







03. 结构化机器学习项目
第1周 机器学习策略(1)
1.1 为什么是ML策略
- 启发示例
(1)改进算法的基本方法:
a. 收集更多的数据
b. 收集更具有多样性的训练集
c. 用梯度下降法更长时间的训练算法
d. 用Adam替换梯度下降法
e. 尝试更大的网络
f. 尝试更小的网络
g.尝试Dropout
h. 增加 L 2 L_2 L2正则化
i. 改变网络的结构(激活函数,隐藏层单元个数等) - 本周课程,主要介绍如何快速判断哪些改进思想会对算法有效。
1.2 正交化
- 机器学习中的假设链
(1)在训练集上对代价函数拟合较好
(2)在验证集上对代价函数拟合较好
(3)在测试集上对代价函数拟合较好
(4)在现实中性能较好
1.3 单一数字评估指标
- 查准率定义:分类器标签为正的样本中,真实为正的样本比例。
- 查全率定义:所有真实为正的样本,被标记为正的比例。
- 查准率和查全率往往需要权衡。
- F1评分:查准率 P P P和查全率 R R R的调和平均 2 1 P + 1 R \frac{2}{\frac{1}{P}+\frac{1}{R}} P1+R12
- 另一个例子(在不同地区的猫分类的错误率)
1.4 满足和优化指标
- 另一个猫分类器的例子
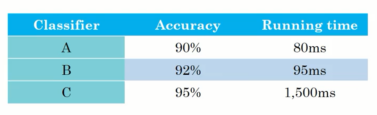
假设不仅关注准确率,也关注运行时间。假设需满足如下条件:
m a x max max a c c u r a c y accuracy accuracy
S . T S.T S.T running time ≤ 100 \leq 100 ≤100
则准确率为优化指标,运行时间为满足指标。 - 另一个例子(设备唤醒词)
优化指标:唤醒词响应准确率
满足指标:假阳性次数
1.5 训练、开发、测试集划分
- 本课主要讨论如何设定开发集合测试集
- 将全部数据随机洗牌,然后再分割为开发集合测试集(目的是确保开发集合测试集的数据分布为同分布)
- 另一个例子(邮政编码与贷款)
1.6 开发集和测试集的大小
- 分割数据的旧方法:
(1)70%训练集,30%测试集
(2)60%训练集,20%开发集,20%测试集
上述分割适用于规模较小的数据集(10K) - 现有的数据集规模较大(百万级),因此分割可按照98%训练集,1%开发集,1%测试集进行分割。
1.7 什么时候该改变开发、测试集和指标
- 猫数据集例子
(1)指标:分类错误率
(2)算法A:3%错误率,算法B:5%错误率
(3)但算法A会推送色情图片,算法B不会。因此对于公司和用户来说,算法B是更好地算法,尽管算法A的错误率更低。
(4)错误率公式:
e r r = 1 m d e v ∑ i = 1 m d e v I { y p r e d ( i ) ≠ y ( i ) } err = \frac{1}{m_{dev}}\sum_{i=1}^{m_dev}I\{y_{pred}^{(i)} \neq y^{(i)}\} err=mdev1∑i=1mdevI{ypred(i)=y(i)}
(5)错误率公式修正:
e r r = 1 ∑ ω ( i ) ∑ i = 1 m d e v ω ( i ) I { y p r e d ( i ) ≠ y ( i ) } err = \frac{1}{\sum \omega^{(i)}}\sum_{i=1}^{m_dev}\omega^{(i)} I\{y_{pred}^{(i)} \neq y^{(i)}\} err=∑ω(i)1∑i=1mdevω(i)I{ypred(i)=y(i)}
其中,
ω ( i ) = { 1 x ( i ) 不 是 色 情 图 片 10 x ( i ) 不 是 色 情 图 片 \omega^{(i)=}\begin{cases} 1 & x^{(i)}不是色情图片\\ 10 & x^{(i)}不是色情图片 \end{cases} ω(i)={110x(i)不是色情图片x(i)不是色情图片 - 猫图片的正交化
(1)目前为止我们仅讨论了如何定义评价指标
(2)还需要关心如何在该指标下进行优化
1.8 为什么是人的表现
- 与人类表现的对比

紫色实线:机器学习算法性能
蓝色虚线:人类表现
绿色虚线:贝叶斯最优错误率,理论最优解 - 为什么同人类表现比较
当ML性能比人类差时,可以:获得标记数据,分析误差原因,分析方差、偏差原因。
1.9 可避免偏差
- 猫分类器例子
(1)
人类错误率:1%
训练集错误率:8%
开发集错误率:10%
此时应进一步对训练集进行拟合,以减少偏差 。
(2)
人类错误率:7.5%
训练集错误率:8%
开发集错误率:10%
此时应进一步尝试正则化,以减少算法的方差。 - 定义(可避免误差):贝叶斯错误率和训练集错误率间的差值。
1.10 理解人的表现
1.11 超过人的表现
1.12 改善你的模型的表现
- 监督学习的两个基本假设
(1)训练集拟合较好(偏差小)
(2)开发集和测试集上泛化性能较好(方差小) - 降低可避免偏差和方差
(1)可避免偏差(训练更大的模型,训练更长或更好的优化算法,寻找更好的神经网络结构和超参)
(2)方差(更多的数据,正则化)















 702
702











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









