






一、朴素贝叶斯算法原理
朴素贝叶斯(Naive Bayes)是一种基于贝叶斯定理的简单而强大的分类算法,尤其适用于文本分类问题,如垃圾邮件检测、情感分析等




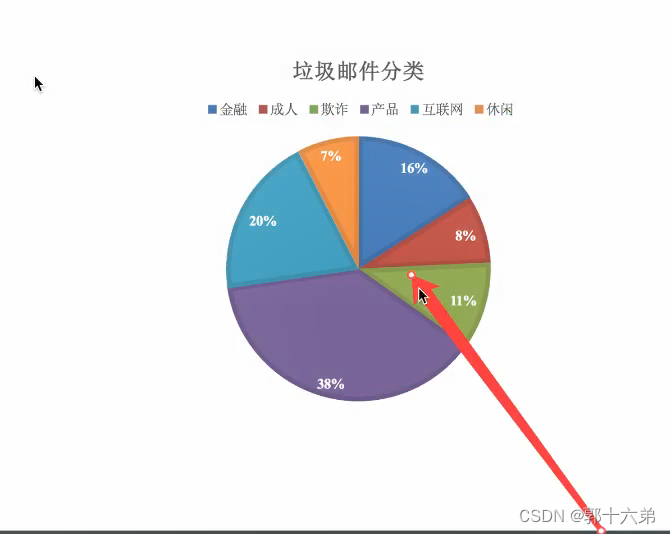
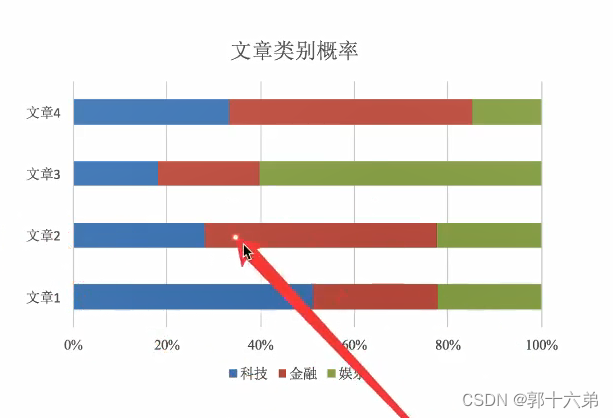

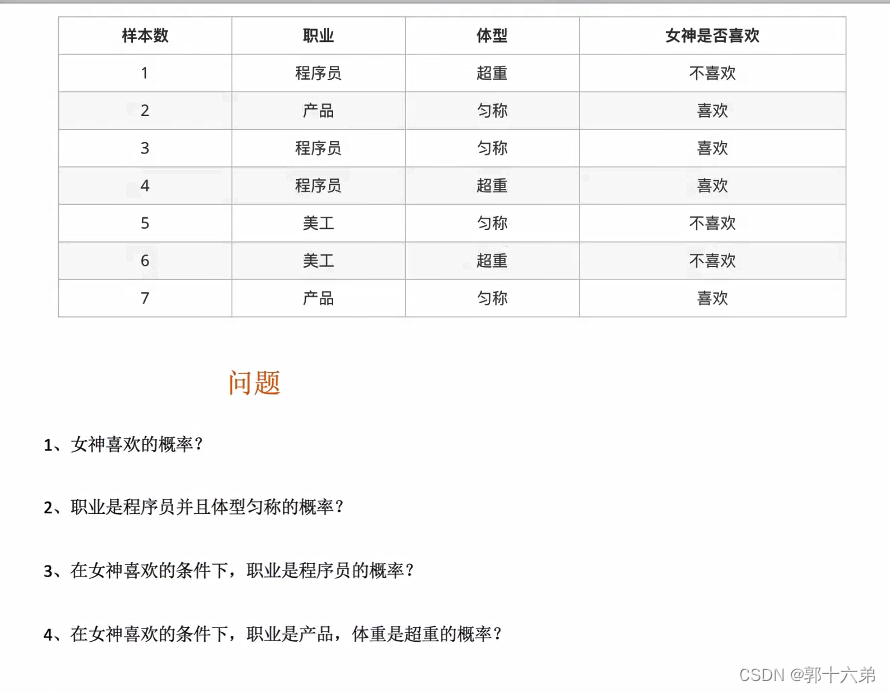

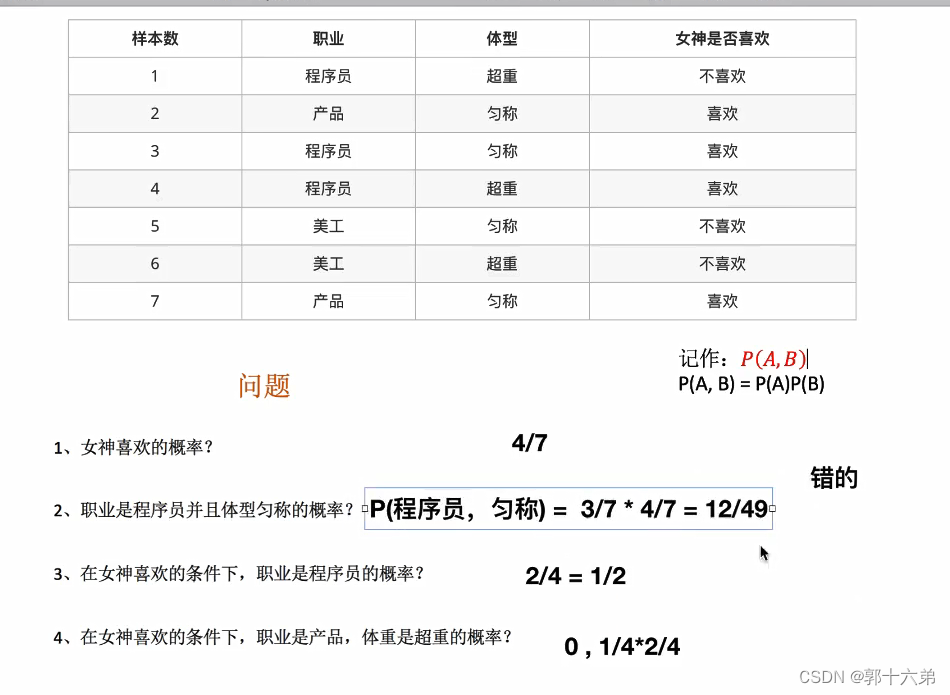
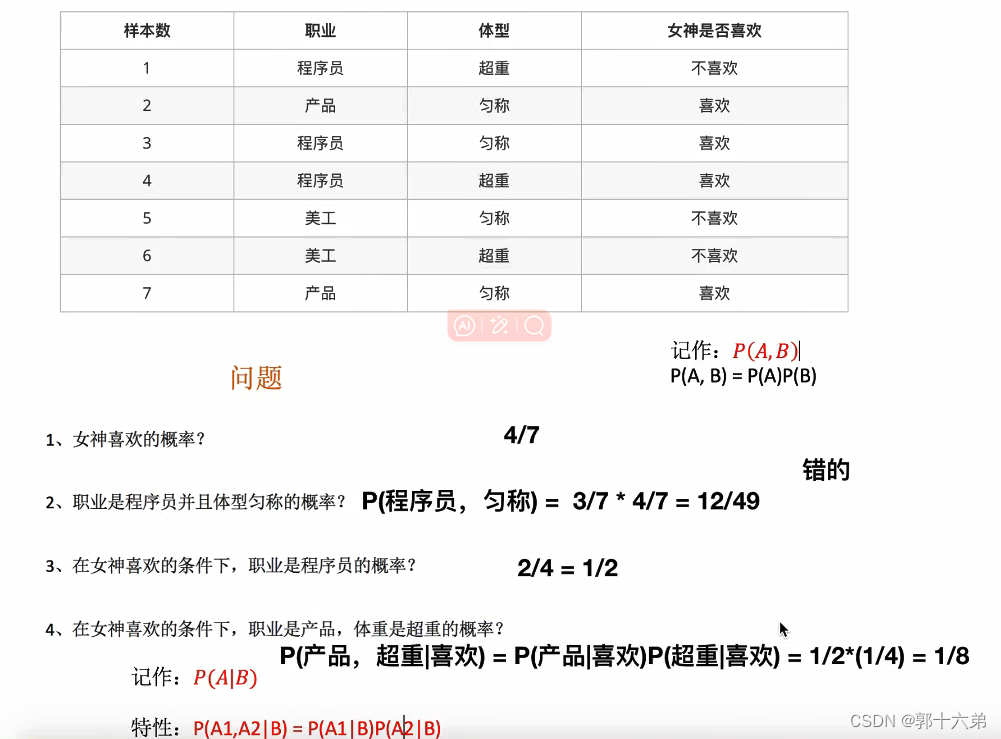



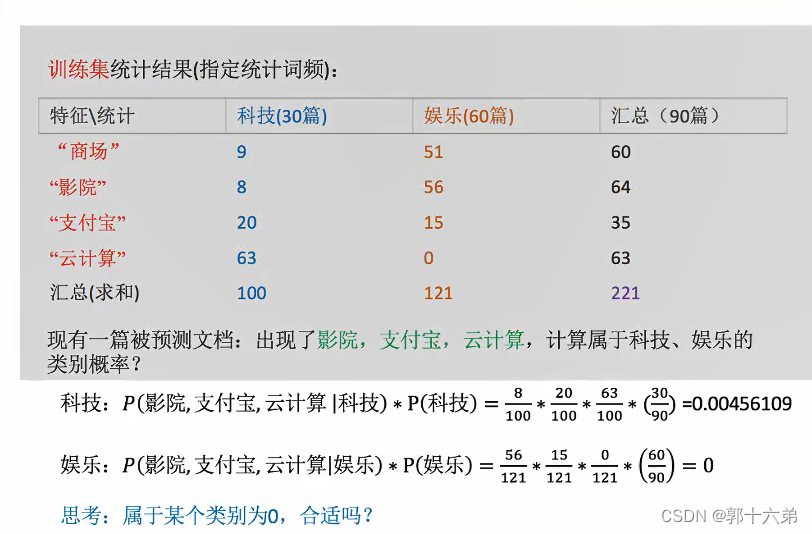
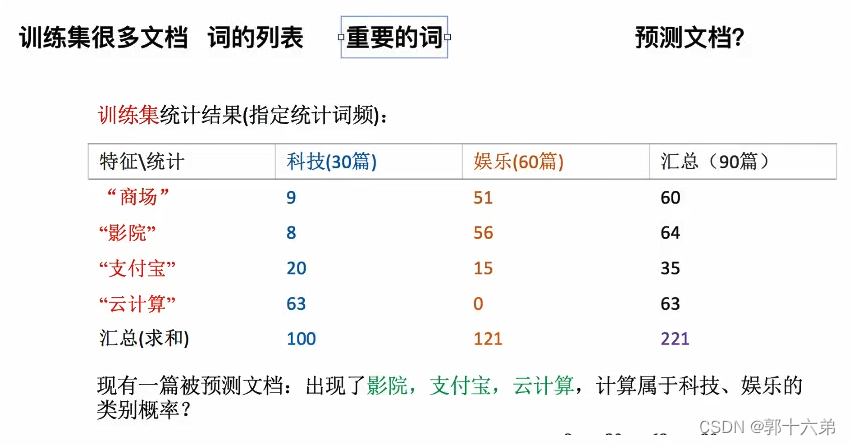
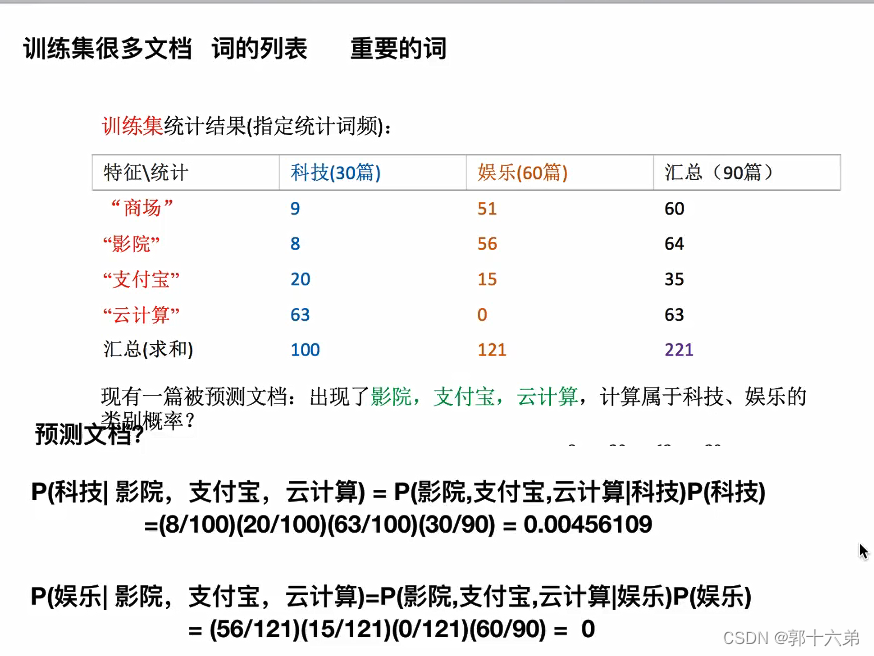
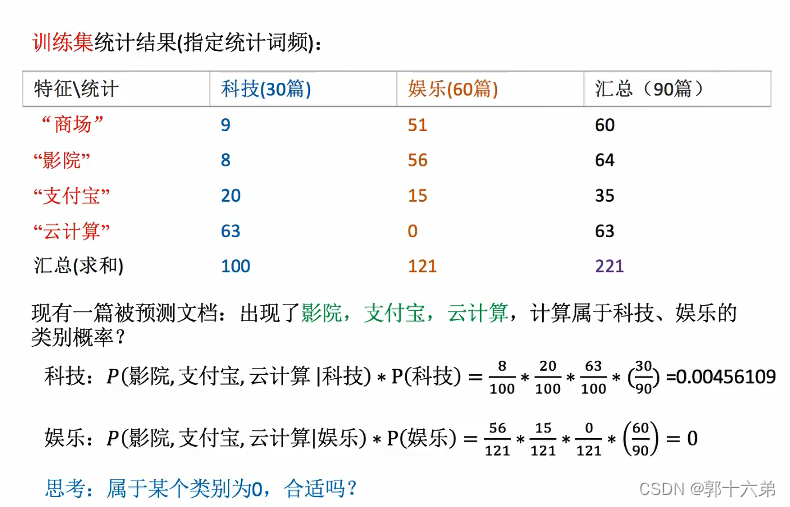




二、朴素贝叶斯算法对新闻进行分类案例


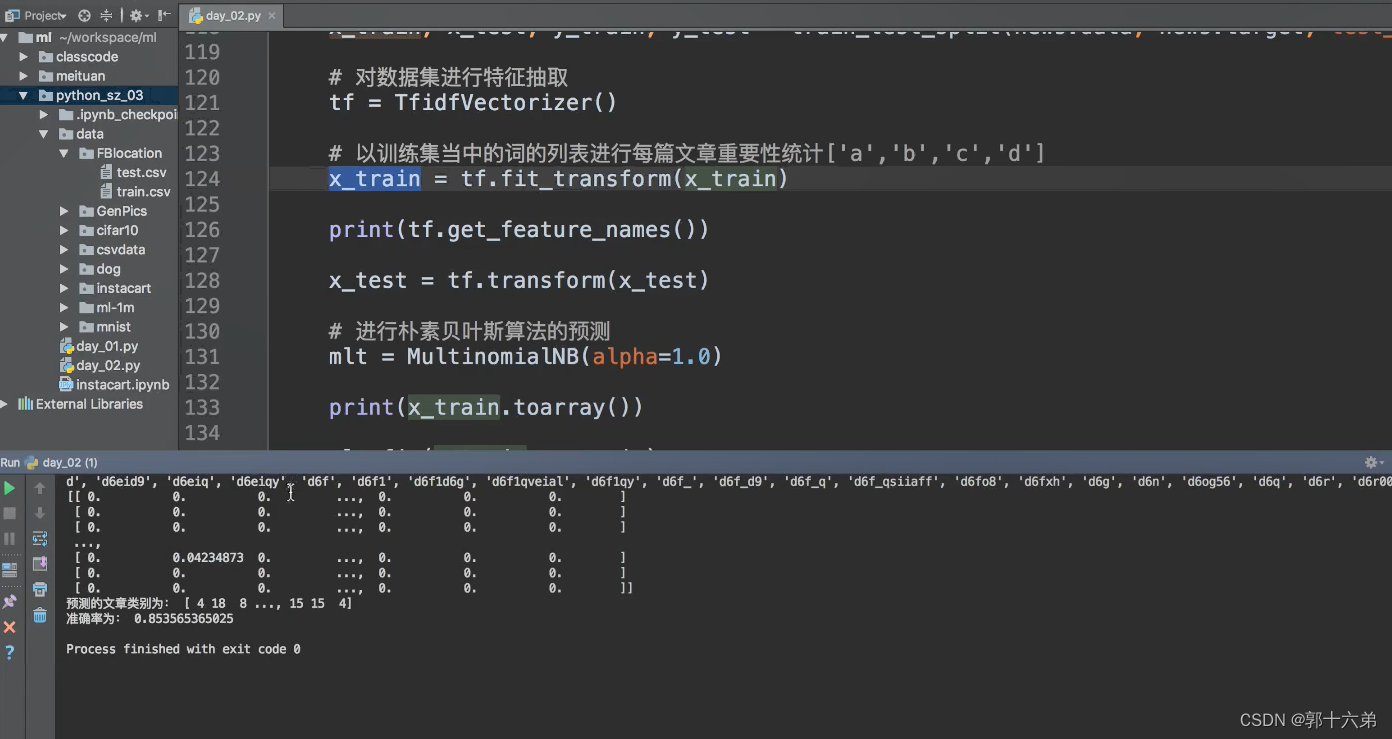
1. 数据准备
假设我们有一个新闻数据集,每篇新闻都有一个类别标签,比如“体育”、“科技”、“娱乐”等。我们可以使用一些开源数据集,比如Kaggle上的新闻分类数据集,或者自己收集数据。
新闻内容: "足球世界杯即将开幕,各国球队蓄势待发"
类别: "体育"
新闻内容: "最新智能手机发布,配备了先进的AI功能"
类别: "科技"
2. 特征提取
在文本分类任务中,常用的特征提取方法是词袋模型(Bag of Words)或TF-IDF(词频-逆文档频率)。
词袋模型
词袋模型将每篇文章表示为一个词频向量。例如,有一个词汇表 ["世界杯", "开幕", "球队", "智能手机", "发布", "AI功能"],每篇文章可以表示为:
"足球世界杯即将开幕,各国球队蓄势待发" -> [1, 1, 1, 0, 0, 0]
"最新智能手机发布,配备了先进的AI功能" -> [0, 0, 0, 1, 1, 1]
TF-IDF
TF-IDF考虑了词频和逆文档频率,能够降低常见词的影响,提高重要词的权重。
3. 训练模型
在Python中,我们可以使用scikit-learn库来实现朴素贝叶斯算法。以下是一个具体的代码示例:
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score, classification_report
# 假设我们有一个DataFrame,包含新闻内容和类别
data = {
'content': [
'足球世界杯即将开幕,各国球队蓄势待发',
'最新智能手机发布,配备了先进的AI功能',
'娱乐圈再爆丑闻,某明星涉嫌违法'
# 添加更多新闻数据
],
'category': [
'体育',
'科技',
'娱乐'
# 对应的类别
]
}
df = pd.DataFrame(data)
# 特征提取
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(df['content'])
y = df['category']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练朴素贝叶斯模型
model = MultinomialNB()
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')
print('Classification Report:')
print(classification_report(y_test, y_pred))
4. 分类预测
训练完模型后,我们可以使用它来对新新闻进行分类。例如:
new_news = ['某明星被曝与多名女子有不正当关系']
X_new = vectorizer.transform(new_news)
prediction = model.predict(X_new)
print(f'Predicted category: {prediction[0]}')
总结
通过上述步骤,我们可以使用朴素贝叶斯算法对新闻进行分类。这个过程包括数据准备、特征提取、训练模型和分类预测。朴素贝叶斯算法简单高效,尤其适合处理文本分类任务。使用Python的scikit-learn库可以方便地实现该算法,并且可以通过准确率和分类报告来评估模型的性能。
三、朴素贝叶斯算法总结


1. 优缺点
优点:
- 简单易懂:算法简单,易于实现。
- 计算效率高:训练和预测速度快,适合大规模数据。
- 处理缺失数据:对缺失数据不敏感。
- 多类别预测:可以直接进行多类别分类。
缺点:
- 特征独立假设:假设特征之间相互独立,这在实际应用中往往不成立。
- 数据稀疏问题:在特征空间高维度的情况下,某些组合可能在训练数据中没有出现,导致概率为零。
- 对数值型特征处理较差:适用于离散型特征,对于连续型特征需要做离散化处理。
2. 实现步骤
- 数据准备:收集并标注数据集。
- 特征提取:使用词袋模型(Bag of Words)、TF-IDF等方法将文本数据转换为特征向量。
- 训练模型:计算先验概率和条件概率,训练朴素贝叶斯分类器。
- 分类预测:对新样本进行预测,计算各类别的后验概率,选择最大者作为预测结果。
- 模型评估:使用准确率、混淆矩阵等指标评估模型性能。
3. 实践中的注意事项
- 数据预处理:在进行特征提取前,需要对文本数据进行清洗,如去除停用词、标点符号等。
- 平滑处理:为避免概率为零的问题,常使用拉普拉斯平滑(Laplace Smoothing)。
- 特征选择:选择重要的特征可以提高模型的性能,如使用信息增益、卡方检验等方法进行特征选择。
总结
朴素贝叶斯算法是一个简单、高效的分类算法,尽管其特征独立假设在实际应用中并不总是成立,但它在文本分类等领域表现出色。通过适当的数据预处理和特征选择,可以有效提升模型的性能。对于需要快速响应的大规模分类任务,朴素贝叶斯是一个不错的选择。
四、精确率和召回率








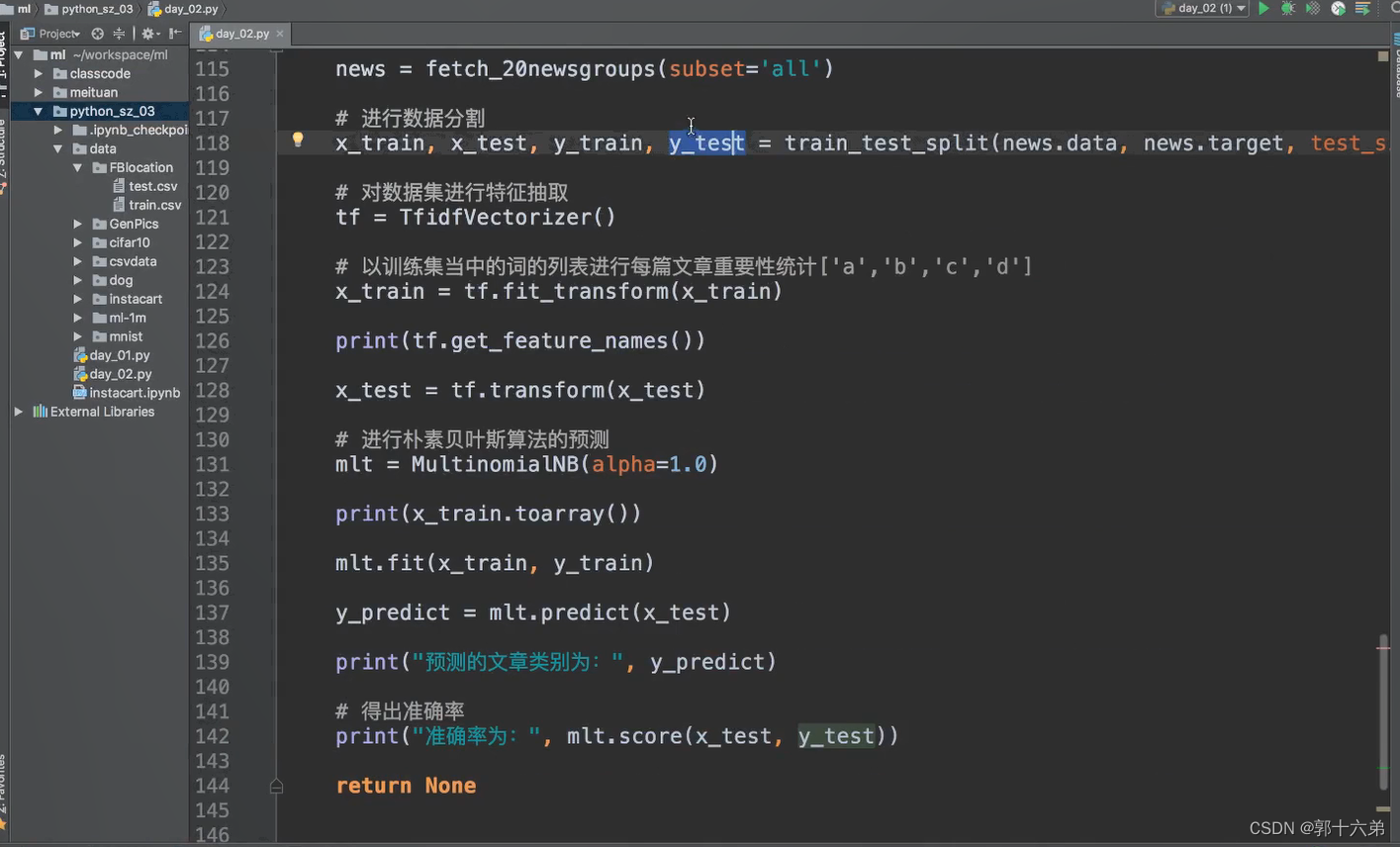


精确率(Precision)和召回率(Recall)是评价分类模型性能的重要指标,尤其在处理不平衡数据集时。它们帮助我们理解模型在识别正类(例如,垃圾邮件检测中的垃圾邮件)方面的表现。



五、交叉验证与网格搜索对K-近邻算法调优






交叉验证(Cross Validation)和网格搜索(Grid Search)是两种常用的机器学习模型调优方法。
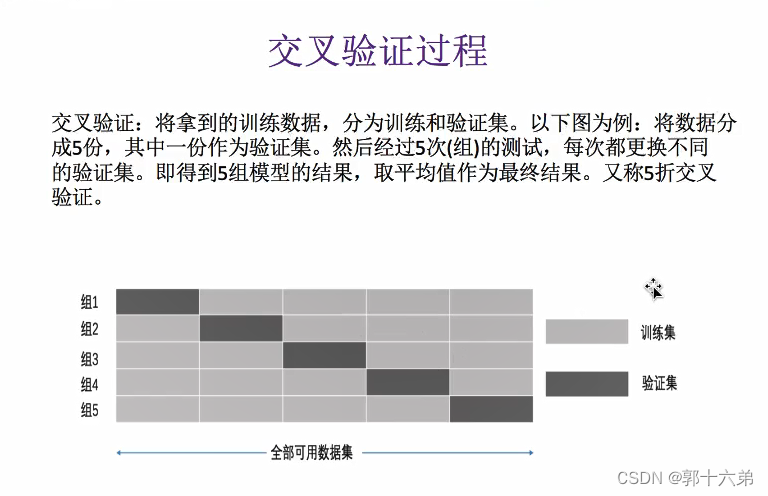
1. 交叉验证
交叉验证是一种模型验证技术,用于评估模型在数据集上的表现。常用的方法是k折交叉验证(k-fold cross-validation),其步骤如下:
- 将数据集随机分为k个等份。
- 依次用其中的k-1份作为训练集,剩下的一份作为验证集,训练并评估模型。
- 重复上述过程k次,每次选择不同的验证集。
- 将k次的评估结果进行平均,作为模型的性能指标。
交叉验证的优点是充分利用数据,提高模型评估的稳定性。
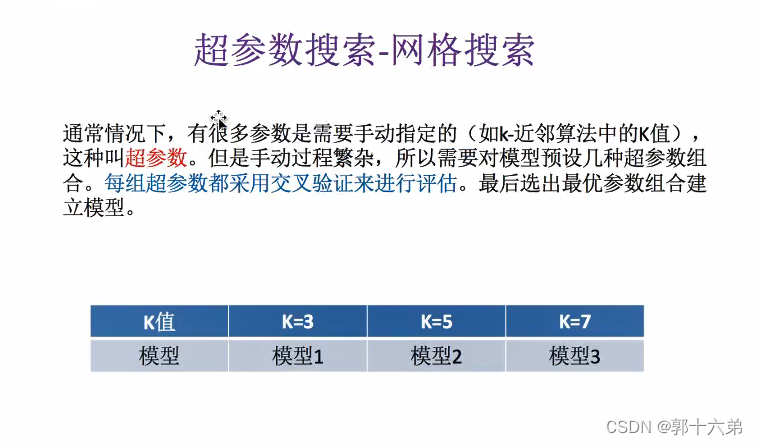
2. 网格搜索
网格搜索是一种超参数优化方法,通过穷举搜索指定参数空间中的所有可能组合,找到使模型性能最优的参数组合。
3. K-近邻算法
K-近邻算法是一个简单的监督学习算法,用于分类和回归问题。其核心思想是基于距离度量,对新样本进行预测。
4. 交叉验证与网格搜索结合调优KNN
我们通过交叉验证和网格搜索来调优KNN模型的超参数。常调优的超参数包括:
- n_neighbors: 邻居的数量k。
- weights: 预测时使用的权重类型('uniform', 'distance')。
- metric: 距离度量方法('euclidean', 'manhattan', 'minkowski')。
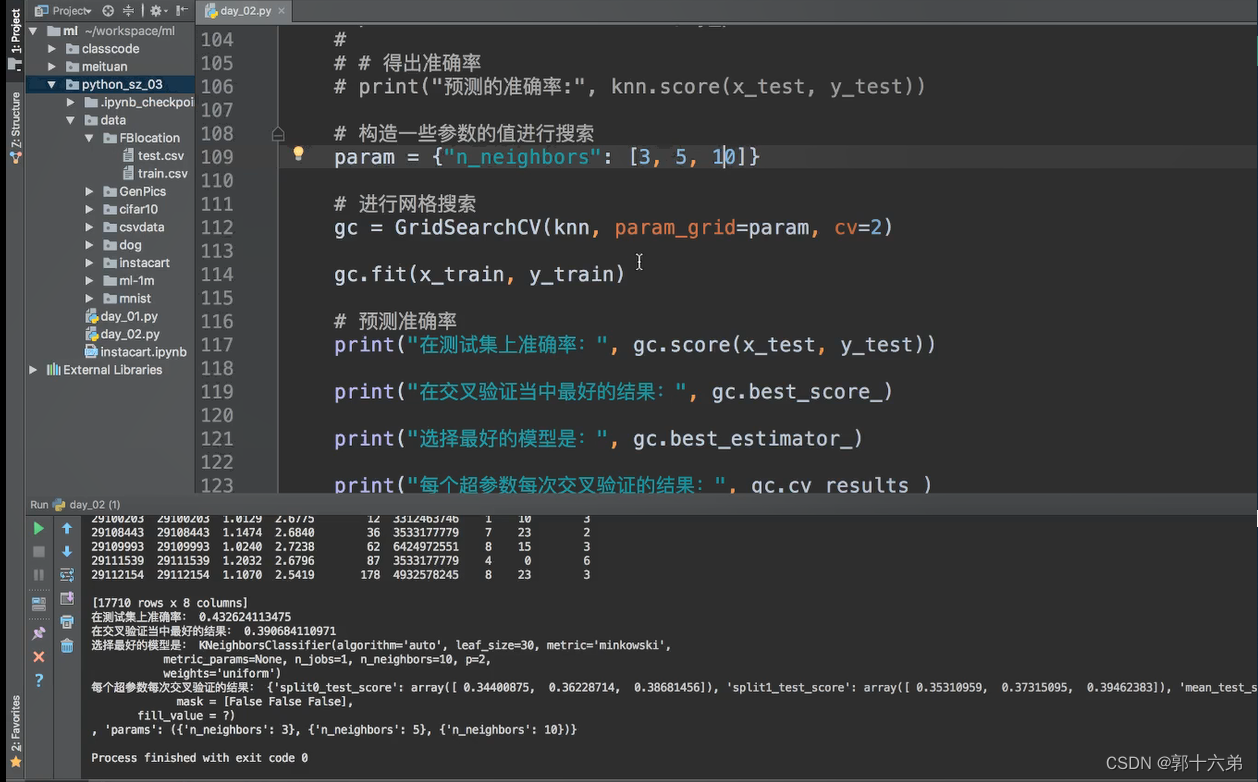
下面是具体的代码示例:
import numpy as np
import pandas as pd
from sklearn.model_selection import GridSearchCV, cross_val_score
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 加载数据集
data = load_iris()
X = data.data
y = data.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 定义KNN模型
knn = KNeighborsClassifier()
# 定义参数网格
param_grid = {
'n_neighbors': np.arange(1, 31, 2),
'weights': ['uniform', 'distance'],
'metric': ['euclidean', 'manhattan', 'minkowski']
}
# 使用GridSearchCV进行超参数搜索和交叉验证
grid_search = GridSearchCV(knn, param_grid, cv=5, scoring='accuracy')
grid_search.fit(X_train, y_train)
# 输出最优参数和对应的准确率
print(f'Best parameters: {grid_search.best_params_}')
print(f'Best cross-validation accuracy: {grid_search.best_score_:.2f}')
# 在测试集上评估模型性能
best_knn = grid_search.best_estimator_
test_accuracy = best_knn.score(X_test, y_test)
print(f'Test set accuracy: {test_accuracy:.2f}')
结果解释
- 加载数据集并划分数据集:加载Iris数据集,并将其划分为训练集和测试集。
- 定义KNN模型和参数网格:定义一个KNN模型,并设置需要搜索的参数网格,包括邻居数、权重类型和距离度量方法。
- 使用GridSearchCV进行搜索和交叉验证:通过5折交叉验证,网格搜索找到使模型准确率最高的参数组合。
- 输出最优参数和准确率:输出最优参数及其对应的交叉验证准确率。
- 在测试集上评估模型性能:使用最佳参数的KNN模型在测试集上进行评估,并输出准确率。
总结
通过交叉验证和网格搜索,我们可以有效地调优KNN模型的超参数,从而提升模型的性能。交叉验证可以提高模型评估的稳定性,而网格搜索能够找到最优的参数组合。这种方法不仅适用于KNN算法,还适用于其他机器学习模型的超参数调优。















 922
922











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









