







一、前言
1.1 使用全连接神经网络对图像进行处理存在的问题
1、需要处理的数据量大,效率低
现在的图像都有着极高的像素,假设一张需要处理的图片像素是 1000 * 1000 * 3(彩色图片,具有 RGB 3 个通道),使用具有 100 个隐藏单元的单隐藏层 MLP,模型就有 1000 * 1000 * 3 * 100 = 3 亿个参数,这个模型需要训练的参数数量是巨大的,使用全连接网络训练效率极为低下。
2、图像在维度调整过程中难以保留原有的特征,导致图像处理的准确度不高
回想一下,之前我们将多层感知机模型应用于MNIST数据集中的手写数字图片。 为了能够应用多层感知机,我们首先将每个大小为 28×28 的图像展平为一个 784 维的固定长度的一维向量,然后用全连接层对其进行处理。
当我们对图像进行 Flatten 处理时,很可能改变了图像所表示的信息。举例如下:
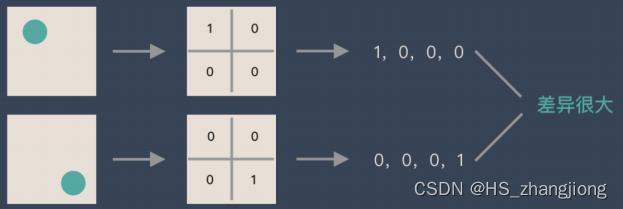
假如有圆形是1,没有圆形是0,那么圆形的位置不同就会产生完全不同的数据表达。但从图像的角度来看,图像的内容(本质)并没有发生变化,只是位置发生了变化。
1.2 卷积神经网络(CNN)的构成
CNN 网络主要有三部分构成: 卷积层、池化层(汇聚层)和全连接层组成,其中卷积层负责提取图像中的局部特征;池化层用来降低参数数量(降维);全连接层类似人工神经网络的部分,用来输出想要的结果。
了解卷积操作可参考这篇文章: 卷积神经网络(CNN)——图像卷积_HS_zhangjiong的博客-CSDN博客_图卷积神经网络实现
本文介绍卷积神经网络中的开山之作---LeNet
参考论文---《Handwritten Digit Recognition with a Back-Propagation Network》、《Gradient-Based Learning Applied to Document Recognition》
二、LeNet 介绍
LeNet 是一系列网络结构,包括 LeNet1-LeNet5。它最早发布的卷积神经网络之一,因其在计算机视觉任务中的高效性能而受到广泛关注。 这个模型是由贝尔实验室的研究员Yann LeCun在1989年提出的(并以其命名),目的是识别图像中的手写数字。
总体来看,LeNet(LeNet-5)由两个部分组成:
-
卷积编码器: 由两个卷积层组成;
-
全连接层密集块: 由三个全连接层组成
如下图所示:
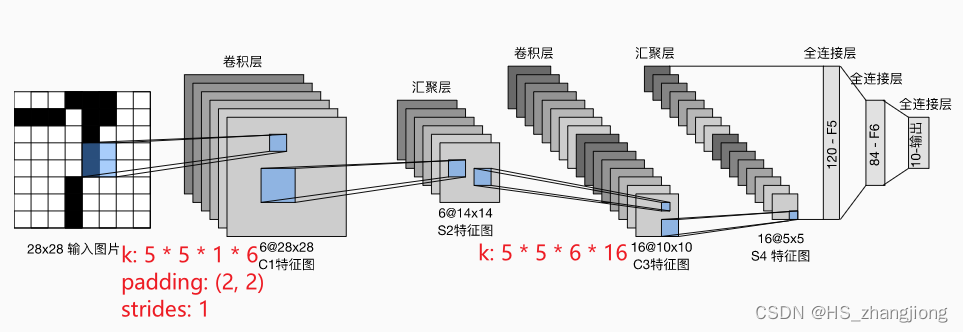
论文中的 LeNet-5 网络架构图如下:
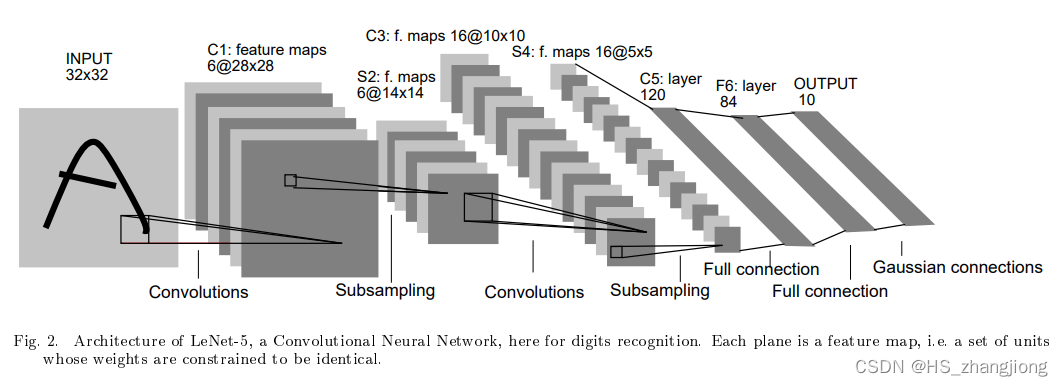
每个卷积块中的基本单元是一个卷积层、一个 sigmoid 激活函数和平均汇聚层。每个卷积层使用 5×5 卷积核和一个 sigmoid 激活函数。这些层将输入映射到多个二维特征输出,通常同时增加通道的数量。第一个卷积层有6个输出通道,而第二个卷积层有16个输出通道。每个 2×2 池化操作(strides = 2)通过空间下采样将维数减少4倍。卷积的输出形状由批量大小、通道数、高度、宽度决定。
为了将卷积块的输出传递给稠密块,我们必须在小批量中展平每个样本。换言之,我们将这个四维输入(batch_size, height, width, channel)转换成全连接层所期望的二维输入。这里的二维表示的第一个维度索引小批量中的样本,第二个维度给出每个样本的平面向量表示。LeNet 的稠密块有三个全连接层,分别有120、84和10个输出。因为我们在执行分类任务,所以输出层的10维对应于最后输出结果的数量。
三、LeNet-5 代码实现(TensorFlow)
本文使用的 tensorflow 版本为 2.10.0。
论文中 LeNet 池化层使用的是平均池化层,后续证明最大池化更有效,所以本文使用最大池化层。
同时本文的数据集是 MNIST 数据集。
import tensorflow as tf
# 数据集
from tensorflow.keras.datasets import mnist1. 数据集加载
# 数据集加载
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
test_labels.shape![]()
2. 数据处理
卷积神经网络的输入要求是: B, H, W, C
批量大小、图片高度、宽度、通道数
# 维度调整
train_images = tf.reshape(train_images, (train_images.shape[0], train_images.shape[1], train_images.shape[2], 1))
print(train_images.shape)
test_images = tf.reshape(test_images, (test_images.shape[0], test_images.shape[1], test_images.shape[2], 1))
print(test_images.shape)
3. 模型搭建
LeNet-5 模型输入得是二维图像,先经过两次卷积层,两次池化层,再经过全连接层,最后用 softmax 分类作为输出结果。
# 模型构建
net = tf.keras.models.Sequential([
# 卷积层: 6 个 5*5 的卷积核,激活函数是 sigmoid
tf.keras.layers.Conv2D(filters=6, kernel_size=(5, 5), padding='same', activation='sigmoid', input_shape=(28, 28, 1)),
# max pooling
tf.keras.layers.MaxPool2D(pool_size=2, strides=2),
# 卷积层: 16 5 * 5 sigmoid
tf.keras.layers.Conv2D(filters=16, kernel_size=(5, 5), activation='sigmoid'),
# max pooling
tf.keras.layers.MaxPool2D(pool_size=2, strides=2),
# 维度调整 将 feature map 拉成一个向量
tf.keras.layers.Flatten(),
# 全连接层 sigmoid
tf.keras.layers.Dense(120, activation='sigmoid'),
# 全连接层 sigmoid
tf.keras.layers.Dense(84, activation='sigmoid'),
# 输出层 softmax
tf.keras.layers.Dense(10, activation='softmax')
])使用 net.summary() 查看网络结构

4. 模型编译
设置优化器和损失函数
# 优化器和损失函数
net.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=0.6), loss=tf.keras.losses.sparse_categorical_crossentropy, metrics=['accuracy'])5. 模型训练
# 指明训练数据和验证集
net.fit(train_images, train_labels, epochs=10, batch_size=128, validation_split=0.1)训练过程如下:

6. 模型评估
score = net.evaluate(test_images, test_labels, verbose=1)
print(f'Test accuracy: {score[1]}')
本文训练后的 LeNet-5 对手写数字数据集的测试精度达到了 97.8%,还是不错的。














 1141
1141











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









