







论文地址:PETR: Position Embedding Transformation for Multi-View 3D Object Detection
代码地址:https://github.com/megvii-research/PETR.
1、引言
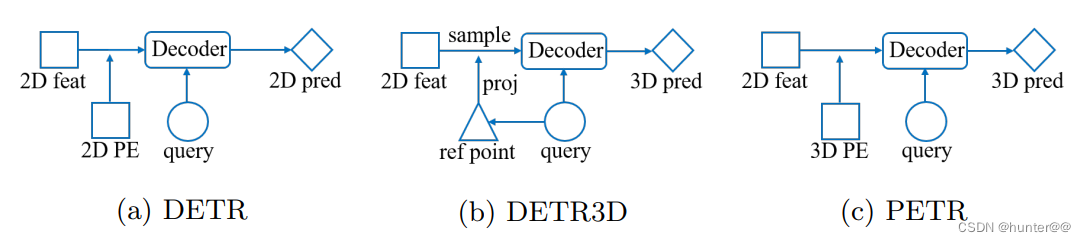
PETR是DETR3D的改进版,也是3D目标检测的重要组成之一。不同于DETR3D根据object query预测N个3d中心点,然后利用相机参数将参考点反投影回图像,对2D图像特征进行采样,最后根据采样得到2D图像特征预测3D目标信息的解决方案。
PETR直接通过一个全局3D位置编码(3D PE)来进行信息嵌入,这么做的出发点是为了解决原本DETR3D进行2D到3D转换带来的参考点预测坐标不准确,采样特征超出目标区域以及全局特征学习不充分的问题。
注:总体来看,PETR也还是一个transformer结构的检测框架,其与DETR3D的主要区别在于使用3D PE进行位置编码,也就是图2的encoder的结构。
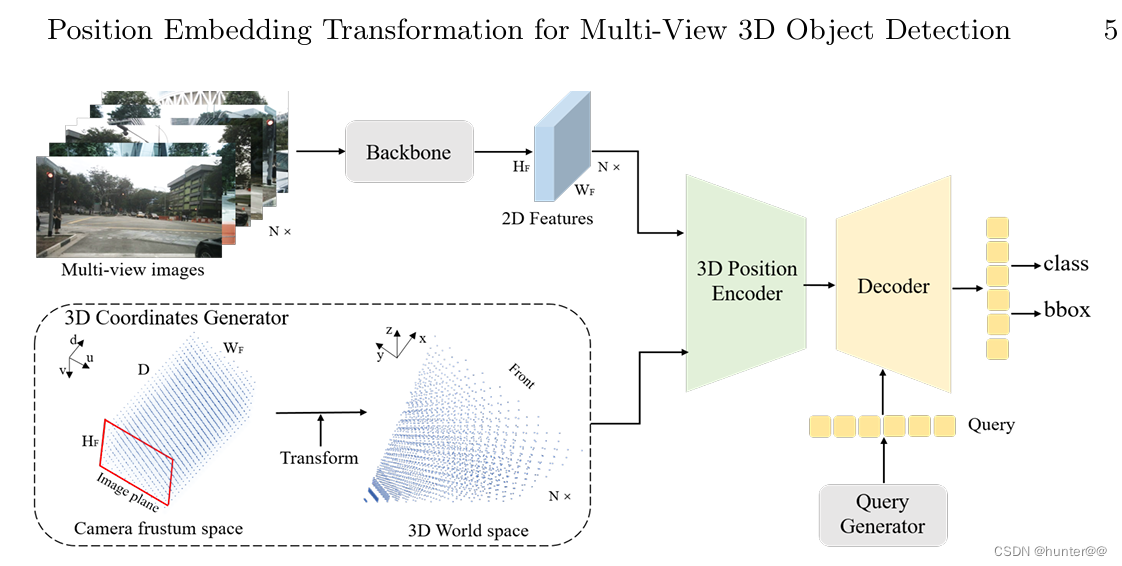
总体步骤如下:
(1)首先通过图像特征提取器,例如resnet50等,对不同视角的相机图像进行特征提取,形成一个 [bs,num_cams,Channels,H,W] 的tensor张量。
(2)之后,在像素平面使用坐标生成方法,生成一个 [W, H, D, 3] 的坐标网络coords,也就是 图2 的3D Coordinates Generator 模块的Camera frustum space部分。可以看出它是一个分布均匀的网格空间,但是不是真实的视锥空间。
(3)通过相机的坐标变换矩阵将其转换到真实的3D World space空间中,shape保持不变,仍为[W, H, D, 3]。
(4)最后会通过一个全连接层对[W, H, D, 3]的点进行embedding,和(1)提取的图像特征相加,完成3D坐标信息的嵌入工作。
2、pipeline
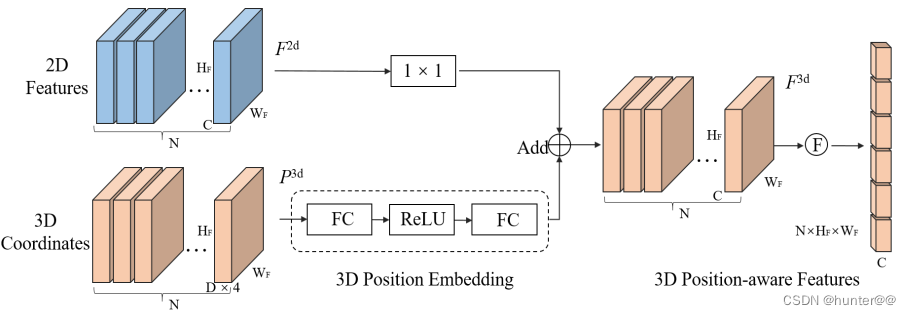
2.1 3D Position Encoder
2.1.1 原理:
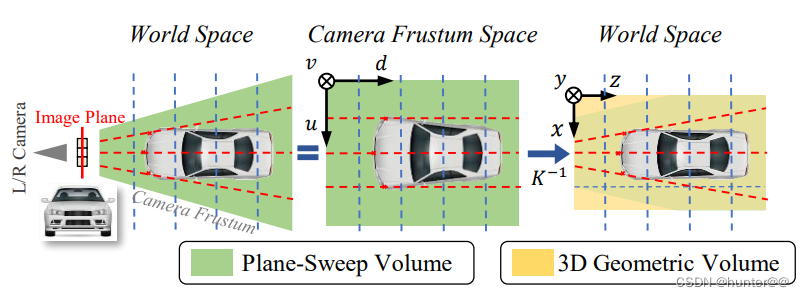
3D Position Encoder是PETR的核心创新点,其生成图像网格的方式和LSS一样,通过torch.arange函数生成长度分别为H,W,D,间隔为1的线性坐标,在将其stack起来,生成一个[H,W,D,3]的图像空间网格,也就是下图4的Camera Frustum Space空间。再concat一个全1的维度,将其转换为齐次坐标,并将其复制[B,N,1,1,1,1]份,也就是拓展到batch和num_cams维度(因为有多个相机),此时Camera Frustum Space空间的3D网格坐标的shape应该为[B,N,H,W,D,3]。
之后就是最为关键的一步,乘以相机坐标系的转换矩阵(图3),将其转换到3D Geometric Volume空间。但是其shape不变,只是空间形状发生了改变,由原来的空间正方体转换为视锥体。
最后,会再进行一些归一化和范围约束操作,防止坐标点溢出边界。再对齐进行reshape,将维度改变为[B*N,D*3,H,W],使用一个全连接层对这个D*3这个维度进行embedding,也就是进行位置编码。
注意:最后的特征全连接embedding十分重要。
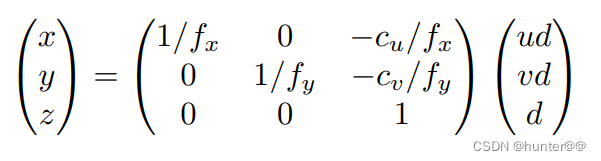
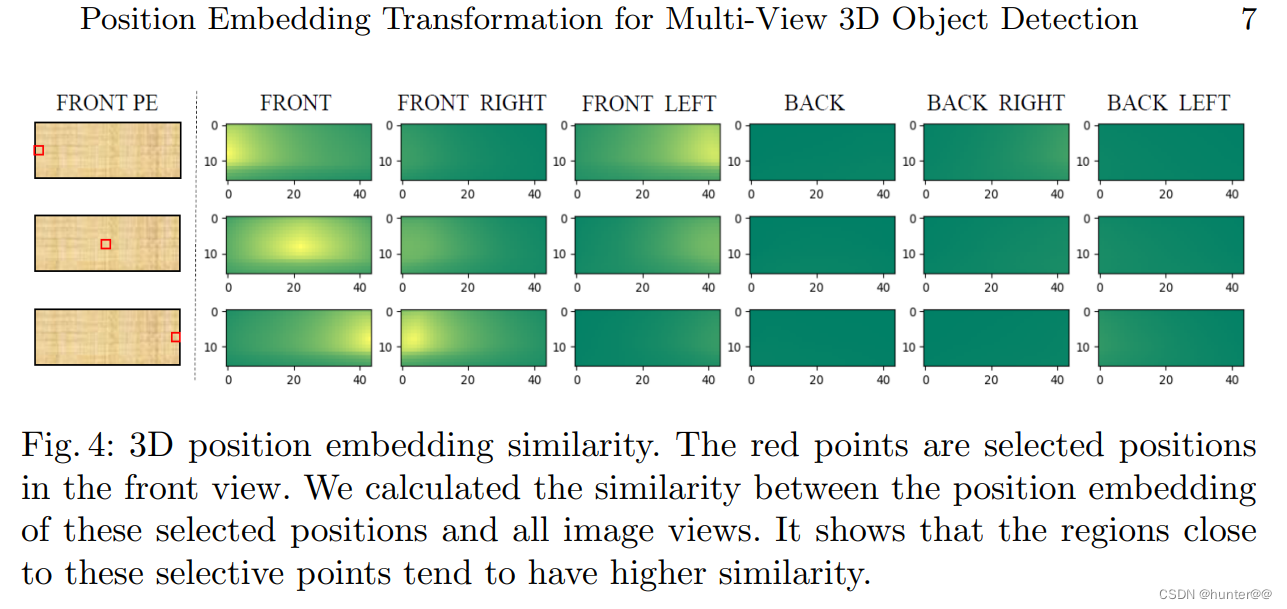
从Position Embedding的结果来看,其实起到了一定的作用,论文中的一张可视化结果可以看出:
图6 主要是前视图的Positon Embedding信息,从左侧的FRONT PE上随机选择左中右三个点,可以看出前视图左边的点只和FRONT(前方)、FRONT RIGHT(右前)、FRONT LEFT(左前)的部分对应区域相关,和BACK(后方)、BACK RIGHT(右后方)、BACK LEFT(左后方)无关。(中间和右边的点也是如此)
从相关性角度上来说Position Emedding起到了一定的作用。
2.1.2 代码:
position_embedding函数
def position_embeding(self, img_feats, img_metas, masks=None):# img_feats:[1,6,2048,16,44]
eps = 1e-5
pad_h, pad_w, _ = img_metas[0]['pad_shape'][0] # pad_h:512, pad_w:1408 , _:3
B, N, C, H, W = img_feats[self.position_level].shape # B:1, N:6, C:2048, H:16, W:44
# 生成水平坐标,
coords_h = torch.arange(H, device=img_feats[0].device).float() * pad_h / H # 16个值
# 生成垂直坐标
coords_w = torch.arange(W, device=img_feats[0].device).float() * pad_w / W # 44个值
# 生成深度坐标,
if self.LID:
# 使用二次增长的深度索引(index * index_1),这可能导致深度坐标在深度范围内更密集地分布。
index = torch.arange(start=0, end=self.depth_num, step=1, device=img_feats[0].device).float()
index_1 = index + 1 # [1,2,3,.....,64]
bin_size = (self.position_range[3] - self.depth_start) / (self.depth_num * (1 + self.depth_num))
coords_d = self.depth_start + bin_size * index * index_1
else:
# 使用线性增长的深度索引,深度坐标在深度范围内均匀分布。
index = torch.arange(start=0, end=self.depth_num, step=1, device=img_feats[0].device).float()
bin_size = (self.position_range[3] - self.depth_start) / self.depth_num
coords_d = self.depth_start + bin_size * index
D = coords_d.shape[0] # 64
# 创建网格坐标coords
# 使用 torch.meshgrid 创建一个三维网格坐标,其中 coords_w、coords_h 和 coords_d 分别代表宽度、高度和深度坐标。
# 使用 permute 重新排列坐标的维度,使其形状为 [W, H, D, 3]。
# 最后,在坐标的末尾添加一个全为1的维度,使其形状变为 [W, H, D, 4]。这通常用于齐次坐标(homogeneous coordinates)表示。
coords = torch.stack(torch.meshgrid([coords_w, coords_h, coords_d])).permute(1, 2, 3, 0) # W, H, D, 3 [44,16,64,3]
coords = torch.cat((coords, torch.ones_like(coords[..., :1])), -1) # [44,16,64,4]
coords[..., :2] = coords[..., :2] * torch.maximum(coords[..., 2:3], torch.ones_like(coords[..., 2:3])*eps) # 确保coords的前两个维度(或通道)的数据在乘以第三个维度的数据之前,该第三个维度的数据不会小于eps。这通常用于数值稳定性或防止除以零的情况。
# 提取图像到激光雷达的变换矩阵
img2lidars = []
for img_meta in img_metas:
img2lidar = []
for i in range(len(img_meta['lidar2img'])):
img2lidar.append(np.linalg.inv(img_meta['lidar2img'][i]))
img2lidars.append(np.asarray(img2lidar))
img2lidars = np.asarray(img2lidars) # [1,6,4,4]
img2lidars = coords.new_tensor(img2lidars) # (B, N, 4, 4) [1,6,4,4] 6个相机的转换矩阵
coords = coords.view(1, 1, W, H, D, 4, 1).repeat(B, N, 1, 1, 1, 1, 1) # [1,6,44,16,64,4,1]
img2lidars = img2lidars.view(B, N, 1, 1, 1, 4, 4).repeat(1, 1, W, H, D, 1, 1) # [1,6,44,16,64,4,4]
coords3d = torch.matmul(img2lidars, coords).squeeze(-1)[..., :3] # [1,6,44,16,64,3]
# 将 x, y, z 坐标分别归一化到 [0, 1] 范围。
# self.position_range 是一个包含6个元素的列表或数组,它定义了x, y, z坐标的最小值和最大值。
# [x_min,y_min,z_min,x_max,y_max,z_max]
coords3d[..., 0:1] = (coords3d[..., 0:1] - self.position_range[0]) / (self.position_range[3] - self.position_range[0])
coords3d[..., 1:2] = (coords3d[..., 1:2] - self.position_range[1]) / (self.position_range[4] - self.position_range[1])
coords3d[..., 2:3] = (coords3d[..., 2:3] - self.position_range[2]) / (self.position_range[5] - self.position_range[2])
coords_mask = (coords3d > 1.0) | (coords3d < 0.0) # [1,6,44,16,64,3]
coords_mask = coords_mask.flatten(-2).sum(-1) > (D * 0.5) # [1,6,44,16]
coords_mask = masks | coords_mask.permute(0, 1, 3, 2) # [1,6,16,44]
coords3d = coords3d.permute(0, 1, 4, 5, 3, 2).contiguous().view(B*N, -1, H, W) # [6,192,16,44]
coords3d = inverse_sigmoid(coords3d) # [1*6,64*3,16,44]
coords_position_embeding = self.position_encoder(coords3d) # [6,256,16,44] 对深度进行embedding
return coords_position_embeding.view(B, N, self.embed_dims, H, W), coords_mask # [1,6,256,16,44] [1,6,16,44]forward函数
def forward(self, mlvl_feats, img_metas):
"""Forward function.
Args:
mlvl_feats (tuple[Tensor]): Features from the upstream
network, each is a 5D-tensor with shape
(B, N, C, H, W).
Returns:
all_cls_scores (Tensor): Outputs from the classification head, \
shape [nb_dec, bs, num_query, cls_out_channels]. Note \
cls_out_channels should includes background.
all_bbox_preds (Tensor): Sigmoid outputs from the regression \
head with normalized coordinate format (cx, cy, w, l, cz, h, theta, vx, vy). \
Shape [nb_dec, bs, num_query, 9].
"""
x = mlvl_feats[0] # [1,6,2048,16,44]
batch_size, num_cams = x.size(0), x.size(1) # 1, 6
input_img_h, input_img_w, _ = img_metas[0]['pad_shape'][0] # 512, 1408
masks = x.new_ones((batch_size, num_cams, input_img_h, input_img_w)) # [1,6,512,1408]
for img_id in range(batch_size):
for cam_id in range(num_cams):
img_h, img_w, _ = img_metas[img_id]['img_shape'][cam_id]
masks[img_id, cam_id, :img_h, :img_w] = 0
x = self.input_proj(x.flatten(0,1)) # [6,256,16,44] Conv2d(2048, 256, kernel_size=(1, 1), stride=(1, 1))
x = x.view(batch_size, num_cams, *x.shape[-3:]) # [1,6,256,16,44]
# interpolate masks to have the same spatial shape with x
masks = F.interpolate(masks, size=x.shape[-2:]).to(torch.bool) # [1,6,16,44]
# 这边的位置编码信息才是PETR的重点
if self.with_position:
coords_position_embeding, _ = self.position_embeding(mlvl_feats, img_metas, masks) # [1,6,256,16,44]
pos_embed = coords_position_embeding # [1,6,256,16,44] 3D点的编码信息
if self.with_multiview:
sin_embed = self.positional_encoding(masks) # [1,6,384,16,44]
sin_embed = self.adapt_pos3d(sin_embed.flatten(0, 1)).view(x.size()) # [1,6,256,16,44] 3个卷积层进行降维
pos_embed = pos_embed + sin_embed # [1,6,256,16,44]
else:
pos_embeds = []
for i in range(num_cams):
xy_embed = self.positional_encoding(masks[:, i, :, :])
pos_embeds.append(xy_embed.unsqueeze(1))
sin_embed = torch.cat(pos_embeds, 1)
sin_embed = self.adapt_pos3d(sin_embed.flatten(0, 1)).view(x.size())
pos_embed = pos_embed + sin_embed
else:
if self.with_multiview:
pos_embed = self.positional_encoding(masks)
pos_embed = self.adapt_pos3d(pos_embed.flatten(0, 1)).view(x.size())
else:
pos_embeds = []
for i in range(num_cams):
pos_embed = self.positional_encoding(masks[:, i, :, :])
pos_embeds.append(pos_embed.unsqueeze(1))
pos_embed = torch.cat(pos_embeds, 1)
reference_points = self.reference_points.weight # [900,3]
query_embeds = self.query_embedding(pos2posemb3d(reference_points)) # [900,256]
reference_points = reference_points.unsqueeze(0).repeat(batch_size, 1, 1) # [1,900,3] .sigmoid()
outs_dec, _ = self.transformer(x, masks, query_embeds, pos_embed, self.reg_branches) # [6,1,900,256]2.2 Decoder
2.2.1 Multiheadattn
2.2.1.1 原理:
PETR中的注意力机制部分选择的是多头注意力机制,而不是之前DETR3D选择的可变行注意力机制(其实也就是特征采样),这无疑是增加了计算量,但从另一个方面来说,确实解决了DETR3D全局特征关注不足的问题。因为多头注意力机制关注的是全局信息,而不是采样的部分特征。
2.2.1.2 代码:
def forward(self,
query, # [900,1,256]
key=None, # [4224,1,256]
value=None, # [4224,1,256]
identity=None, # None
query_pos=None, # [900,1,256]
key_pos=None, # [4224,1,256]
attn_mask=None, # None
key_padding_mask=None, # [1,4224]
**kwargs):
"""Forward function for `MultiheadAttention`.
**kwargs allow passing a more general data flow when combining
with other operations in `transformerlayer`.
Args:
query (Tensor): The input query with shape [num_queries, bs,
embed_dims] if self.batch_first is False, else
[bs, num_queries embed_dims].
key (Tensor): The key tensor with shape [num_keys, bs,
embed_dims] if self.batch_first is False, else
[bs, num_keys, embed_dims] .
If None, the ``query`` will be used. Defaults to None.
value (Tensor): The value tensor with same shape as `key`.
Same in `nn.MultiheadAttention.forward`. Defaults to None.
If None, the `key` will be used.
identity (Tensor): This tensor, with the same shape as x,
will be used for the identity link.
If None, `x` will be used. Defaults to None.
query_pos (Tensor): The positional encoding for query, with
the same shape as `x`. If not None, it will
be added to `x` before forward function. Defaults to None.
key_pos (Tensor): The positional encoding for `key`, with the
same shape as `key`. Defaults to None. If not None, it will
be added to `key` before forward function. If None, and
`query_pos` has the same shape as `key`, then `query_pos`
will be used for `key_pos`. Defaults to None.
attn_mask (Tensor): ByteTensor mask with shape [num_queries,
num_keys]. Same in `nn.MultiheadAttention.forward`.
Defaults to None.
key_padding_mask (Tensor): ByteTensor with shape [bs, num_keys].
Defaults to None.
Returns:
Tensor: forwarded results with shape
[num_queries, bs, embed_dims]
if self.batch_first is False, else
[bs, num_queries embed_dims].
"""
if key is None:
key = query #
if value is None:
value = key #
if identity is None:
identity = query # [900,1,256]
if key_pos is None:
if query_pos is not None:
# use query_pos if key_pos is not available
if query_pos.shape == key.shape:
key_pos = query_pos
else:
warnings.warn(f'position encoding of key is'
f'missing in {self.__class__.__name__}.')
if query_pos is not None:
query = query + query_pos # [900,1,256]
if key_pos is not None:
key = key + key_pos # [4224,1,256]
# Because the dataflow('key', 'query', 'value') of
# ``torch.nn.MultiheadAttention`` is (num_query, batch,
# embed_dims), We should adjust the shape of dataflow from
# batch_first (batch, num_query, embed_dims) to num_query_first
# (num_query ,batch, embed_dims), and recover ``attn_output``
# from num_query_first to batch_first.
if self.batch_first:
query = query.transpose(0, 1)
key = key.transpose(0, 1)
value = value.transpose(0, 1)
out = self.attn(
query=query, # [900,1,256]
key=key, # [4224,1,256]
value=value, # [4224,1,256]
attn_mask=attn_mask, # None
key_padding_mask=key_padding_mask)[0] # [1,4224]
if self.batch_first:
out = out.transpose(0, 1)
return identity + self.dropout_layer(self.proj_drop(out)) # [900,1,256]2.2.2 decoder_layer
def forward(self, query, *args, **kwargs):
"""Forward function for `TransformerDecoder`.
Args:
query (Tensor): Input query with shape
`(num_query, bs, embed_dims)`.
Returns:
Tensor: Results with shape [1, num_query, bs, embed_dims] when
return_intermediate is `False`, otherwise it has shape
[num_layers, num_query, bs, embed_dims].
"""
if not self.return_intermediate:
x = super().forward(query, *args, **kwargs)
if self.post_norm:
x = self.post_norm(x)[None]
return x
intermediate = []
for layer in self.layers:
query = layer(query, *args, **kwargs) # [900,1,256]
if self.return_intermediate:
if self.post_norm is not None:
intermediate.append(self.post_norm(query))
else:
intermediate.append(query)
return torch.stack(intermediate) # [6,900,1,256] 不同层的decoder进行stack总结
PETR是对DETR3D改进的一次伟大尝试。本质还是通过object query和不同视角的图像特征进行交互进行隐式得进行3D检测。
主要改进点有两个:
(1)使用全局注意力机制代替了可变行注意力机制,增加了全局特征提取。
(2)添加了3D位置编码信息,对不同视觉的图像特征进行了一定的约束。
参考
论文阅读:《PETR: Position Embedding Transformation for Multi-View 3D Object Detection》_petr论文-CSDN博客
DSGN: Deep Stereo Geometry Network for 3D Object Detection


















 180
180

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









