







 ELECTRA是一种预训练模型,通过生成器和判别器的对抗训练,提出了更有效的预训练任务——替换令牌检测(RTD),以提高模型训练效率。与BERT的掩码语言建模不同,ELECTRA的权重共享和优化的预训练策略使其在NLP任务中表现出更高的效率和性能。
ELECTRA是一种预训练模型,通过生成器和判别器的对抗训练,提出了更有效的预训练任务——替换令牌检测(RTD),以提高模型训练效率。与BERT的掩码语言建模不同,ELECTRA的权重共享和优化的预训练策略使其在NLP任务中表现出更高的效率和性能。

ELECTRA模型的创新可以简单理解为其预训练方法的创新,在transformer火热的当下,大的预训练模型的差别主要就在于其选择的预训练任务不同。
BERT类的掩码语言建模(MLM)预训练方法在下游 NLP 任务上产生了出色的结果,但它们需要大量的计算才能有效。这些方法通过用 [MASK] 替换一些token来破坏输入,然后训练模型以恢复原始token。
ELECTRA提出了一种更加sample-efficient的预训练任务,称为replaced token detection替换令牌检测(RTD)。在该方法中,通过使用从生成器采样的合理的替代token来替换部分输入token从而破坏输入。然后训练一个判别器模型,该模型可以预测输入中的每个tokrn是否被生成器替换,而不是训练一个预测被替换的token的原始token的模型。
ELECTRA结构
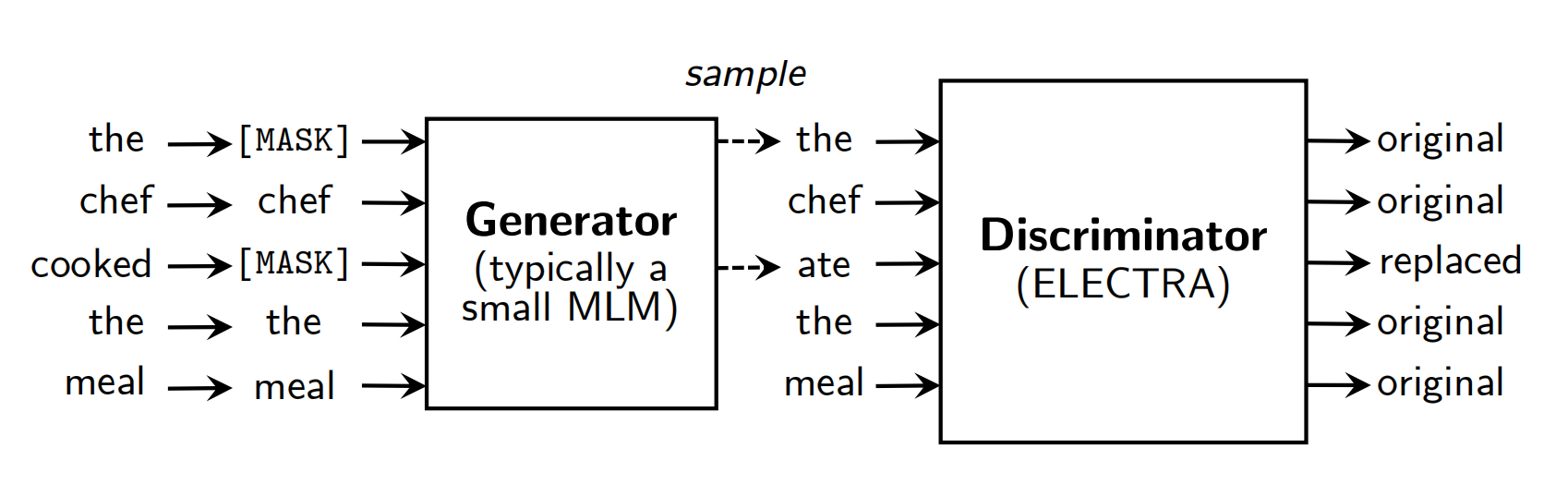
ELECTRA由两部分组成,分别是生成器generator和判别器discriminator,两个都采用了transformer的encoder结构,只是两者的size不同:
Generator
generator是一个小的masked language model(通常是 1/4 的discriminator的size),它采用了经典的bert的MLM方式,具体功能:
1.首先随机选取15%的tokens,替代为[MASK]token,(取消了bert的80%[MASK],10%unchange, 10%random replaced的操作,bert如此做是为了缓解预训练与微调时的不匹配,而在electra中没必要,因为electra在finetuning时使用的是其discriminator部分,所以不存在不匹配的现象);
2.使用generator去训练模型,使得模型预测masked token,得到corrupted token;
3.generator的目标函数和bert一样,都是希望被masked的token能够被还原成原本的original token;
如上图所示,generator随机mask了两个token,分别是the和cooked,经过生成器预测,得到对应的corrupted token,其中the预测成功,而cooked变为了ate。
Discriminator
discriminator的输入是generator对tokens进行corrupt之后的输出,如上例中的the chief ate the meal,discriminator的作用是分辨输入的每一个token是original的还是replaced,注意:如果generator生成的token和原始token一致,那么这个token仍然是original的,如上例中的the。所以对于每个token,discriminator都会进行一个二分类,最后获得在所有token上的loss。
模型拓展
权重共享
generator和discriminator之间存在weight共享,但是并不是所有的参数都共享,如果是这样的话,那需要两者的size一样,所以模型只共享了generator的embedding 权重。
为什么会选择共享embedding 权重呢,主要的原因是generator采用了MLM的方式训练,MLM根据token周围的context预测该token,可以很好地学习到embedding的表示。
生成器尺寸选择
论文中作者采用了生成器和判别器两个模块共同训练的方式进行模型训练,文章中提到了,如果generator过强,那么discriminator就无法成功训练。这其实很好理解,因为如果generator非常强,那么其预测出来的token都非常好,即都是original token,那么discrinator 并不需要如何学习就收敛,因为它只需要把所有二分类都认为是1就行(假设1代表real)。
因此,generator不能过大,否则会过于powerful。而且如果它和discrinator一样大的话,那么模型训练一次相当于要训练两个MLM的参数,也不能达到efficiency的效果。
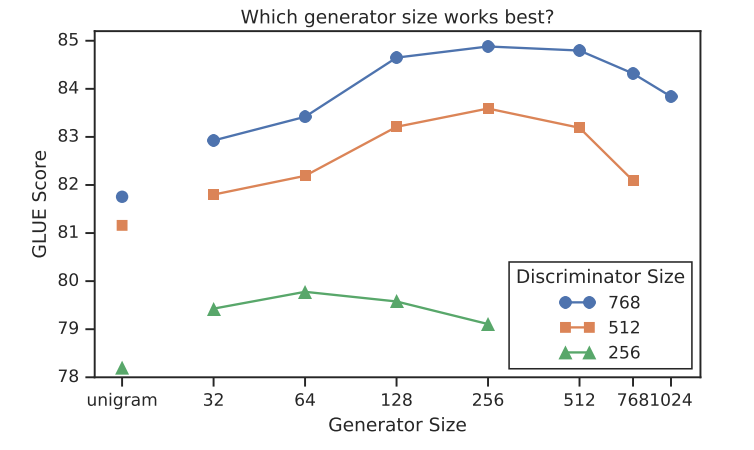
从图中可以看出,模型在生成器大小为鉴别器大小的1/4-1/2时工作得最好。
训练方法对比
论文中还提出了 ELECTRA 的其他训练算法,尽管这些最终并没有改善结果。
Two-Stage ELECTRA:
仅使用
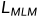 训练生成器 n 步。
训练生成器 n 步。
用生成器的权重初始化判别器的权重,然后使用
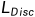 训练判别器 n 步,并且冻结生成器的权重。
训练判别器 n 步,并且冻结生成器的权重。
注意,此过程中的权重初始化要求生成器和判别器具有相同的大小。我们发现,如果不进行权重初始化,则判别器有时甚至无法学习,这可能是因为生成器的起步时间远早于判别器。另一方面,联合训练自然为判别器提供了一个课程,使生成器起步较弱,但在整个训练过程中却变得更好。
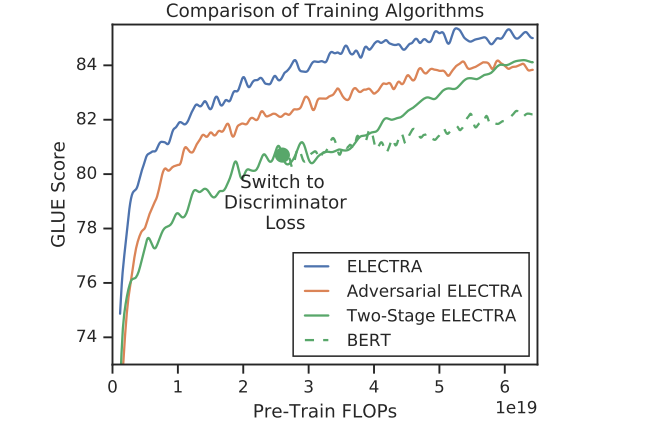
从图中可以看出,在两阶段训练期间,从生成目标变为判别目标后,下游任务性能显着提高,但最终表现不及联合训练。此外也可以看到,对抗ELECTRA虽然高于BERT但仍然不及联合训练。
为什么共同训练会使得模型效果更好?其实我们可以把generator当作是出题人,discriminator当作是答题者:模型在训练过程中,出题人出的题越来越有水平,答题者也随着积累越来越厉害,而不是刚开始出题人出的题目就非常复杂,答题人根本没办法学习。
在 BERT中,mask是随机的,很容易会出现mask的token是非常简单的。然而,在ELECTRA中,corrupted token是有一定难度的,而不是简单的mask,所以使discriminator能更好的学习。
比如说,输入是:一个聪明的模型,如果随机mask就是:一[MASK]聪明[MASK]模型, 那么对模型来说很简单。而一个[MASK][MASK]的模型,对模型来说就更复杂。使用高质量的mask进行训练,那么模型就能学得更好。
discriminator 的二分类模型,将MLM连接在一起,它不需要考虑到每个position的数据分布,能够达到更高效训练的成果。
比如小时候学习语文,老师为了加深学生对汉语的理解,总是给出一段话,把一些词去掉(当然老师会有目的性的选词,BERT是随机的),让学生根据上下文来填写空缺词。学生可能会很快地根据上下文或者常识填好空缺词(MLM)。这时,语文老师加大了难度,给出一段话,让学生挑出这段话中哪里地方用词不当。这就是ELECTRA判别器的预训练任务(RTD)。
模型有效性分析
为了更好地了解 ELECTRA 的收益来自何处,作者比较了一系列其他的预训练目标:
ELECTRA 15%: 判别器的损失只来自于 15%的 tokens,即来自于被替换的tokens而不是所有tokens;
Replace MLM: 与MLM类似,但是用生成器模型生成的标记而不是[MASK]去替换 token,这测试了 ELECTRA 对MLM的两阶段 mismatch 问题的解决效果;
All-Tokens MLM: 和Replace MLM类似,不过模型可以预测所有tokens的身份,而不仅仅是被掩盖的tokens。

首先,可以发现,对所有输入token(而不只是一个子集)计算损失,ELECTRA 将从中受益匪浅:ELECTRA 15%的性能要比 ELECTRA 差得多。
其次,可以发现 BERT 的两阶段 mismatch 会稍微损害其性能,因为 Replace MLM 的性能略好于BERT。BERT已经包含了一种技巧,以帮助改善预训练和微调时的差异:被屏蔽的token在 10% 的时间内被替换为随机token,并在 10% 的时间内保持不变。但是,实验结果表明,这些简单的启发式方法不足以完全解决问题。
最后,我们发现 All-Tokens MLM 填补了 BERT 和 ELECTRA 之间的差异。
总体而言,以上结果表明,ELECTRA 的大量改进主要是由于模型对所有token的学习,另一小部分是因为缓解了两阶段的失配。
ELECTRA VS BERT
ELECTRA的创新点:
提出了新的模型预训练的框架,采用generator和discriminator的结合方式,但又不同于GAN;
将Masked Language Model的方式改为了replaced token detection;
因为masked language model根据token周围的context预测该token,能有效地学习到context的信息,所以能很好地学习embedding,因此使用了weight sharing的方式将generator的embedding的信息共享给discriminator;
dicriminator 预测了generator输出的每个token是不是original的(二分类),从而高效地更新transformer的各个参数,使得模型的收敛速度加快;
ELECTRA采用了小的generator以及discriminator的方式共同训练,并且采用了两者loss相加,使得discriminator的学习难度逐渐地提升,学习到更难的token(plausible tokens);
模型在fine-tuning 的时候,丢弃generator,只使用discrinator;
BERT的不足:
BERT的MLM的实现,并不是非常高效的,只有15%的tokens对参数的更新有用,其他的85%不参与gradients的update;
BERT存预训练和fine-tuning的mismatch,因为在fine-tuning阶段,并不会有[MASK]的token。
整理:

















 73
73

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









