







Rasa NLU负责意图(intent)识别和实体(entity)提取。例如当用户键入“明天北京的天气如何?”,Rasa NLU识别该句子的意图为查询天气,相应的实体信息包括:明天是日期;北京是城市。
Rasa NLU使用基于监督学习的算法来实现功能,因此需要开发者提供适当数量的语料,语料包含意图信息和实体信息。从结构上来说,训练数据都在键为nlu的列表中。列表中每个元素都是一个字典,依靠字典中某个具有特殊含义的键来区分不同字典的功能。如intent键表示意图识别的相关训练语料,除此外还有同义词(synonym)、查找表(lookup)、正则表达式(regex)等键。
Rasa NLU的训练数据为YAML格式。YAML是一种通用的数据存储和交换格式,具有可读可写性好、编程语言支持度广的优点。
Intent意图
具有intent键表明当前的对象是用来存储训练样例的。intent对应的值是意图名。训练样例对象有一个名为examples的列表,每个列表里面都是训练样本,如下所示:
nlu:
- intent: greet
examples: |
- 你好!
- 您好!
- hello!
- 喂!
- 在吗?
- 在?
- hi!
- 摩西摩西
- intent: goodbye
examples: |
- 再见
- 拜拜
- 拜!
- 退出
- 结束
- 溜了
- 那行吧
- 就这样吧除此外,训练数据还可以用Markdown语法中URL的表示方法,也就是[实体值](实体类型名)。例如,[明天](日期)[上海](城市)的天气如何?其中,包含两个实体类型,分别是:日期和城市,对应的实体值分别为明天和上海。
Rasa更为复杂的标记情况增加了一种语法:[实体值]{"key":"value",...},其中,{"key":"value",...}部分是一个有效的JSON格式的字典。例如:
[明天]{"entity":"日期"}[上海]{"entity":"城市"}的天气如何?Synonym同义词
具有synonym键表明当前的对象是用来存储同义词信息的。例如,魔都是上海的同义词,后者更为正式,如下所示:
nlu:
- synonym: 北京
examples: |
- 首都
- synonym: 上海
examples: |
- 魔都上述配置表明,提取的实体值是首都时,将实体的具体值替换为标准词:北京。这个特性只会修改实体的值,并不会影响实体的类型。
注意:同义词是在实体被识别后,实体的值被替换成标准值的过程中使用的,因此同义词定义不会对实体识别的提高有帮助,只会帮助后续对话处理动作更统一地处理实体的值。
Lookup查找表
具有lookup键表明当前的对象是用来存储查找表的。在实体提取和意图识别的时候,如果开发者能给这些组件一些额外的特征,那么将提高这些组件的精确度。其中一种方式就是提供一个特征词列表,这个特征词列表就是查找表,如下所示为城市的查找表的部分数据:
nlu:
- lookup: cities
examples: |
- 江宁区
- 常德市西洞庭管理区
- 常德市津市市
- 桂阳县
- 日喀则市桑珠孜区
- 白碱滩区
- 黑龙江省哈尔滨市
- 成武
- 兴隆台区
- 大悟县
- 两当县合法的城市名是可以穷举的,因此可以做成一个查找表。有了查找表特征的支持,模型就拥有了更多的知识进行预测。模型会重点考虑这些查找表所标记的词句,因此,即使推理时出现了训练数据中没有出现的城市,模型也能在查找表特征的帮助下,正确地提取出城市名。
Regex正则表达式
具有regex键表明当前的对象是用来存储正则表达式的。利用正则表达式匹配某种模式后,将这种模式是否出现作为特征传给NER组件或意图识别组件,以提高组件的性能。
正则表达式有很多优点,如使用常规的NER组件提取身份证号码、电话号码和IP地址这类实体时很难做到非常精准,但使用正则表达式就可以轻松完成。因此在特别规则的NER识别过程中,可以利用正则表达式特征提高识别精确率,如下所示为车牌的正则表达式:
nlu:
- regex: car_type
examples: |
- ^[a-zA-Z][0-9]$ 正则表达式和查找表的使用
在Rasa中,正则表达式和查找表可以通过2种方式使用:
1.作为NER组件的输入特征之一。
一个足够聪明的NER组件应该能在特征中发现规律,适当地使用开发者提供的建议信息。如开发者提供的特征只建议模型输入可能是车牌号,而不是肯定其就是车牌号。模型需要根据上下文信息决定是否采用建议。正则特征只是一种帮助模型提取文本特征的手段,开发者依旧要定义意图和实体的训练样本。需要注意的是,为了让模型能够学习查找表特征对模型预测的影响,用户要确保在训练数据中有部分数据和查找表特征词汇一致,否则模型会认为预测结果和正则表达式或查找表之间不存在任何关联。另外,开发者要保证查找表数据中的数据没有错误或噪声,否则可能适得其反(模型过度信任正则表达式或查找表提供的特征),模型性能将下降。
2.作为NER组件的输入。
Rasa中有RegexEntityExtractor组件,可以按照正则表达式和查找表数据提取实体,这是一种非常机械的实体提取手段,但在某些场合下非常实用。
组件
Rasa NLU在软件架构上设计得很灵活,允许开发者使用不同的算法来实现功能,这些算法的具体实现被称为组件(component)。 此外,为了让组件灵活配置和维持正确的前后组件的依赖关系,Rasa NLU引入了基于有向无环图的组件配置系统。有向无环图描述了模型中组件之间的依赖关系,以及数据如何在它们之间流动。在Rasa NLU中,该无环图被称为流水线(pipline)。为了完成实体提取和意图识别两个任务,一个典型的Rasa NLU流水线通常包含以下组件:
1.语言模型组件
2.分词组件
3.特征提取组件
4.NER组件
5.意图分类组件
6.结构化输出组件
每一类组件都支持开发人员对其进行配置和定制,前一个组件的输出是后一个组件的输入,最开始的输入是原始的用户消息,NLU管道最终得到意图和实体的预测结果,会作为对话管理模块中Policy的输入,用来预测下一步将要采用的Action。
组件具有以下特征:
1.组件之间的顺序至关重要。有些组件需要依赖其他组件提供输入,如NER组件需要前面的组件提供分词结果才能正常工作。
2.组件是可以相互替换的。例如可以选择不同的分词器组件来完成分词任务。
3.有些组件是互斥的。例如分词结果不能同时由两个分词器提供,否则会造成混乱。
4.有些组件是可以同时使用的。例如可以同时选择多个特征提取组件。
总的来说,Rasa NLU管道就是一个完整的意图分类和实体提取的机器学习项目,只不过Rasa对每一部分进行了模块化处理,方便开发者使用和自定义某个特定的组件。下图为Rasa3.0支持的组件:
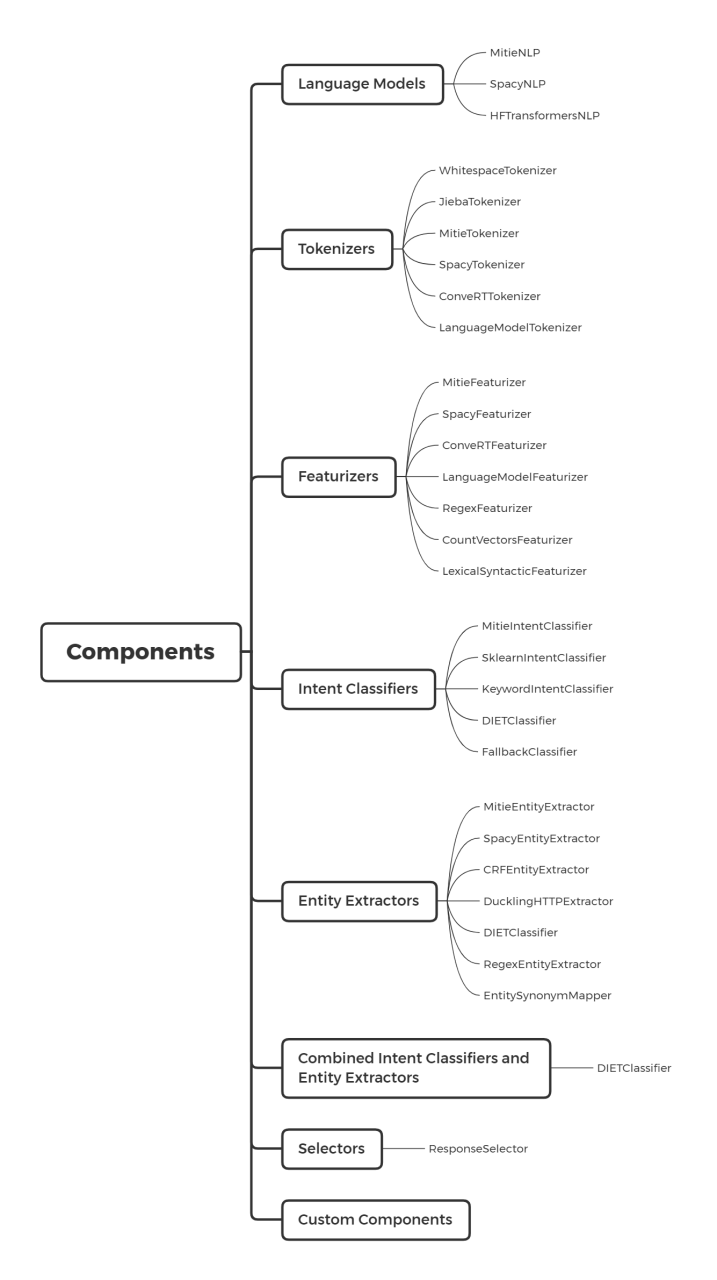
Language Model语言模型组件
语言模型。主要用于加载预训练模型。为后续的组件提供框架支持。
Tokenizers分词组件
分词器,将文本分割成token,便于导入featurizer进行特征化处理,为后续的高级NLP任务提供基础数据。
Featurizers特征提取组件
文本特征提取器,分为稀疏特征提取器和密集特征提取器。
从token中提取特征,特征种类包括稀疏sparse特征和稠密dense特征。所有Featurizer都可以返回两种不同的特征:序列特征和句子特征。序列特征是(number-of-tokens x feature-dimension)维度的矩阵,矩阵包含了句子中每个Token的特征向量,用这个特征去训练序列模型,如实体识别。句子特征由(1 x feature-dimension)大小矩阵表示,它包含完整对话的特征向量,可以用于意图分类等。
Entity Extractors实体提取组件
根据前文提供的特征对文本进行命名实体的提取。实体提取器从用户消息中提取实体,例如人名和位置。
实体提取有三种方法:
1.使用预训练模型:Duckling e.g. 提取数字,日期,url,邮箱地址等。SpaCy e.g. 提取名字,商品名称,地点等。
2.使用正则 Regex (eg. RegexEntityExtractor):适用于满足特定规则的实体。RegexEntityExtractor 不需要训练示例来学习提取实体,但至少需要提供两个带注释的实体examples,以便 NLU 模型可以在训练时将其标记为实体。
nlu:
- regex: car_type
examples: |
- ^[a-zA-Z][0-9]$ 3.使用机器学习的方法。nlu.yml 配置训练数据:实体识别的训练数据需要将文本里的实体内容用[ ]括起,后面接其所属的实体名称(entity_name)。
nlu:
- intent: 手机产品介绍
examples: |
- 这款手机[续航](property)怎么样呀?Intent Classifiers意图识别组件
意图分类器,把domain.yml中定义的意图之一分配给传入的用户信息。
Rasa NLU提供了两种方法进行意图识别:
1. Pretrained Embeddings:使用spaCy等加载预训练模型,赋予每个单词word embedding。Rasa NLU会将一条信息中的所有embedding取平均值,然后通过gridsearch搜索支持向量分类器的最优参数
2. Supervised Embeddings:从开始训练word embedding。得到embedding之后通过分类模型得到intent。
Combine Ientent Classifiers and Entity Extractors
同时实现意图分类和实体提取:DIETClassifier。
Selectors
根据候选的responses预测机器人的response。
Custom Components
自定义组件。

















 327
327

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









