







 介绍Apache Flink在实时数据处理中的应用,涵盖流批一体架构、实时计算、数据同步及监控告警系统等内容,适用于多种业务场景。
介绍Apache Flink在实时数据处理中的应用,涵盖流批一体架构、实时计算、数据同步及监控告警系统等内容,适用于多种业务场景。
目录
应用场景
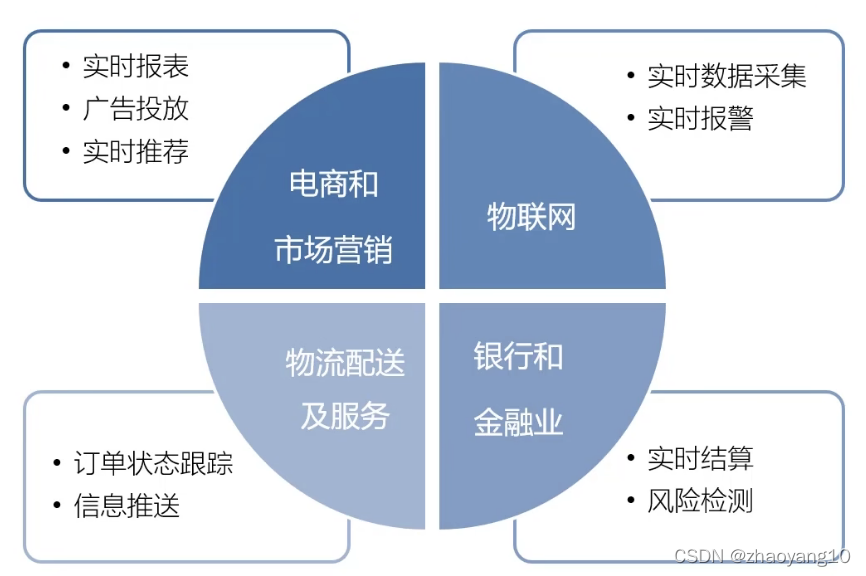
Apache Flink 是 Apache 软件基金会的顶级项目,也是当下被广泛使用的开源大数据计算引擎之一。基于它 “流批一体” 的技术,越来越多的企业选择 Apache Flink 应用于自身的业务场景,如数据集成、数据分析、数据仓库、实时分析、实时大屏等场景中,解决实时计算的需求。近年来,Apache Flink 开始广泛应用于推荐、广告和搜索等机器学习业务场景,已覆盖近百家企业的绝大多数实时计算需求,包括互联网娱乐、游戏、电商、金融、证劵、通信等多个行业。
目前 Flink 基本服务于阿里的所有 BU ,在双十一峰值的计算能力达到 40 亿条每秒,计算任务达到了 3 万多个,总共使用 100 万+ Core ;几乎涵盖了集团内的所有具体业务,比如:数据中台、AI 中台、风控中台、实时运维、搜索推荐等。
优势
流批一体
高吞吐、低延迟
exactly-once 的状态一致性保证
结果的准确性和良好的容错性
可以众多常用的存储系统连接
高可用,支持动态扩展
应用案例
基于 Apache Flink 和规则引擎的实时风控解决方案
Apache Flink X Apache Doris 构建极速易用的实时数仓架构
Flink 使用教程
Flink 从 0 到 1 学习 —— Flink Data transformation(转换)
Flink 开源项目系统
flink-recommandSystem-demo: 基于Flink实现的商品实时推荐系统
flink-userportrait-main: 基于Flink流处理的动态实时亿级全端用户画像系统
Flink 电商用户行为统计 流量统计 近期热门商品统计 用户画像分析 商品推荐 风控
flink-streaming-platform-web: 基于flink-sql的实时流计算web平台
Flink SQL
文档
flink sql 示例
flink sql kafka canal-json source
Flink 如何将聚合结果写入kafka ——读写canal-json
mysql --> canal --> kafka --> flink sql --> doris
vi products_kafka_to_doris.sql
SET parallelism.default = 1;
SET execution.checkpointing.interval = 3s;
SET sql-client.execution.result-mode = tableau;
CREATE TABLE products_kafka_source (
id INT,
name STRING,
description STRING
) WITH (
'connector' = 'kafka',
'topic' = 'fms_test_mysql_topic',
'properties.bootstrap.servers' = '10.18.2.221:9094',
'properties.group.id' = 'flink_kafka_test',
'format' = 'canal-json',
'scan.startup.mode' = 'latest-offset'
);
CREATE TABLE products_doris_sink (
id INT,
name STRING,
description STRING
) WITH (
'connector' = 'doris',
'fenodes' = '10.18.2.23:8030',
'benodes' = '10.18.2.23:8040',
'table.identifier' = 'app_db.ods_products',
'username' = 'root',
'password' = ''
);
INSERT INTO products_doris_sink SELECT id, name, description FROM products_kafka_source;
启动 ./bin/sql-client.sh -f products_kafka_to_doris.sql
source 打印
drop table if exists print_table;
CREATE TABLE print_table WITH ('connector' = 'print')
LIKE products_kafka_source (EXCLUDING ALL)
时间窗口
Flink SQL流表与维表join 和 双流join
Flink-join(流表关联流表,流表关联维表),自定义函数
Flink SQL实践记录4 – 实时更新的维表如何join
Flink CDC
使用 Flink CDC 构建 Streaming ETL | Apache Flink CDC
Flink CDC,实现Mysql数据增量备份到Clickhouse
Flink CDC采集MySQL binlog日志实时写入ClickHouse
flink cdc mysql --> elasticsearch
Flink SQL CDC 上线!我们总结了 13 条生产实践经验
flink cdc mysql --> apache doris
flink-cdc官网 MySQL 同步到 Doris | Apache Flink CDC
测试脚本
注意事项:
flink 启动配置修改 conf/flink-conf.yaml
jobmanager.bind-host: 改成 0.0.0.0
taskmanager.bind-host: 改成 0.0.0.0
taskmanager.numberOfTaskSlots: 改成 5
parallelism.default: 改成 10
增加 execution.checkpointing.interval: 3000
rest.bind-address: 改成 0.0.0.0
web.cancel.enable: 改成 true
mysql库名和doris库名不相同时必须得配置route参数 必须mysql表与doris表一对一配置。如果mysql有的表但route没配置cdc也会报错
vi mysql-to-doris.yaml
source:
type: mysql
hostname: localhost
port: 5985
username: root
password: test123244
tables: flink_test.\.*
server-id: 5400-5404
server-time-zone: UTC
sink:
type: doris
fenodes: 10.18.25.21:8030
benodes: 10.18.25.21:8040
username: root
password: ""
table.create.properties.light_schema_change: true
table.create.properties.replication_num: 1
route:
- source-table: flink_test.orders
sink-table: app_db.ods_orders
- source-table: flink_test.shipments
sink-table: app_db.ods_shipments
- source-table: flink_test.products
sink-table: app_db.ods_products
pipeline:
name: Sync MySQL Database to Doris
parallelism: 2
启动脚本
bash bin/flink-cdc.sh mysql-to-doris.yaml --jar lib/mysql-connector-java-8.0.27.jar --flink-home /data0/flink/flink-1.18.0
flink cdc 实时统计计算
mysql --> Canal --> kafka --> Flink --> HDFS
Dinky
Dinky官网: Dinky 是一个开箱即用的一站式实时计算平台,以 Apache Flink 为基础,连接 OLAP 和数据湖等众多框架,致力于流批一体和湖仓一体的建设与实践。
docker 部署
docker run -d --restart=always --net=host -e MYSQL_ADDR=m3309i.grid.xxxx.com.cn:3309 -e MYSQL_DATABASE=dlink -e MYSQL_USERNAME=mis -e MYSQL_PASSWORD=12434qwer --name dinky dinkydocker/dinky-standalone-server:0.7.5-flink16
docker cp dinky:/opt/dinky/plugins .
docker run增加 -v /data0/dinky/plugins:/opt/dinky/plugins
基于 Dinky + FlinkSQL + Flink CDC 同步 MySQL 数据到 Elasticsearch、Kafka
Flink部署
flink flink-cdc 相关jar包
flink flink-cdc jar
flink-sql-connector-kafka jar
flink-sql-connector-mysql-cdc jar
flink-doris-connector jar
不带sql的jar包 需手动引入第三方依赖jar包 比如kafka clients jar 版本要对应
flink-connector-kafka-1.17.2.jar
kafka-clients-3.2.3.jar
kafka-clients jar
flink sql mysql jdbc相关jar包
flink-connector-jdbc-3.0.0-1.16.jar
注意:新增jar包记得重启
docker 部署flink
docker pull flink:1.17.0
# 创建 docker 网络,方便 JobManager 和 TaskManager 内部访问
docker network create flink-network
# 创建 JobManager
docker run \
-itd \
--name=jobmanager \
--publish 8081:8081 \
--network flink-network \
--env FLINK_PROPERTIES="jobmanager.rpc.address: jobmanager" \
flink:1.16.0 jobmanager
# 创建 TaskManager
docker run \
-itd \
--name=taskmanager \
--network flink-network \
--env FLINK_PROPERTIES="jobmanager.rpc.address: jobmanager" \
flink:1.16.0 taskmanager
mkdir /data0/flink
docker cp jobmanager:/opt/flink/conf conf
docker cp jobmanager:/opt/flink/lib lib
# 启动 jobmanager
docker run -itd -v /data0/flink/conf/:/opt/flink/conf/ -v /data0/flink/lib/:/opt/flink/lib/ --name=jobmanager --publish 8081:8081 --env FLINK_PROPERTIES="jobmanager.rpc.address: jobmanager" --network flink-network flink:1.16.0 jobmanager
# 启动 taskmanager
docker run -itd -v /data0/flink/conf/:/opt/flink/conf/ -v /data0/flink/lib/:/opt/flink/lib/ --name=taskmanager --network flink-network --env FLINK_PROPERTIES="jobmanager.rpc.address: jobmanager" flink:1.16.0 taskmanager
docker exec -it jobmanager ./bin/sql-client.sh
docker-compose 部署flink
部署命令:
cd /data0
mkdir flink
mkdir flink/conf
mkdir flink/lib
#docker pull flink:1.14.4-scala_2.12
docker pull flink:1.13.6-scala_2.11
vi docker-compose.yml
version: "2.1"
services:
jobmanager:
image: flink:1.13.6-scala_2.11
expose:
- "6123"
ports:
- "8081:8081"
command: jobmanager
#volumes:
#- /data0/flink/lib:/opt/flink/lib
#- /data0/flink/conf:/opt/flink/conf
environment:
- JOB_MANAGER_RPC_ADDRESS=jobmanager
taskmanager:
image: flink:1.13.6-scala_2.11
expose:
- "6121"
- "6122"
depends_on:
- jobmanager
command: taskmanager
links:
- "jobmanager:jobmanager"
environment:
- JOB_MANAGER_RPC_ADDRESS=jobmanager
#volumes:
#- /data0/flink/lib:/opt/flink/lib
#- /data0/flink/conf:/opt/flink/conf
启动:
docker-compose build
docker-compose up -d --force-recreate
docker-compose down
docker-compose restart
查看日志:
docker logs --tail="600" flink_jobmanager_1
docker logs -f flink_taskmanager_1
配置 flink-sql-connector-mysql-cdc-2.2.0.jar:
docker cp lib/flink-sql-connector-mysql-cdc-2.2.0.jar flink_jobmanager_1:/opt/flink/lib
docker cp flink_jobmanager_1:/opt/flink/conf /data0/flink/
docker cp flink_jobmanager_1:/opt/flink/lib /data0/flink/
打开docker-compose.yml注释内容 配置本地文件映射路径
volumes:
- /data0/flink/lib:/opt/flink/lib
- /data0/flink/conf:/opt/flink/conf
docker-compose up -d --force-recreate
使用flink sql-client:
docker exec -it flink_jobmanager_1 /bin/bash
./bin/sql-client.sh
或:
docker exec -it flink_jobmanager_1 ./bin/sql-client.sh
mac 安装flink 指定版本
下载flink 找到需要的版本进行下载
https://www.apache.org/dyn/closer.lua/flink/
我下载的版本:
https://dlcdn.apache.org/flink/flink-1.13.6/flink-1.13.6-bin-scala_2.11.tgz
vi ~/.bash_profile中追加
alias flink="/Users/zhaoyang10/Documents/flink/flink-1.13.6/bin/flink"
终端执行:
flink --version
启动flink
cd /Users/zhaoyang10/Documents/flink/flink-1.13.6/bin
启动命令
./start-cluster.sh
停止命令
./stop-cluster.sh
执行job任务:
flink run -d /Users/zhaoyang10/Documents/git/bop-data-sync/data-sync-flink/target/data-sync-flink-1.0.0.jar
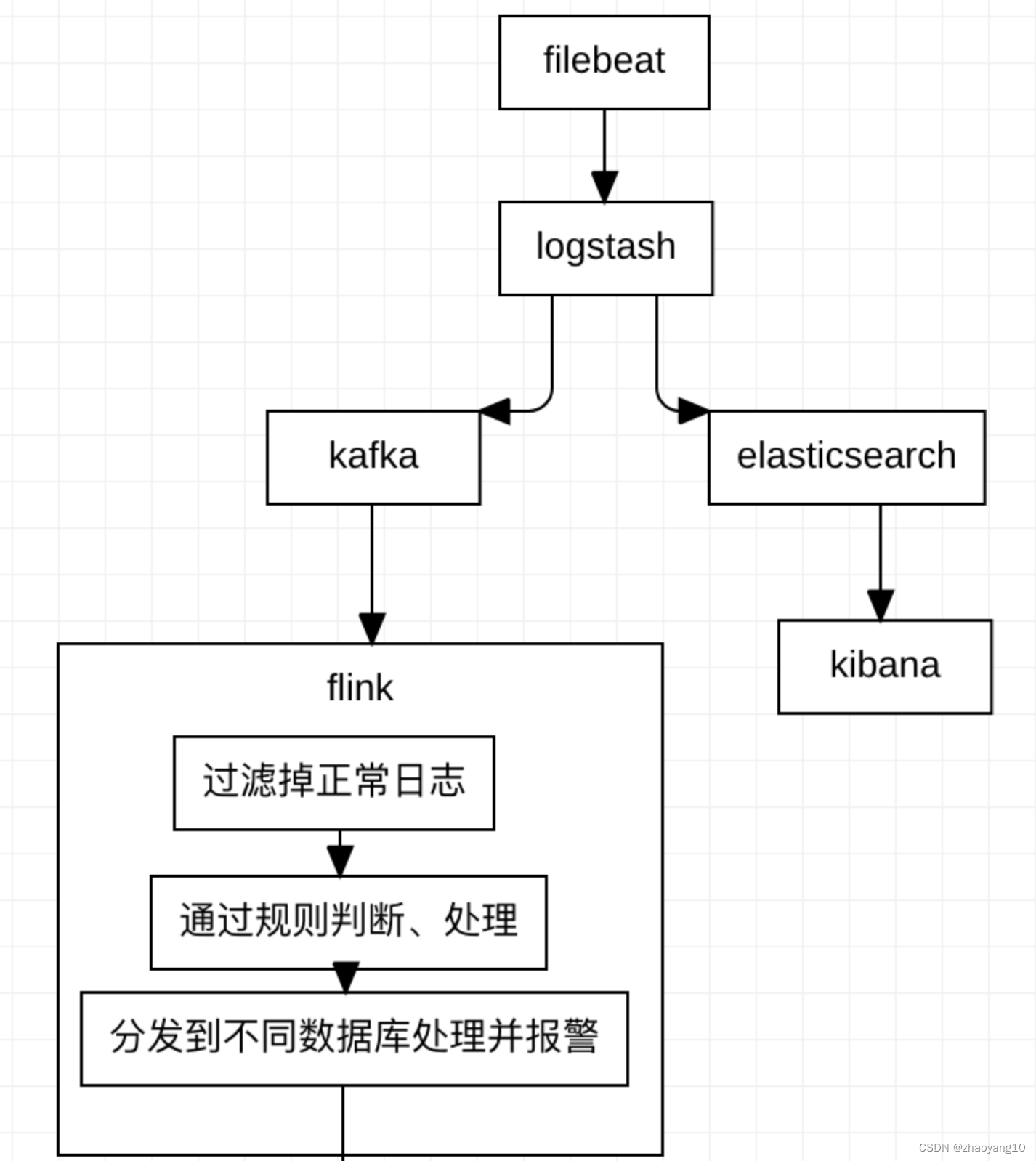
flink 日志实时监控告警系统

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









