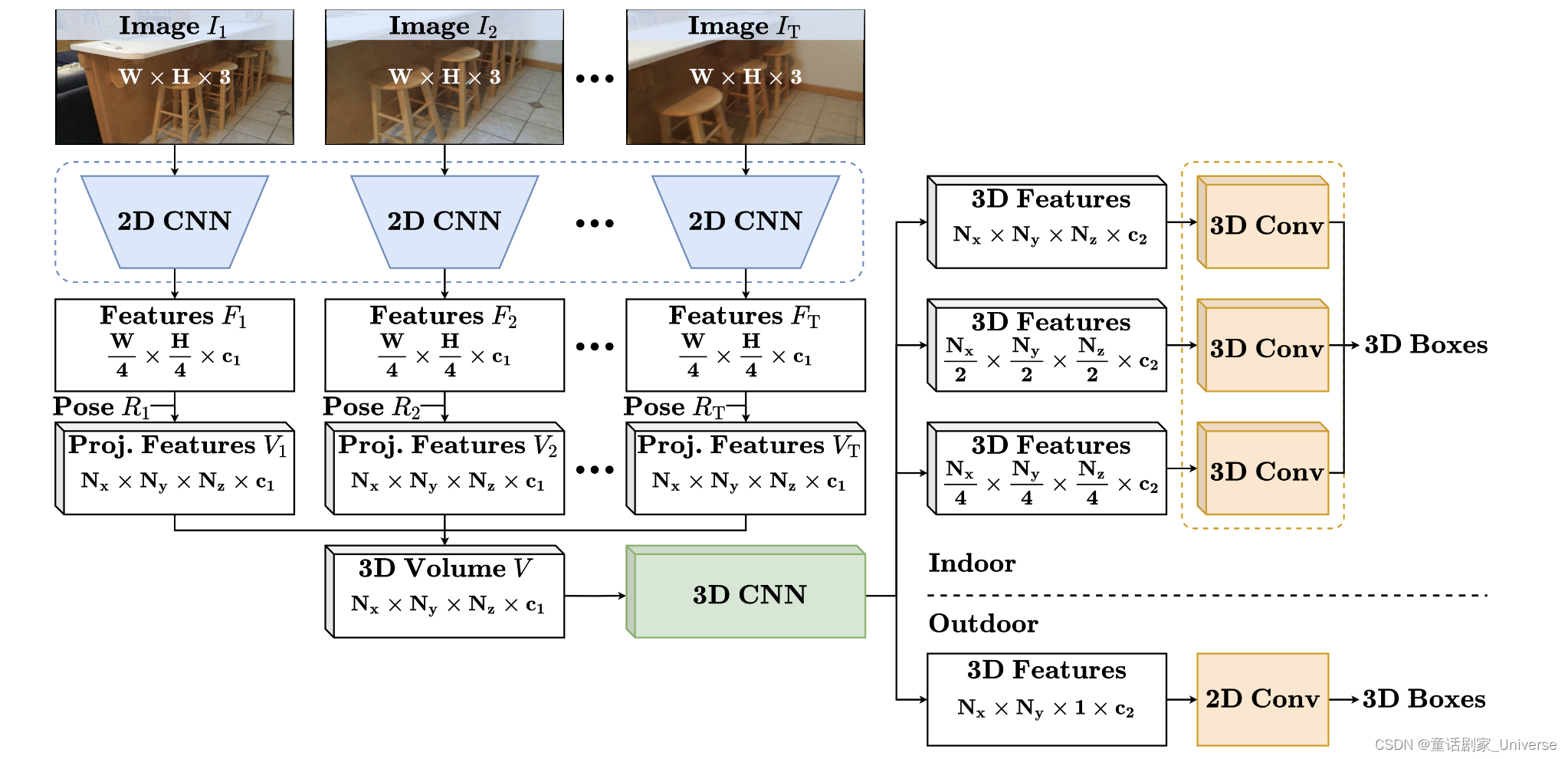
论文方法可以接受任意大小的具有相机姿态的RGB输入,首先会通过2D的backbone网络提取图片特征,然后会将获取的图像特征投影到一个3D像素体积(3D Voxel Volume)中,对于每个像素,从多张图片中投影的特征都会通过一个简单的元素平均来聚合。第二步,具有聚合特征的像素volume会通过一个作为neck的3D卷积网络,其输出作为最后几个卷积层的输入,而这几个卷积层就是为每个anchor预测bbox的head。最终预测得到的bbox会被参数化为(x, y, z, w, h, l , θ)。
- 实验
| 实验细节 | 具体参数 | 说明 |
| 数据集 | Kitti和NuScenes等 | ScanNet、Sun RGB-D作为室内数据集,NuScenes和Kitti作为室外数据集,其中ScanNet和NuScenes是多视角,另两个为单目。 |
| 优化器 | Adam | |
| 超参数 | 学习率为0.0001,以0.0001的速率权重衰减。训练12个epoch。 | |
| 训练环境 | 8个Tesla P40GPU |
网络以MMDetection框架作为Baseline,并使用其默认的训练设置。

















 40
40

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









