









最近写spark streaming程序,对于一个非计算机专业出身的渣渣,对java真的累觉不爱。虽然,用scala进行开发也很方便,但是为了帮助只会python,或者说习惯用python做后续处理任务的同学来说,我打算做一个基于python的spark streaming/SQL等教程。这篇文章是将官方文档翻译成中文,并加上测试的例子。
概要 (Overview)
Spark Streaming是对于Spark Core API的扩展,从而支持对于实时数据流的高扩展性,高吞吐量和容错性流处理。数据可以由多个源取得,例如:Kafka,Flume,Twitter,ZeroMQ,Kinesis或者TCP接口,同时可以使用由如map,reduce,join和window这样的高层次的复杂算法进行处理。最终,处理过的数据可以被推送到文件系统,数据库和实时面板。实际上,我们可以在数据流上直接应用Spark的机器学习算法和图处理算法

其内部的运行方式为:Spark Streaming接收到实时数据流同时将其划分为batches,这些数据的分批将会被Spark的引擎所处理从而生成同样按批次形式的最终流。

Spark Streaming提供了被称为离散化流(discretized stream)或者DStream的高层次抽象,这个高层次抽象用于表示连续的数据流。
创建DStream的两种方式:
1. 由Kafka,Flume和Kinesis等取得的数据作为输入数据流。
2. 在其他DStream进行的transformation操作而得到。
本质上:a DStream is represented as a sequence of RDDs.
(一个DStream 由一系列的RDD组成)
Spark Streaming程序可以用java、scala和python开发(从spark1.2版本以后支持)。这里我们只讲用python开发的情况。
注意:少量的API在Python中要么是不可用的,要么是和其他有差异的。在本文中,这些点将会被高亮显示。
快速开始 (A Quick Example)
在深入了解如何编写你自己的Spark Streaming程序之前,让我们先迅速浏览下基本的Spark Streaming程序是什么样的。假设我们想统计文本数据中单词个数(数据来自于监听一个TCP接口的数据服务器)。你只需要这样做:
引入StreamingContext,这个是所有流功能函数的主要访问点,我们使用两个执行线程和1s的批次间隔来创建本地的StreamingContext:
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
# 创建一个本地的StreamingContext,两个工作线程,批次间间隔1s。
sc = SparkContext("local[2]", "NetworkWordCount")
ssc = StreamingContext(sc, 1) # 1表示1s
# 使用这个Context,就可以创建一个DStream来展现来自于TCP源的流形数据了,指定 主机名 和 相应的端口即可。
# 创建一个和 hostname:port相连接的DStream,形如 local:9999
lines = ssc.socketTextStream("localhost", 9999)
# 这个行的DStream表示来自数据服务器的数据流。DStream中的每个记录就是text中的一行。下来利用空格" " 将所有行分割为单词的组合
words = lines.flapMap(lambda line: line.split(" "))
# flapMap 是一个一对多映射的DStream操作,其从原DStream的每一条记录里产生相应的多个新记录。这样,每一行被分割成为多个单词,同时分割后的单词流以words DStream的形式展现。下来,将这些单词进行计数:
# 在各批次中计数单词
pairs = words.map(lambda word: (word, 1))
wordCounts = pairs.reduceByKey(lambda x, y: x + y)
# 将在这个DStream中产生的每个RDD的前十个元素打印到终端
# 注意,pprint()在java或scala中对应的函数是print().默认打印到控制台当前DStream的前10个数据。
wordCounts.pprint() words 这个DStream 进一步被映射成(一对一的转换)(word,1)对的DStream形式,这个“对”形式的DStream将会被reduced(一个Spark操作)以取得数据各个批次中单词的统计。最后,wordCounts.pprint()打印处每一秒所获得的少量计数值。
注意:这么多行代码被执行后,Spark Streaming设置了若开始运行将要进行的运算,但是并没有开始真正意义上的处理。在所有的转换都部署完毕后,我们需要调用下面两个操作来真正启动处理:
ssc.start() # 开始计算
ssc.awaitTermination() # 等待计算终止官方案例(Python3版本):
"""
Counts words in UTF8 encoded, '\n' delimited text received from the network every second.
Usage: network_wordcount.py <hostname> <port>
<hostname> and <port> describe the TCP server that Spark Streaming would connect to receive data.
To run this on your local machine, you need to first run a Netcat server
`$ nc -lk 9999`
and then run the example
`$ bin/spark-submit examples/src/main/python/streaming/network_wordcount.py localhost 9999`
"""
from __future__ import print_function
import sys
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
if __name__ == "__main__":
if len(sys.argv) != 3:
print("Usage: network_wordcount.py <hostname> <port>", file=sys.stderr)
exit(-1)
sc = SparkContext(appName="PythonStreamingNetworkWordCount")
ssc = StreamingContext(sc, 1)
lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))
counts = lines.flatMap(lambda line: line.split(" "))\
.map(lambda word: (word, 1))\
.reduceByKey(lambda a, b: a+b)
counts.pprint()
ssc.start()
ssc.awaitTermination()如果你已经下载并编译了Spark,就可以按如下讲解来运行这个例子。首先你需要运行Netcat(大多数类Unix系统都有的工具)作为数据服务器:
$ nc -lk 9999接下来,在不同的终端,可以使用如下方式启动历程:
$ ./bin/spark-submit examples/src/main/python/streaming/network_wordcount.py localhost 9999运行netcat终端上的任何键入的数据将会被计算并打印到屏幕上。
# 终端 1:
# Running Netcat(运行Netcat数据服务器)
$ nc -lk 9999
hello world
...# 终端 2: RUNNING network_wordcount.py(运行network_wordcount.py程序)
$ ./bin/spark-submit examples/src/main/python/streaming/network_wordcount.py localhost 9999
...
-------------------------------------------
Time: 2014-10-14 15:25:21
-------------------------------------------
(hello,1)
(world,1)
...基本概念 (Basic Concepts)
接下来,我们抛开上面的简单例子,阐述SS的基本知识。
Linking
和Spark相似,Spark Streaming在Maven中心可用。为了编写你自己的Spark Streaming程序,你需要将下面的依赖(dependency)加进你的SBT或者Maven项目。
# Maven
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.10</artifactId>
<version>1.6.0</version>
</dependency>
# SBT
libraryDependencies += "org.apache.spark" % "spark-streaming_2.10" % "1.6.0"为了从像Kafka,Flume,和Kinesis这些没有出现在Spark Streaming核心API的源来获取数据,你需要将相应的artifact: spark-streaming-xyz_2.10 加进依赖中。下面列举一些常见的:
| Source | Artifact |
|---|---|
| Kafka | spark-streaming-kafka_2.10 |
| Flume | spark-streaming-flume_2.10 |
| Kinesis | spark-streaming-kinesis-asl_2.10 [Amazon Software License] |
| spark-streaming-twitter_2.10 | |
| ZeroMQ | spark-streaming-zeromq_2.10 |
| MQTT | spark-streaming-mqtt_2.10 |
对于最新的列表,请参阅 Maven仓库 以获得完整的支持源和artifacts。
StreamingContext初始化 (Initializing StreamingContext)
为初始化一个Spark Streaming程序,需要创建一个StreaingContext对象,此对象为所有Spark Streaming功能函数的主入口。
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
# appName: 在集群UI上显示的应用标签。
# master: 程序调度资源管理器。常见的有 Mesos, YARN-Client,YARN-Cluster 或者以"loacl[*]"的形式运行于本地。
sc = SparkContext(master, appName)
ssc = StreamingContext(sc, 1)在实际使用中,当程序运行在集群上时,你或许不希望在程序中将 master 写死(hardcode),而是使用 spark-submit来发射应用并在这里接收。但是,为了本地测试和单元测试,你可以写入”local[*]”来在进程中启动Spark Streaming(监测本地系统中核(core)的数量)。
批处理间隔(Batch Interval)必须基于可用的集群资源和应用程序的延迟要求来设置,具体可见Performance-Tuning
在定义了一个context后,你需要做下面的事情:
- 通过创建DStream来定义输入源
- 通过对DStream使用转换和输出操作来定义流计算
- 使用
streamingContext.start()来接收并处理数据 - 使用
streamingContext.awaitTermination()等待处理的停止(手动或者因为任何出错). - 处理进程可以使用
streamingContext.step()来手动停止。
注意要点:
- 一旦一个Context被启动了,新的流计算任务就不能建立或者加入这个环境中。
- 一旦一个context停止了,就不能再次启动了。
- 一个JVM同时只能有一个StreamingContext运行。
- stop()停止StreamingContext同时也会停止SparkContext。为了只停止StreamingContext,将stopSparkContext参数置为false。
- 只要上一个StreamingConetxt在下一个StreamingContext创建前停止了,那么一个SparkContext就可以用来创建多个StreamingContext。
离散数据流 (DStreams)
离散数据流或者DStream是由Spark Streaming提供的基本抽象。它表现为连续的数据流,这个输入数据流可以来自于源,也可以来自于转换输入流产生的已处理数据流。内部而言,一个DStream以一系列连续的RDDs所展现,这些RDD在Spark中是不可变的,分布式数据集的抽象(详见Spark编程指南)。一个DStream中的每个RDD都包含来自一定间隔的数据,如下图所示:

在DStream上使用的任何操作都会转换为针对底层RDD的操作。例如:之前那个将行的流(lines DStream)转变为词流(words DStream)的例子中,flatMap操作应用于行DStream的每个RDD上 从而产生words DStream的RDD。如下图:

这些底层的RDD转换是通过Spark引擎计算的。DStream操作隐藏了大多数细节,同时为了方便为开发者,提供了高层次的API。这里的一些操作会在下文中详述。
离散数据流输入与接收器(Input DStreams and Receivers)
输入数据流是源自流式数据源的数据。在之前的WordCount例子中,lines 是从netcat服务器读取的DStream。注意:除了文件流数据,每个DStream都有一个对应的Receiver对象(scala文档),该对象负责从数据源获取数据,并将数据存在spark内存中亟待后续计算。
Spark Streaming提供了两种内置的数据流源(streaming sources)。
- 基本数据源(Basic sources)
StreamingContext API直接可用的数据源。例如:文件系统,套接字连接,Akka框架(实现Actor模型的scala/java平台,本博客有Akka相关文章,需要的同学请查阅。)。 - 高级数据源(Advanced sources)
Kafka,Flume,Kinesis,Twitter等等这样的源可以通过额外的工具类(utility classes)来使用。这要求链接到额外的依赖(如linking节所讲)。
这两种类型的源我们都会涉及到一些。
注意,如果你想在自己的流应用中并行接收多数据流,你可以创建多个输入DStream(这在性能优化章节会有所涉及)。这会创建创建多个接收器以同时接收多数据流。但是要注意,Spark的worker/executor 是一个跨度很长的任务(long-running task),因此其至少占据一个核(core)从而分配给Spark Streaming任务。所以,需要给Spark Streaming应用分配足够多的核(若是本地模式就是足够多的线程)从而保证处理接收到的数据并运行接收器。
要点:
- 当以本地模式运行一个Spark Streaming程序时,不要使用”local”或者”local[1]”作为master URL。这些都意味着仅仅只有一个线程被用于在本地运行任务。如果你基于一个接收器(如套接字,Kafka,Flume等等)来运行输入DStream,那么仅有一个单线程来跑接收器,而没有余下线程来处理接收到的数据。因此,当运行于本地时,必须使用”local[n]”作为master URL,其中n应大于你要跑的接收器的数目(参阅Spark Properties 来学习如何设置master)。
- 当在集群上跑程序的时候,分配给Spark Streaming应用的核的数量一定要多于接收器的数量。否则系统将只能接收数据,但不能进行处理。
基本数据源(Basic Sources):
我们已经通过一个简单的例子了解了如何从文本数据来创建一个DStream(文本数据来自于TCP套接字的连接)。除了套接字,StreamingContext API也提供了以文件和Akka actors作为输入源来创建DStream的途径。
- 文件流(File Streams)
从HDFS API提供的任何文件系统文件(如HDFS、S3、NFS等)中读取的数据,可按如下方式创建DStream:
streamingContext.textFileStream(dataDirectory)
Spark Streaming将监听目录”dataDirectory”,同时处理任何新增到此目录中的文件(不包括此目录下嵌套目录中的文件)。
需要注意的是:
① 文件中的数据格式必须一致
② 文件必须以原子方式(atomically)移动或者重命名进入目录的方式来创建。
③ 一旦移动到这个目录中(本例为”dataDirectory”),文件就不能再改动了。所以即使继续加入文件内容,新加入数据也不会被读取。
也就是说,如果你向目录”increase_data”加入一个test1.txt的文件,文件内容为

在Streaming 任务将数据读取完毕之后,如果有另外的程序对这个test1.txt继续添加形如1495697400||657526482||1||0.490000的数据,那么Streaming 任务不会处理这些新增加的数据。
Note:fileStream方法Python中不支持,目前仅textFileStream是可用的。
① 基于Custom Actors的流:
使用streamingContext.actorStream(actorProps,actor-name)可以用接收自Akka actors的数据流来创建DStreams。详细内容请见 Custom Receiver Guide
(ps:此方法不支持python)
②
RDD队列作为流:使用测试数据测试Spark Streaming应用,也可以使用streamingContext.queueStream(queueOfRdds)来基于一个RDD的队列创建一个DStream。每个在队列中的RDD都会在DStream中被当做一批数据(batch),同时以流方式进行处理。
更多细则关于来自sockets,files,和actors的流,请看相应的API文档。Python:StreamingContext。
高级数据源(Advanced Sources):
Note:在Spark 1.6.0以上版本, Kafka,Kinesis,Flume和MQTT提供Python API。
这一类源需要非Spark库的外部接口,其中一些需要复杂的依赖(如Kafka和Flume)。因此,为了尽可能减少版本之间的依赖冲突问题,从这些源中创建DStreams的功能函数被移至单独的库从而可以在需要的时候显式链接。例如,若你想使用来自于Twitter的推特流数据来创建一个DStream,你需要做如下的工作:
1. 链接:将 spark-streaming-twitter_2.10加入SBT/Maven项目依赖中。
2. 编程:导入TwitterUtils类并用TwitterUtils.createStreams创建一个DStream
3. 部署:生成一个包含所有依赖的超级JAR(含有依赖 spark-streaming-twitter_2.10和其所需依赖)并部署应用。在部署(Deploying section)那章细讲。
# scala代码
import org.apache.spark.streaming.twitter.*
TwitterUtils.createStream(jssc);注意:这些高级源不能在Spark shell上使用,因此基于这些源的应用程序不能在shell上测试。如果你非要在Spark shell上使用他们,那你需要去下载相应的Maven artifact的JAR以及其依赖并将其添加到路径中。
其中一些高级源列举如下:
Kafka:Spark Streaming 1.6.0和Kafka的 0.8.2.1兼容。见Kafka集成
Flume:Spark Streaming 1.6.0 和 Flume的 1.6.0兼容。见Flume集成
自定义数据源(Custom Sources):
注意:不支持python
离散数据流的“转换”算子(Transformations on DStreams)
和RDD类似,使用转换算子可以修改从输入DStream获取的数据。DStreams支持许多在Spark RDD上的转换算子。其中一些常用的如下:
map(func):将源DStream中的每个元素通过一个函数func从而得到新的DStreams。
flatMap(func):和map类似,但是每个输入的项可以被映射为0或更多项。
filter(func):选择源DStream中函数func判为true的记录作为新DStreams
因为DStream的transformation与一些普通RDD的transformation算子大同小异,所以可以参见pyspark rdd
“转换”操作(Transform Operation)
转换操作(transform),连同其参数,诸如transformWith
允许在DStream上使用任意的RDD-RDD函数。其可以使用RDD的transformation算子而不仅仅局限于DStream的transformation算子。
例如,将数据流中每个批次数据和其他数据集接合的功能在DStream API不支持。然而,你可以用 transform轻易实现。这提供了诸多可能性。例如,你可以通过结合预先计算的垃圾信息来做实时的数据清理( one can do real-time data cleaning by joining the input data stream with precomputed spam information (maybe generated with Spark as well) and then filtering based on it.)
# 包含垃圾信息的RDD
spamInfoRDD = sc.pickleFile(...)
# 通过将数据流结合垃圾信息来做数据清理
cleandDStream = wordCounts.transform(lambda rdd: rdd.join(spamInfoRDD).filter(...))注意: 在每个批次间隔(batch intervals)中提供的函数都会被调用。这允许你做随时间变化的RDD操作,这也意味着RDD操作,分区个数,广播变量可以随着批次而改变。
“窗口”操作(Window Operation)
Spark Streaming也提供窗口化计算(非常重要),允许用户将“转换”算子用于滑动窗口数据。下图说明了这类滑动窗口:

如上图所示,随着窗口沿着DStream滑动,落到窗口中的源RDD会被合并,并进行操作从而产生属于窗口DStream类型的RDD。如上图,操作作用在三个单位时间数据上同时每次滑动两个时间单位。这意味着任何窗口操作都需要指定两个参数。
这个例子中:
- 窗口长度: 窗口持续时间(图中是3)
- 滑动间隔: 窗操作执行的间隔(图中是2)
这个两个参数必须是源DStream中的batch interval的倍数(图中为1)
让我们用示例对窗口操作进行说明。
假设,你想拓展前例从而每隔十秒对持续30秒的数据生成word count。为做到这个,我们需要在持续30秒数据的(word,1)对DStream上应用reduceByKey。使用操作算子reduceByKeyAndWindow.
# Reduce last 30 seconds of data, every 10 seconds
windowedWordCounts = pairs.reduceByKeyAndWindow(lambda x, y: x + y, lambda x, y: x - y, 30, 10)下面是一般的窗口操作。所有的窗口操作都必须指定窗口长度和滑动间隔这两个参数
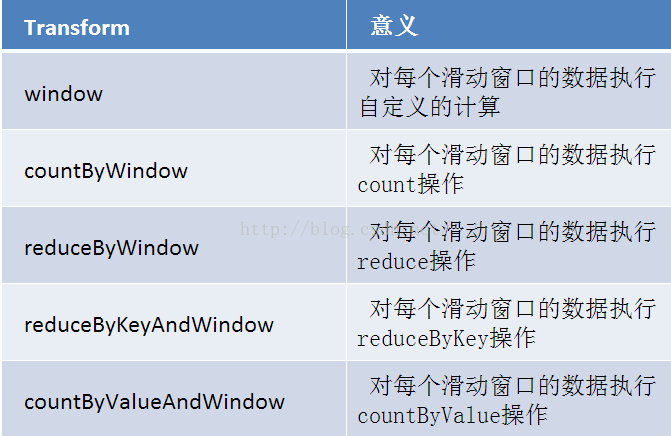
window(窗长,滑动间隔): 基于对DStream窗口化进行计算,返回一个新的DStream。
countByWindow(窗长,滑动间隔):返回一个滑动窗口中的元素个数。
reduceByWindow(自定义函数,窗长,滑动间隔):通过使用自定义函数整合滑动区间流元素来创建一个新的单元素流。
“连接”操作(Join Operation)
最后,值得一提的是:在Spark Streaming中执行不同数据类型的连接相当简单。
Stream-stream 连接
Streams可以很容易地与其他流连接。
stream1 = ...
stream2 = ...
joinedStream = stream1.join(stream2)此处,在每个时间间隔中,由stream1生成的RDD将于由stream2生成的RDD进行连接操作(join)。你也可以用leftOuterJoin, rightOuterJoin,fullOuterJoin等操作。除此之外,在数据流窗口(windows of the streams)中做连接非常有用,当然也很简单。
# 注意,这里没有指定slideInterval,默认为batch interval
windowedStream1 = stream1.window(20)
windowedStream2 = stream2.window(60)
joinedStream = windowedStream1.join(windowedStream2)完整的DStreams transformation列表在API文件中可见。对于Python API,详见DStream.















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









