









BP后向传播算法
前言
昨天看到了一篇关于BP后向传播的论文,想着把这方面的知识彻底理解一下,本文将基于该论文和基本的BP算法。解释其基本概念和权值调整的运算过程。
一、BP神经网络的基本原理
BP(Back Propagation)网络是1986年由Rinehart和McClelland为首的科学家小组提出,是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一。BP网络能学习和存贮大量的输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。它的学习规则是使用最速下降法(梯度下降法),通过反向传播来不断调整网络的权值和阈值,使网络的误差平方和最小。BP神经网络模型拓扑结构包括输入层(input)、隐层(hide layer)和输出层(output layer)(如下图所示)。
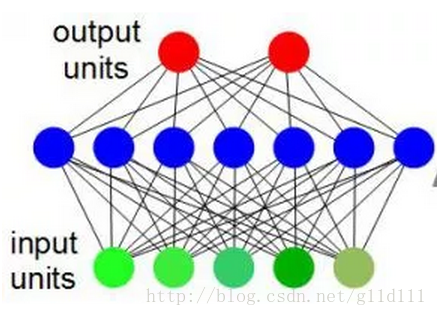
上图中,绿色单元为输入单元(input unit),蓝色单元为隐藏层单元(hidden unit),红色单元为输出单元(output unit)。
二、BP神经元与前向传播算法简介
- 神经元
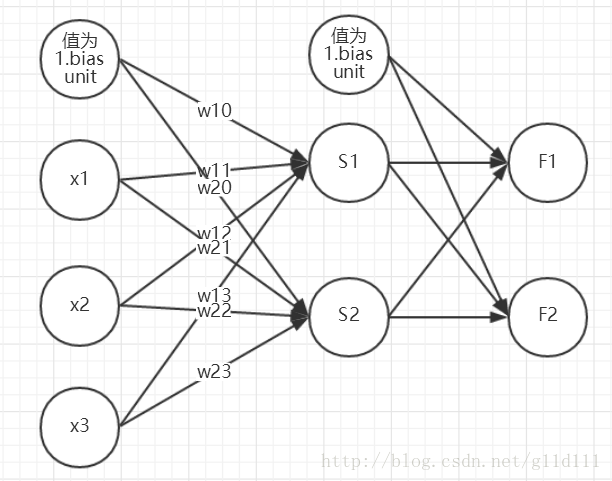
假设我们的训练集只有一个实例 (x(1),y(1)) ,我们的神经网络是一个三层的神经网络,即隐藏层只有1层。
以中间层神经元 Sj ,(j=1,2)为例,它只模仿了生物神经元所具有的三个最基本也是最重要的功能:加权、求和与转移。其中 x1、x2、x3 分别代表来自输入层(Input Layer)神经元1、2、3的输入; wj1、wj2、wj3 则分别表示神经元1、2、3与第j个神经元的连接强度,即权值; wj0 为阈值; f(⋅) 为传递函数;yj为第j个神经元的输出。
第1个神经元的净输入值 S1 为:
Sj=∑i=13wjixi+wj0=WjX
其中, wj0 是偏置单元 x0 对应的权值, x0 为1。
用上图的 S1 为例, S1=w11x1+w12x2+w13x3+w10x0
净输入
Sj
通过传递函数(Transfer Function)f (·)后,便得到第j个神经元的输出
yj
:
式中f(·)是单调上升函数,而且必须是有界函数,因为细胞传递的信号不可能无限增加,必有一最大值。
- 前向传播算法步骤
a(1)=x
z(2)=θ(1)a(1)
a(2)=f(θ(1)a(1))(加入bias unit)
z(3)=θ(2)a(2)
a(3)=Fθ(x)=f(θ(2)a(2))(加入bias unit)
a(3) 为预测结果。
三、反向传播
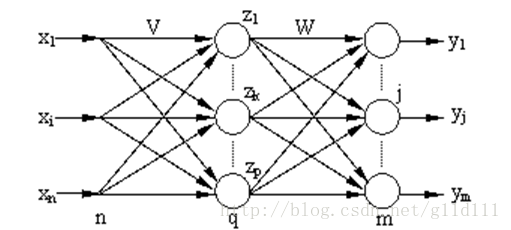
设 BP网络的输入层有n个节点,隐层有q个节点,输出层有m个节点,输入层与隐层之间的权值为 vki ,隐层与输出层之间的权值为 wjk ,如下图所示。隐层的传递函数为f1(·),输出层的传递函数为f2(·)。其中i= 1,2,3,…, n;k = 1,2,3,…,q;j=1,2,3,…,m。
3.1 定义误差函数
输入P个学习样本,用
x1,x2,...,xp
来表示。第p个样本输入到网络后得到输出
ypj
(j=1,2,…m)。采用平方型误差函数,于是得到第p个样本的误差
Ep
:
式中: tpj 为期望输出。
对于全部的P个样本,全局误差为:
3.2 输出层权值的变化
采用累计误差BP算法调整
wjk
,使全局误差E变小,运用梯度下降法:
式中:
α
—学习率
定义误差信号为:
Sj 为前向传播中的 z(3) 的第j个元素。 yj 为前向传播中 a(3) 的第j个元素
其中第一项:
第二项:
是输出层传递函数的偏微分。
于是:
由chain rule易得:
于是 输出层各神经元的权值调整公式为:
3.3 隐藏层权值的变化
定义误差信号为:
Sk
为前向传播中的
z(2)
的第k个元素。
zk
为前向传播中
a(2)
的第k个元素。
其中第一项:
依chain rule有:
第二项:
是隐层传递函数的偏微分。
于是 δzk 容易求得。
又由chain rule得:
从而得到 隐层各神经元的权值调整公式为:
四、BP算法的改进
BP算法理论具有依据可靠、推导过程严谨、精度较高、通用性较好等优点,但标准BP算法存在以下缺点:收敛速度缓慢;容易陷入局部极小值;难以确定隐层数和隐层节点个数。在实际应用中,BP算法很难胜任,因此出现了很多改进算法。
1) 利用动量法改进BP算法
标准BP算法实质上是一种简单的最速下降静态寻优方法,在修正W(K)时,只按照第K步的负梯度方向进行修正,而没有考虑到以前积累的经验,即以前时刻的梯度方向,从而常常使学习过程发生振荡,收敛缓慢。动量法权值调整算法的具体做法是:将上一次权值调整量的一部分迭加到按本次误差计算所得的权值调整量上,作为本次的实际权值调整量,即:
其中: β 为动量系数,通常大于0小于0.9; α —学习率,范围在0.001~10之间。这种方法所加的动量因子实际上相当于 阻尼项,它减小了学习过程中的振荡趋势,从而改善了收敛性。动量法降低了网络对于误差曲面局部细节的敏感性,有效的抑制了网络陷入局部极小。
2) 自适应调整学习速率
标准BP算法收敛速度缓慢的一个重要原因是学习率选择不当,学习率选得太小,收敛太慢;学习率选得太大,则有可能修正过头,导致振荡甚至发散。
调整的基本指导思想是:在学习收敛的情况下,增大
α
,以缩短学习时间;当
α
偏大致使不能收敛时,要及时减小它的值,直到收敛为止。
3) 动量-自适应学习速率调整算法
采用动量法时,BP算法可以找到更优的解;采用自适应学习速率法时,BP算法可以缩短训练时间。将以上两种方法结合起来,就得到动量-自适应学习速率调整算法。
4) L-M学习规则
L-M(Levenberg-Marquardt)算法比前述几种使用梯度下降法的BP算法要快得多,但对于复杂问题,这种方法需要相当大的存储空间。L-M(Levenberg-Marquardt)优化方法的权值调整率选为:
其中:e—误差向量;J—网络误差对权值导数的雅可比(Jacobian)矩阵;μ—标量,当 μ很大时上式接近于梯度法,当 μ很小时上式变成了Gauss-Newton法,在这种方法中,μ也是自适应调整的。
ps:
虽然牛顿法效果好,但是由于所使用的海森矩阵所需要的运算量太大,实际上用的还是比较少的。

















 294
294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









