







tags: python,数据分析,pandas,numpy,Series,DataFrame,matplotlib,pyplot,scipy
目录
文章目录
一、pandas数据处理
1.1.检测重复数据及删除
使用duplicated()函数检测重复的行,返回元素为布尔类型的Series对象,每个元素对应一行,如果该行不是第一次出现,则元素为True。
1. 直接查询
示例见下:
上图中没有出现有行数据重复的现象,所以执行函数.duplicated()的结果后都为False。该函数的返回值为Series类型
2. 给定查询方向
下面为存在重复数据的示例;

上面的图中存在两行重复的数据,由于该函数默认是从最低行往后扫描,但是此处给了参数keep='last',即指定从最高往最低扫描,所以会先扫描到2行数据,然后再到1行的数据,发现1行数据和之前扫描的2行数据相同,则会在1行出显示True
3. 给定查询的范围
同样可以指定查找重复数据的集合,比如下面的示例:
上图中第二行和第一行数据中前三列相同,但是最后一列不同,如果直接使用重复查询,则不会判定重复,但是这里给定了参数subset=['A','B','C'],所以会只在这三列中查询,最后一行不在查询的范围,最后给出上图的结果。
4. 找出重复的行

上图中数据1行和2行重复,使用函数.drop_duplicates()可以把查找重复为True的那一行丢弃。同样也可以通过.duplicated()方法查找重复,然后将其得到的bool数据取反,赋给原数据,对于DataFrame数据,后面跟的中括号中给数据类型为bool值的Series数据的话,会返回Series数据中对应为True的行 #F44336。
1.2.映射
映射的含义:创建一个映射关系表(字典类型),把values元素和一个特定的标签或者字符串绑定。
需要使用字典:
map = {
'label1':'value1',
'label2':'value2',
...
}
包含三种操作:
replace()函数:替换元素- 最重要:
map()函数:新建一列 #F44336 rename()函数:替换索引
1. replace()函数:替换元素
使用replace()函数,对values进行替换操作
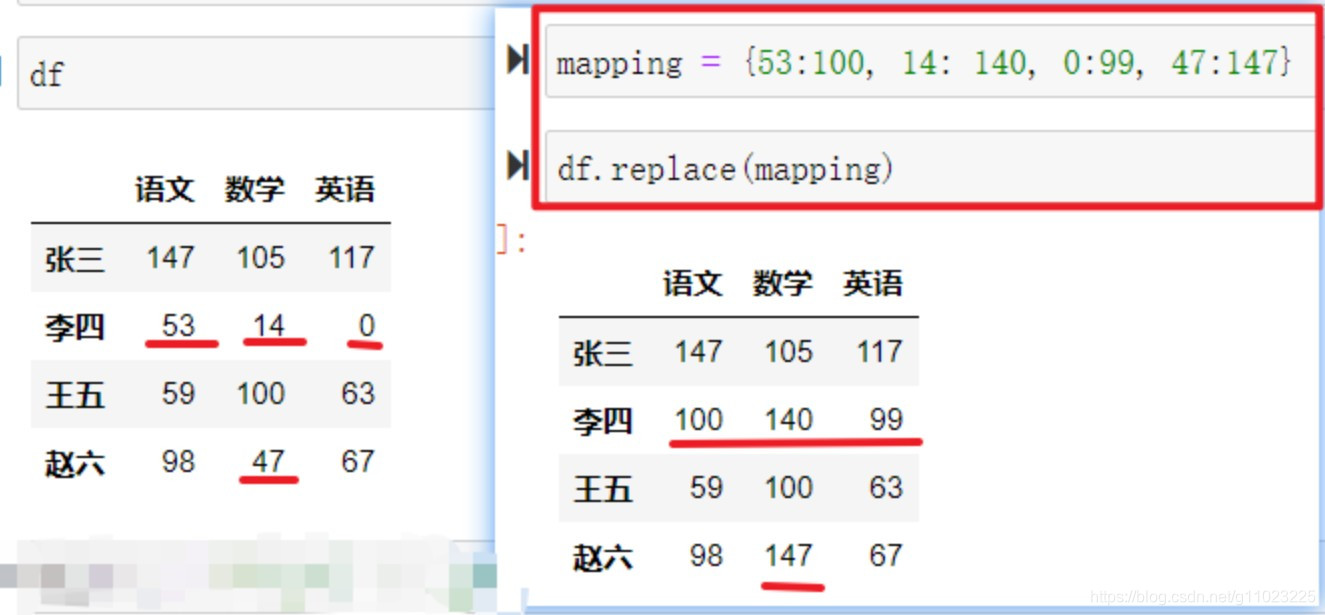
使用映射,首先需要使用字典的方式,建立一个映射关系,使用.replace()函数调用这个映射,则会在调用者中查找映射字典的key,将其替换为对应的value
.replace()还经常用来替换NaN元素
2. map()函数:新建一列
使用map()函数,由已有的列根据一定的条件生成一个新列(如果将生成的新列重新赋值给原来的数据,则可以达到修改原数据的效果)。
适合处理某一单独的列。
上图中表示,从数据df的数学列找到与map()函数中映射对应的数据,根据映射中的关系生成一个新的列,然后赋值给df数据中的理综列,由于理综之前不存在,所以会新建一列。
map()函数中可以使用函数作为参数(自定义函数或者lambda函数)
上图中,匿名函数会自动读取df数据中英语列的每一个数据,并执行函数中的操作,最后返回执行结果,然后将每个数据的执行结果新建一列,赋给df的及格与否列。
使用自定义函数的方式和上面类似,只不过可以实现更复杂的情况。
3. rename()函数:替换索引
首先使用字典的方式,建立原数据行索引或者列索引和要替换的数据之前的映射关系,然后通过指定axis值的方式或者直接给定参数index或者columns的值来修改行或者列索引的值
1.3.抽样
使用.take()函数排序。通过给定第一个参数为列表,列表中每一项的值对应行或者列的隐式索引值,值出现的先后顺序,将会影响值对应的行或者列出现的先后顺序。通过指定axis的值,可以实现对行或者列进行排序。
通过上面图片执行结果可以看出,函数的第一个参数值为列表,其中的数据对应着行或者列的隐式索引值,其中数据位置的先后顺序,会影响最后排序的结果。
通过.take()函数和np.random.permutation()、np.random.randint()的配合,可以实现无放回随机抽样和有放回随机抽样,见下图。
1. 无放回抽样
np.random.permutation()函数会将其接受的列表参数中的每一项值,随机排列,每次运行的排序结果都不同,所以上图中给列表为[0,1,2,3],每次运行其中的值位置都不同,所以就实现了对行数据的无放回随机抽样。
2. 有放回抽样
np.random.randint()函数给定随机数范围和长度,可以产生随机np数据,由于每次的数据都是在0-4(不包含4)中产生,所以可以实现有放回的随机抽样。
1.4.数据聚合【重点】
数据聚合是数据处理的最后一步,通常是要使每一个数组生成一个单一的数值。
数据分类处理步骤:
- 分组:先把数据分为几组
- 用函数处理:为不同组的数据应用不同的函数以转换数据
- 合并:把不同组得到的结果合并起来
数据分类处理的核心: groupby()函数
上面的数据执行了分组操作之后,其得到的数据为一个字典,其中的key为之前数据中分组列中的数据,值为该数据所对应的有相同值的隐式索引。
首先使用分组函数指定分组的列名color,接着使用双中括号的方式获取分组后列price对应的结果,并且返回值还是DataFrame,最后对该数据聚合求和,得到每组的和。求和后的数据行索引为分组后得到的字典的key值(注意:推荐先取列,然后再聚合)
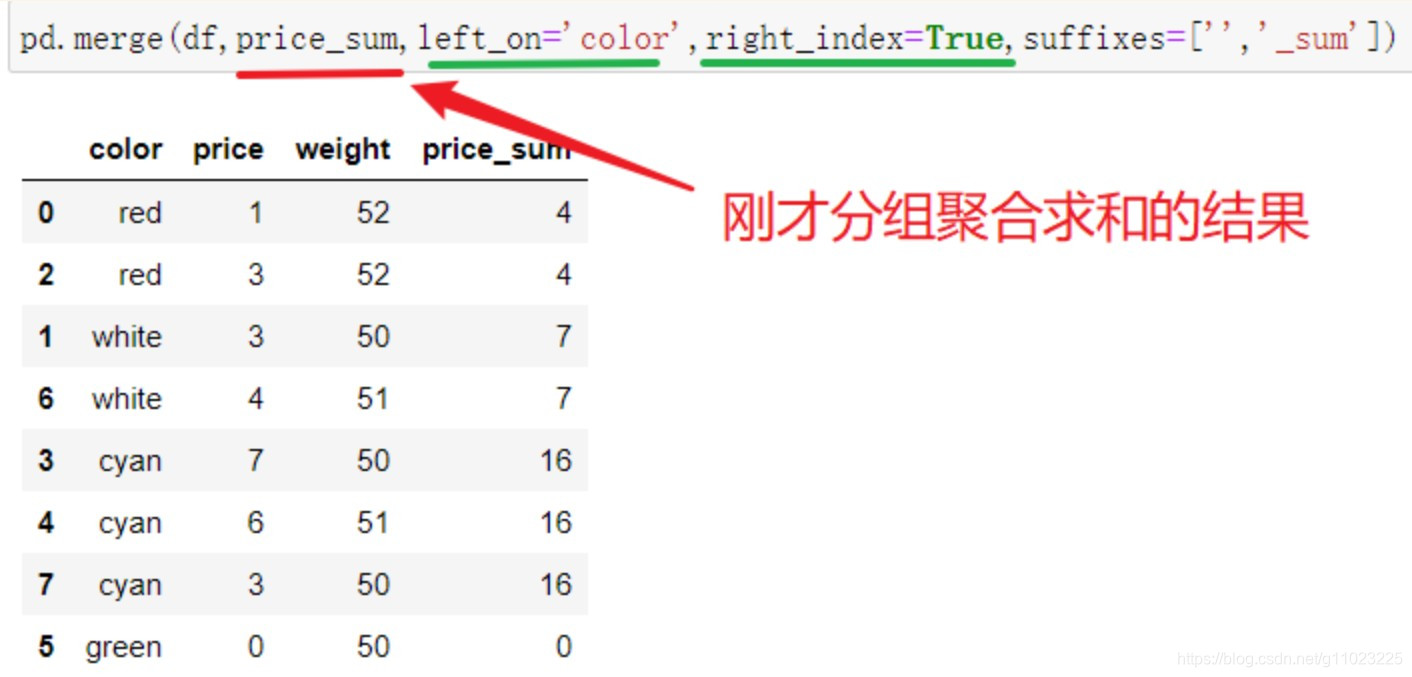
将上面聚合得到的数据和之前的数据,使用pd.merge()方法合并一起。合并操作会合并列,指定原数据合并的列名为color,指定聚合后的数据的合并列为其行索引。为了区分聚合后的价格和之前的价格,可以指定suffixes参数。
二、pandas数据绘图函数
pandas数据使用matplotlib.pyplot进行绘图,所以绘图前需要先导入该模块。
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import matplotlib.pyplot as plt
2.1.线性图
线形图反映的是趋势
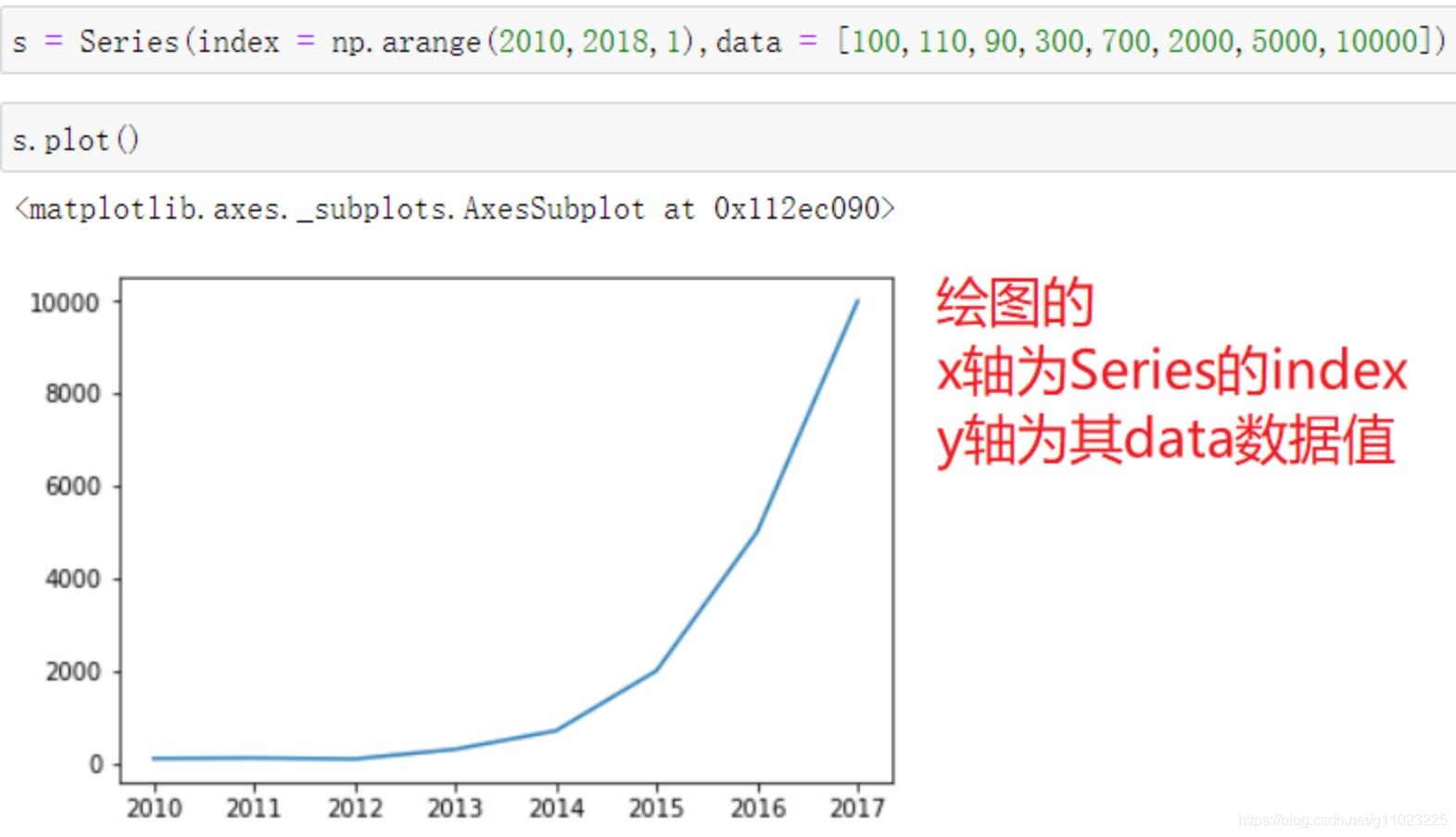
简单的Series图表示例,其以index作为x轴数据, values作为y轴数据
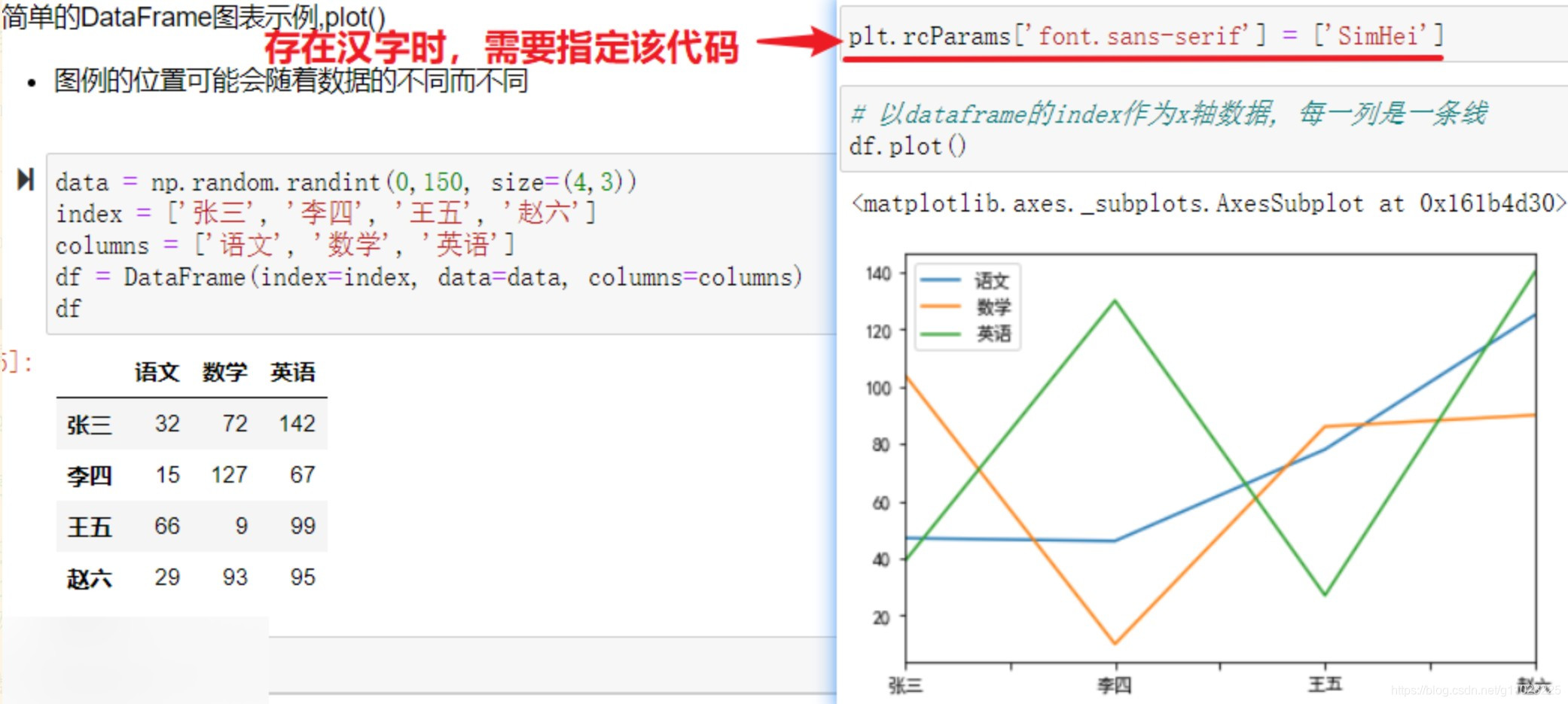
对dataframe数据进行画图时,其会以dataframe的index作为x轴数据, 每一列是一条线。
如果行列中有中文数据时,需要加上下面的代码:
# 解决中文字体下负号无法正常显示的问题
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.sans-serif'] = ['SimHei']
2.2.柱状图
画柱状图时,需要给定.plot()中的参数kind='bar'。
柱状图一般用来比较大小。
画柱图时,DataFrame数据的行索引值会成为图的x坐标,每一列都会是一个系列,列名为系列的名称,列对应的值为柱的高度。
当给定
.plot()中的参数kind='barh'时,柱图会变成水平展示。
2.3.直方图
画直方图时,需要给定.plot()中的参数kind='hist'。
直方图一般用来表示数据的分布情况
一般直方图经常和kde(Kernel Density Estimation核密度估计)一起使用,也即是画直方图的时候同时画kde图(.plot(kind='kde')),使用该函数,需要安装scipy模块。
上面的图中,给出了Series数据的分布情况,其中设置bins的值可以改变直方图的柱条的间隙、宽度、高度。如果bins设置不太合理,可以加上kde图来显示数据分布。加入density=True之后,y轴的值变成了概率/组距的结果。
使用np.histogram(s, bins=5, density=True)代码可以算出数据画成直方图之后的柱高和组距,比如对于上图中的数据s,其返回结果如下:
(array([0.21428571, 0.07142857, 0.21428571, 0.14285714, 0.07142857]),
array([1. , 2.4, 3.8, 5.2, 6.6, 8. ]))
其中第二个array为上图中柱的两边的位置,第一个array为上图中的柱高。
柱高的计算如下:
首先在1-2.4之间数据s中有1,1,2,数据总个数为10,所以该组的概率为0.3,由于该组对应的柱两边的坐标为1和2.4,所以组距为2.4-1=1.4。所以可以求出该柱的高度为0.3/1.4=0.2142857142857143,即为第一个array中第一个数据值。其他的柱高可以用同样的方法计算。
下面这个示例为绘制一个由两个不同的正态分布组成的的双峰分布:
通过上面的图可以看出,两个正态分布的数据的范围,其中的核密度曲线也和直方图的分布一致。
2.4.散布图(散点图)
画散点图时,需要给定.plot()中的参数kind='scatter',给明散点图横综坐标轴对应的数据列索引名。
散布图 散布图是观察两个一维数据数列之间的关系的有效方法,DataFrame对象可用。
散点图用于研究两个一维数据之间的关系。
数据为每一列都是标准正态分布的DataFrame数据
对于上面的数据,可以创建散点图矩阵,获取数据中多列之间的关系,使用函数:pd.plotting.scatter_matrix(),
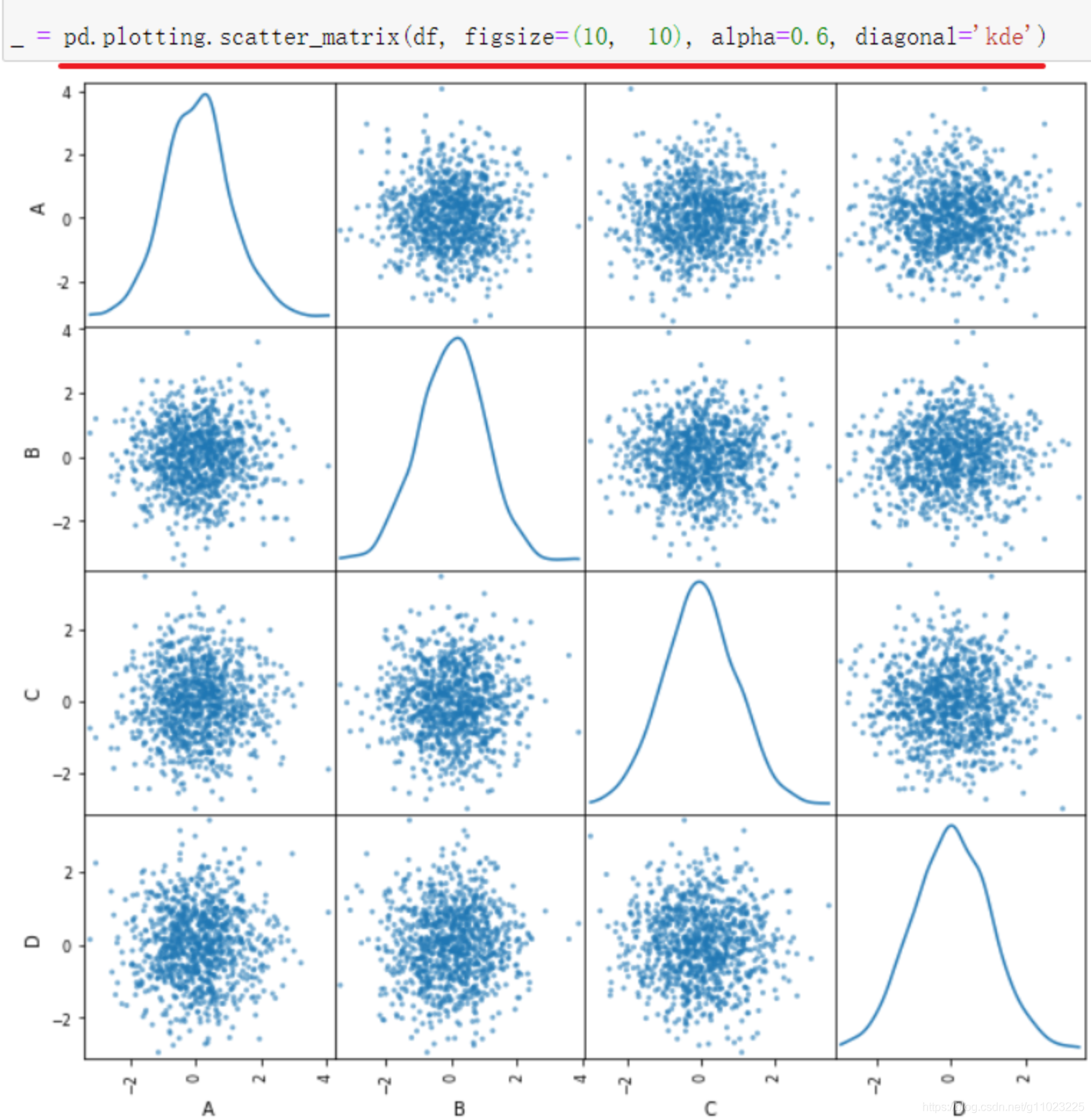
散点图可以看出数据之间的关系,比如下面的示例:
上图中,首先使用np.linspace(0, 2*np.pi, 100)代码创建了长度为0-2pi、分隔100份的数值,类型为numpy.ndarray,然后使用该数据执行sin操作,获取另一份numpy.ndarray数据,最后指定画图的横综轴进行画图,最后可以看出两分数据之间的关系为正弦关系。














 2141
2141











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









