







写在前面的话,我们建模,希望建模型做细,尤其风险类模型,切记不要以为将特征库的变量筛选出来直接扔到模型里,训练出来一版模型,发现KS0.5,AUC0.86 ,然后以为牛的不行,其实风险模型有很多坑,等着大家跳进去。
我一直觉得模型是主线,风控策略辅助模型进行风险决策,如果模型偏了,造成的损失是批量的。
切记将模型做细,做细。。。
模型搭建的一般步骤
任何一个模型在搭建过程中一般遵循如下步骤:
- 收集数据
- 确定模型预测目标
- 数据探索
- 数据整理
- 数据/变量筛选
- 模型拟合方法选择
- 模型搭建
- 模型评价
- 模型上线
其中,由于金融类模型是直接与钱相关的一类模型,所以无论是领导层还是政策组都希望模型部门输出的模型整体是稳健的。稳健的标准是什么呢,通常我们利用PSI去衡量模型与变量的稳定性。在模型搭建过程中我利用训练集与测试集构成的两个集合的PSI去衡量测试集较训练集 变量 /评分的稳定性,但这个方法相对较为粗糙。其实仔细思考一下,模型的元素是变量 + 算法,算法训练出来的权重如果保证了一致性,我们只需要保证变量分布整理保持不变,且正例在各个变量分箱中分布保持不变,便能够得到一个较为稳定的模型。
变量探索
通常我们在搭建模型的时候,都会说变量探索这个环节,但由于模型搭建的目标不同,导致其实变量探索没有统一的规范。这边文章只针对二分变量的风险模型来探讨变量变量探索。在搭建风险模型时,我们希望所有变量的稳定的,进而保证搭建的模型在时间外测试集合上有一个与训练集相似的AUC与KS(由于客群分布稳定最终体现在衡量客群分布的变量上,如果各个变量都是稳定的,客群分布一般来讲是稳定的)
背景介绍:
需要针对201801- 201812月的客群搭建一个A卡,
正例定义:未来六个月出现大于等于90天逾期
负例定义:未来六个月未出现大于等于90天逾期
经过分析将数据拆分为训练集201801 - 2018-10,测试集201811-2018-12.模型实施为20190715.显然,201901 - 201906的客户由于表现期不足导致未能进入训练样本与测试数据集。
以下针对 近三个月信贷审批查询次数 这个在信贷领域常用的变量 进行举例说明。
在数据分析工程中,我们遵循总分结构,先将数据进行汇总进行分析,然后再细化到每个月去分析。如近三个月信贷审批查询次数,我们可以将计算训练集与测试集覆盖率是否符合要求,如果不符合,这时需要Case by Case地去决定是否需要进一步分析。
覆盖率
如果变量从大的集合里面符合了基本的数据覆盖的要求,这时我们需要进一步考察变量每个月的覆盖情况,防止出现有些时间段数据大量缺失,而建模人员不知道的情况出现。
案例:
| 观测月 | 缺失个数 | 样本个数 | 覆盖率 |
|---|---|---|---|
| 201801 | 50 | 100 | 50% |
| 201802 | 40 | 100 | 60% |
| 201803 | 35 | 100 | 65% |
| 201804 | 45 | 100 | 55% |
| 201805 | 20 | 100 | 80% |
| 201806 | 40 | 100 | 40% |
| 201807 | 32 | 100 | 68% |
| 201808 | 32 | 100 | 68% |
| 201809 | 56 | 100 | 44% |
| 201810 | 70 | 100 | 30% |
| 201811 | 50 | 100 | 50% |
| 201812 | 10 | 100 | 90% |
针对上表我们发现每个月的变量覆盖率都基本满足了建模要求,但是各月样本覆盖率的波动相对较大极差达到了50%,这时建议从业务上,外部数据查询逻辑,数据准备等方向去查看一下造成变量丰羽程度不同的原因。
PSI
覆盖考察结束之后,我们需要就变量的PSI进行进一步考察,首先我们需要考察训练集与测试集PSI是否满足要求,一般认为PSI有如下表的关系,具体原因请参见我的另一篇博客 https://blog.csdn.net/fzcoolbaby/article/details/98470464。
公式:
(公式1.1)
P
S
I
=
∑
i
=
1
k
(
p
i
−
q
i
)
∗
l
n
(
p
i
q
i
)
PSI = \sum_{i=1}^k(p_{i}-q_{i})*ln(\frac{p_{i}}{q_{i}}) \tag{公式1.1}
PSI=i=1∑k(pi−qi)∗ln(qipi)(公式1.1)
| PSI取值区间 | 稳定与否 |
|---|---|
| [0,0.1) | 稳定性良好 |
| [0.1,0.25) | 稳定性一般,需要进一步考察模型,查看模型参数PSI情况 |
| [0.25,+∞ | 模型发生显著变化,需重新建模 |
建模过程中,一般要求变量PSI低于0.25即可,初筛尽量将更多的变量纳入考察范围,之后再利用业务逻辑,建模经验剔除变量。
| 近三个月信贷审批查询次数 | 训练集 | 测试集 | 训练集占比 | 测试集占比 | 训练集占比 - 测试集占比 | ln(训练集占比/测试集占比) | PSI单项取值 |
|---|---|---|---|---|---|---|---|
| 缺失 | 500 | 200 | 18% | 16% | 2% | 12.8% | 0.3% |
| 1-2 | 750 | 250 | 27% | 20% | 7% | 31.0% | 2.3% |
| 3-4 | 900 | 300 | 33% | 24% | 9% | 31.0% | 2.7% |
| 5-8 | 500 | 350 | 18% | 28% | -10% | -43.2% | 4.2% |
| >=9 | 100 | 150 | 4% | 12% | -8% | -119.4% | 10.0% |
| TTL | 2750 | 1250 | 100% | 100% | 0% | 0.0% | 19.5% |
从上表可以看出,该变量在训练集与测试集上表现较为平稳。
但由于我们上线的日期是20190715,所以我们需要进一步考察201901 - 201906期间变量分布是否文件
| 近三个月信贷审批查询次数 | 训练集 | 测试集 | 201901 | 201902 | 201903 | 201904 | 201905 | 201906 |
|---|---|---|---|---|---|---|---|---|
| 缺失 | 500 | 200 | 100 | 110 | 120 | 90 | 140 | 170 |
| 1-2 | 750 | 250 | 110 | 115 | 130 | 85 | 145 | 150 |
| 3-4 | 900 | 300 | 180 | 160 | 140 | 95 | 160 | 160 |
| 5-8 | 500 | 350 | 190 | 165 | 160 | 120 | 165 | 180 |
| >=9 | 100 | 150 | 120 | 100 | 80 | 75 | 90 | 95 |
| TTL | 2750 | 1250 | 700 | 650 | 630 | 465 | 700 | 755 |
| 近三个月信贷审批查询次数 | 测试集PSI | 201901 | 201902 | 201903 | 201904 | 201905 | 201906 |
|---|---|---|---|---|---|---|---|
| 缺失 | 0.28% | 0.94% | 0.09% | 0.04% | 0.07% | 0.17% | 0.93% |
| 1-2 | 2.26% | 6.37% | 4.15% | 1.85% | 3.60% | 1.80% | 2.35% |
| 3-4 | 2.71% | 1.69% | 2.31% | 4.07% | 5.79% | 3.54% | 5.01% |
| 5-8 | 4.24% | 3.59% | 2.40% | 2.41% | 2.67% | 1.40% | 1.53% |
| >=9 | 9.99% | 20.94% | 16.95% | 11.33% | 18.61% | 11.65% | 11.11% |
| TTL | 19.47% | 33.54% | 25.90% | 19.70% | 30.75% | 18.56% | 20.93% |
从以上两个表格可以发现,201901,201902,201904PSI均不满足要求,我们很难保证模型上线以后这个变量是稳健的,因而需要进一步考察影响变量稳定的因素,最终决定是否要放弃这个变量。
除此之外我们还需要对训练样本的PSI进行考察,比如将各月的样本分布计算好后,将每个月与201801进行比较查看变量在训练样本中是否有同样的问题(总体稳健,但各月变量分布波动较大)。
IV
IV是衡量变量所承载解释因变量的信息量,IV值越大,对于因变量的解释能力越强。这个值得计算公式与PSI基本一致,只是对比集发生了变化,PSI是定住训练集或某个月作为基础分布,利用测试集或各月的分布与基础分布进行对比。而IV是一个数据集,定住正例分布,利用在某一变量上的负例分布与正例分布进行对比,异化程度越大(IV值越大),说明这个变量对于正例与负例的区分能力越强。
IV是我们在构建风险模型时一个非常重要的统计量。
通常我们会根据训练样本集合直接计算IV,同样这样的做法相对较为粗糙,我们希望能够通过考察每个月的IV,查看这个变量在各月的IV分布情况来确定,正例/负例在这个变量的分布是否随着时间的推移保持着稳定。由于201901 - 201906表现期不足所以,无法将这个检验,一直检验到模型上线的最近一个月。
但我们可以对于训练集 与 测试集进行逐月检验。
以下是训练样本IV计算的例子
| 近三个月信贷审批查询次数 | 负例 | 正例 | 负例占比 | 正例占比 | 负例占比-正例占比 | ln(负例占比/正例占比) | IV单项取值 |
|---|---|---|---|---|---|---|---|
| 缺失 | 500 | 200 | 18% | 16% | 2% | 12.8% | 0.28% |
| 1-2 | 750 | 250 | 27% | 20% | 7% | 31.0% | 2.26% |
| 3-4 | 900 | 300 | 33% | 24% | 9% | 31.0% | 2.71% |
| 5-8 | 500 | 350 | 18% | 28% | -10% | -43.2% | 4.24% |
| >=9 | 100 | 150 | 4% | 12% | -8% | -119.4% | 9.99% |
| TTL | 2750 | 1250 | 100% | 100% | 0% | 0.0% | 19.47% |
如上表所示IV值为0.1947,这个数值已经非常大了,说明近三个月信贷审批查询次数这个变量对于模型区分正例/负例有显著的作用。
| 近三个月信贷审批查询次数 | 负例 | 正例 | 负例占比 | 正例占比 | 负例占比-正例占比 | ln(负例占比/正例占比) | IV单项取值 |
|---|---|---|---|---|---|---|---|
| 缺失 | 500 | 200 | 18% | 16% | 2% | 12.8% | 0.28% |
| 1-2 | 750 | 250 | 27% | 20% | 7% | 31.0% | 2.26% |
| 3-4 | 900 | 300 | 33% | 24% | 9% | 31.0% | 2.71% |
| 5-8 | 500 | 350 | 18% | 28% | -10% | -43.2% | 4.24% |
| >=9 | 100 | 150 | 4% | 12% | -8% | -119.4% | 9.99% |
| TTL | 2750 | 1250 | 100% | 100% | 0% | 0.0% | 19.47% |

从这个表中我们可以看出IV随着时间在训练样本IV值上下波动。
那么我们希望训练IV的解释力与各月IV一致,那么我们可以将训练样本的IV作为各月IV的均值来进行一个均值检验。
原假设:训练样本IV与各月IV均值相等
备择假设:训练样本IV与各月IV均值不相等
利用R进行上述检验:
t.test(x = c(0.15,0.16,0.19,0.18,0.25,0.17,0.12,0.23,0.24,0.19,0.11,0.3),mu = 0.1947, paired = FALSE, var.equal = T,conf.level = 0.95)
结果如下:
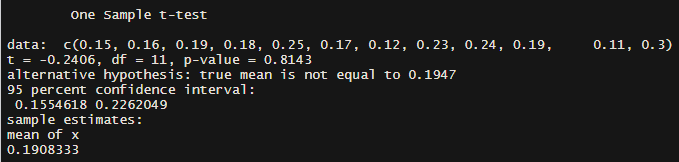
说明训练集IV值在各月中波动相对较小,能够代表该变量在各月中针对正例/负例的解释力。
WOE
说了这么多覆盖,PSI,IV,其实在风险模型搭建过程中有一个统计量是永远无法逾越的,变量的WOE,这个值与IV紧密联系。
计算案例
| 近三个月信贷审批查询次数 | 负例 | 正例 | 负例占比 | 正例占比 | WOE:ln(负例占比/正例占比) |
|---|---|---|---|---|---|
| 缺失 | 500 | 200 | 18% | 16% | -0.128 |
| 1-2 | 750 | 250 | 27% | 20% | -0.310 |
| 3-4 | 900 | 300 | 33% | 24% | -0.310 |
| 5-8 | 500 | 350 | 18% | 28% | 0.432 |
| >=9 | 100 | 150 | 4% | 12% | 1.194 |
一个好的分箱,体现在WOE成"等"梯度下降,每一档与下一档有差异,但差异不能特别大,如上一档WOE 5,下一档WOE 500,基本上落在这一档的客户瞬间就是上天入地的差异,直接变成最好或者最坏客户。类似这种WOE足够大的变量可以考虑拿来构建风控规则。
与前面的案例相同,首先针对训练样本计算WOE,再逐月查看变量WOE值,不同的是,由于IV值是变量承载的信息量,不需要进行各变量区间单独计算(亦可以,如果读者愿意),我们需要针对WOE每个分项进行WOE值稳定性考察,从表述统计上,要特别注意,变量某个取值的WOE由正转负的情况,这时需要仔细考察变量可能存在的内生问题,同时不建议将这类变量纳入模型。
检验方法与IV一致,查看每个分箱的WOE图,观察是否存在正负波动
其次检查训练样本的WOE能否表示各月WOE的均值,t检验。















 1821
1821











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









