








目录
本篇博客教大家使用MNIST数据集基于Pytorch框架实现比较经典的一种卷积神经网络:LeNet。
运行环境:python 3.6.12,pytorch 1.6.0,torchvision 0.7.0
一、准备MNIST数据集
MNIST是一个非常经典的手写字数据库,官网网址请点击此处,需要的可自行下载。不过,Pytorch为我们提供了快速下载并加载MNIST数据集的方法,本博客采用此方法下载数据集,具体代码如下:
from torchvision import datasets, transforms
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])
# 读取测试数据,train=True读取训练数据;train=False读取测试数据
# 下载完成后改为download=False
trainset = datasets.MNIST('data', train=True, download=False, transform=transform)
testset = datasets.MNIST('data', train=False, download=False, transform=transform)其中transforms是图像数据预处理的方法。transforms.ToTensor()是将数据转化为Tensor对象,transforms.Normalize()是对数据进行归一化。具体用法可上网查找,或看官方手册。datasets.MNIST的第一个参数指定了数据集下载和存储的文件夹,可根据需要修改。train=True表示读取训练数据,train=False表示读取测试数据。download=False表示不下载MNIST数据集,因为博主已经下载过,所以是False,如果没有下载将其改为True,下载完成后改为False即可。transform=transform表示使用上面的数据预处理方法对MNIST数据集进行处理。
设置好相应参数之后(download=True),运行上述代码即可自动下载MNIST数据集,并保存到同目录下的data文件夹。

二、LeNet模型构建
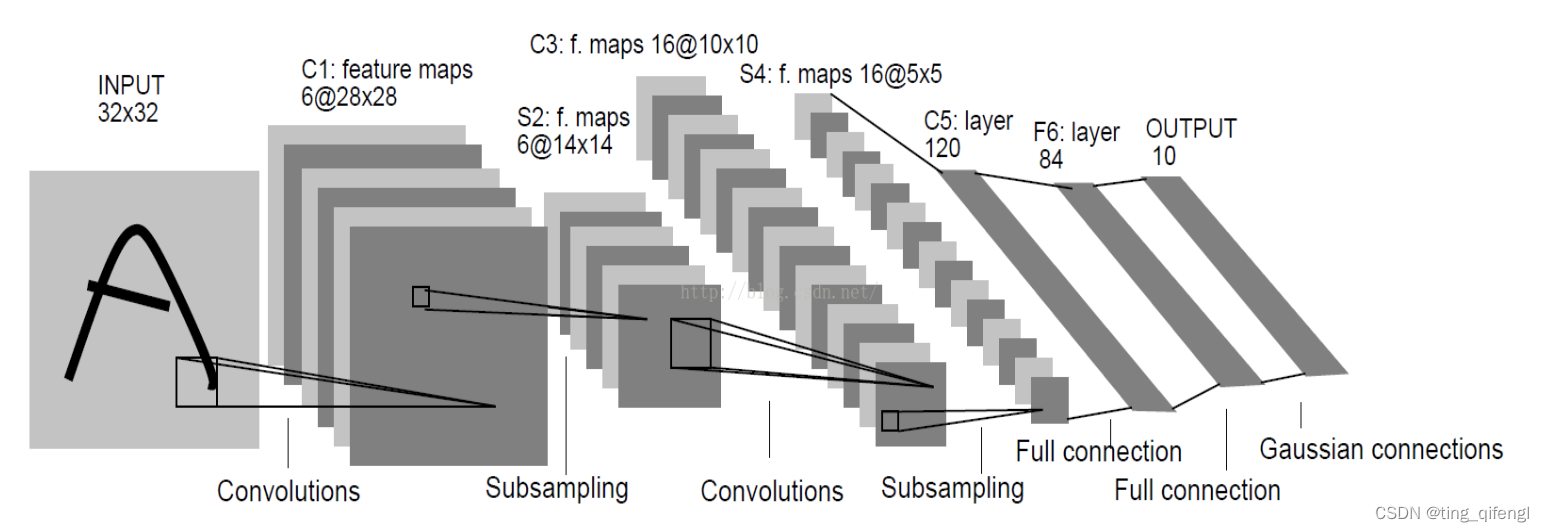
接下来构建LeNet模型。LeNet的网络结构如下图所示,一共7层。其中C1,C3,C5为卷积层,S2,S4为降采样层,F6为全连接层,还有一个输出层。网络结构比较简单,这里不进行具体分析,想要了解的可自行查找。
具体代码如下:
from torch import nn
from torch.nn.functional import max_pool2d, relu
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.Conv1 = nn.Conv2d(1, 6, 5)
self.Conv2 = nn.Conv2d(6, 16, 5)
self.Conv3 = nn.Linear(16 * 4 * 4, 120)
self.fc1 = nn.Linear(120, 64)
self.fc2 = nn.Linear(64, 10)
def forward(self, x):
x = max_pool2d(relu(self.Conv1(x)), kernel_size=2)
x = max_pool2d(relu(self.Conv2(x)), kernel_size=2)
x = x.view(-1, 16 * 4 * 4)
x = relu(self.Conv3(x))
x = relu(self.fc1(x))
x = self.fc2(x)
return x定义了LeNet类,首先运行父类初的始化函数,并对LeNet的各个层进行了实现。然后定义了forward()函数,即前向传播。
接下来初始化LeNet,并设置使用CPU或GPU运行。使用交叉熵损失函数,Adam优化器,出示学习率设置为0.001。如果电脑有GPU则在GPU上运行,反之在CPU上运行。
device = torch.device('cpu')
if torch.cuda.is_available():
device = torch.device("cuda:0")
print('Training on GPU.')
else:
print('No GPU available, training on CPU.')
lenet = LeNet().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(lenet.parameters(), lr=1e-3)接下来,使用Dataloader加载训练集。shuffle=True表示打乱数据顺序。
train_loader = DataLoader(trainset, batch_size=8, shuffle=True)在上述工作完成后,开始对网络进行训练。设置epoch=5,使用enumetrate加载数据,并进行前向传播与反向传播。每一千个batch输出一次训练结果,如果训练损失低于1e-5,则保存模型并停止训练。
epochs = 5
for epoch in range(epochs):
train_loss = 0.0
for i, data in enumerate(train_loader, 0):
inputs, labels = data
outputs = lenet(inputs.to(device))
loss = criterion(outputs, labels.to(device))
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
if (i + 1) % 1000 == 0:
print('Epoch: [{}/{}], Batch:{}, Loss:{:.5f}'.format(epoch + 1, epochs, i + 1, train_loss / (i + 1)))
if (train_loss / (i + 1)) < 1e-5:
torch.save(lenet.state_dict(), 'lenet.pt') # save model parameters to files
print(
'Epoch [{}/{}], Batch:{}, Loss: {:.5f}'.format(epoch + 1, epochs, i + 1, train_loss / (i + 1)))
print("The loss value is reached")
break
train_loss = 0.0在训练完成后,使用测试集测试模型的泛华效果,避免过拟合。仍然使用Dataloader加载测试集。
test_loader = DataLoader(testset, batch_size=8, shuffle=False)对测试模块进行完善,统计测试结果,并输出测试集准确率。
total = 0.0
correct = 0.0
for data in test_loader:
inputs, labels = data
outputs = lenet(inputs.to(device))
pred_labels = torch.argmax(outputs.data, 1)
labels = labels.to(device)
total += labels.size(0)
correct += (pred_labels == labels).sum()至此,数据集加载、模型的构建、训练与测试全部完成。
三、完整代码
完整代码如下。
"""
pytorch实现LeNet
"""
from torchvision import datasets, transforms
import torch
from torch import nn
from torch.utils.data import DataLoader
from torch.nn.functional import max_pool2d, relu, softmax
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.Conv1 = nn.Conv2d(1, 6, 5)
self.Conv2 = nn.Conv2d(6, 16, 5)
self.Conv3 = nn.Linear(16 * 4 * 4, 120)
self.fc1 = nn.Linear(120, 64)
self.fc2 = nn.Linear(64, 10)
def forward(self, x):
x = max_pool2d(relu(self.Conv1(x)), kernel_size=2)
x = max_pool2d(relu(self.Conv2(x)), kernel_size=2)
x = x.view(-1, 16 * 4 * 4)
x = relu(self.Conv3(x))
x = relu(self.fc1(x))
x = self.fc2(x)
return x
if __name__ == "__main__":
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])
# 读取测试数据,train=True读取训练数据;train=False读取测试数据
# 下载完成后改为download=False
trainset = datasets.MNIST('data', train=True, download=False, transform=transform)
testset = datasets.MNIST('data', train=False, download=False, transform=transform)
device = torch.device('cpu')
if torch.cuda.is_available():
device = torch.device("cuda:0")
print('Training on GPU.')
else:
print('No GPU available, training on CPU.')
lenet = LeNet().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(lenet.parameters(), lr=1e-3)
epochs = 5
train_loader = DataLoader(trainset, batch_size=8, shuffle=True)
for epoch in range(epochs):
train_loss = 0.0
for i, data in enumerate(train_loader, 0):
inputs, labels = data
outputs = lenet(inputs.to(device))
loss = criterion(outputs, labels.to(device))
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
if (i + 1) % 1000 == 0:
print('Epoch: [{}/{}], Batch:{}, Loss:{:.5f}'.format(epoch + 1, epochs, i + 1, train_loss / (i + 1)))
if (train_loss / (i + 1)) < 1e-5:
torch.save(lenet.state_dict(), 'lenet.pt') # save model parameters to files
print(
'Epoch [{}/{}], Batch:{}, Loss: {:.5f}'.format(epoch + 1, epochs, i + 1, train_loss / (i + 1)))
print("The loss value is reached")
break
train_loss = 0.0
torch.save(lenet.state_dict(), 'lenet.pt') # save model parameters to files
test_loader = DataLoader(testset, batch_size=8, shuffle=False)
total = 0.0
correct = 0.0
for data in test_loader:
inputs, labels = data
outputs = lenet(inputs.to(device))
pred_labels = torch.argmax(outputs.data, 1)
labels = labels.to(device)
total += labels.size(0)
correct += (pred_labels == labels).sum()
print('Accuracy on the test set: {:.2f}'.format(100 * correct / total))














 186
186











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









