







目录

项目组多少人?
我是ETL组,三到六个人


技术架构
数仓:Hadoop CDH6.3.2+Hive3.1.2
数据同步:Datax
系统环境:Linux(Centos7)
任务调度:xxl-job
分层架构

ods:原封不动抽取数据
全量抽取
类似于数据迁移或数据复制,它将数据源中的表或视图的数据原封不动的从数 据库中抽取出来,并转换成自己的ETL 工具可以识别的格式。
第一次抽取,无论什么表都是全量抽取
增量抽取
只抽取自上次抽取以来数据库中要抽取的表中新增或修改的数据。在ETL 使用过程中,增量抽取较全量抽取应用更广。如何捕获变化的数据是增量抽取的关键。对捕获方法一般有两点要求:准确性,能够将业务系统中的变化数据按一定的频率准确地捕获到;性能,不能对业务系统造成太大的压力,影响现有业务。
事实表从第二次抽取开始,使用增量抽取
面向的主题
销售主题 (开发)

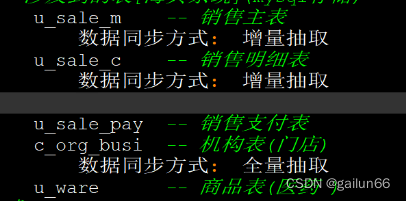
财务主题
采购主题
门店主题 (自己做)
会员主题 (自己做)
库存主题
dw:模型设计(项目经理主导)
该层宽表为事实表,ODS层的表为事务表

模型 :
- 星型模型(一期使用的就是该模型)
- 雪花模型
- 星座模型
数据的清洗转换
去重
- group by
- distinct
- row_number()over(partition by 有重复数据的字段 )
空值
- 主键空值 , 一般是 删除 该条数据
- 其他列空值, 一般会根据开发文档的要求去处理, 将 空格 'NULL' 等字符串列 转换成 null 值 数值型 一般转换成 0
不规范数据 :
- 身份证号
- 手机号
- 邮箱
- IP
码值的转换
- 支付码值
- 性别
- 国家
- 币种
制作宽表
dm和ST:指标加工
该层指标表为事实表,DW层的宽表为事务表
根据公司各个业务部门提供的需求进行指标的开发
BI:数据报表展示
ETL处理过程

从0到1搭建医疗数仓的流程
项目准备 项目启动(1个月)
项目总体计划
项目启动会准备及所需材料
项目启动会召开
分析调研(和各个部门调研分析需求)\项目的架构设计(2个月)
系统开发和测试(3个月)
源系统数据库和数据源连接方式


你对接过哪些ERP系统?
海典 雨诺 用友 九鼎 舵手
各个部门提供指标和加工口径(这是出示在应用层的数据)

DataX
一文带你看懂DataX离线同步工具(图文并茂,看完就懂)_datax工具-CSDN博客
DataX概述
DataX 是阿里巴巴开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle 等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
源码地址:阿里云DataX源码
DataX支持的数据源

使用方法
明确数据流向,使用datax.py生成对应json
datax.py的路径

mysql→oracle
python datax.py -r mysqlreader -w oraclewriter
mysql→mysql
python datax.py -r mysqlreader -w mysqlwriter
oracle→mysql
python datax.py -r oraclereader -w mysqlwriter
oracle→文本文件
python datax.py -r mysqlreader -w txtfilewriter
oracle→hdfs
python datax.py -r oraclereader -w hdfswriter
填写json数据
--从oracle抽取数据到mysql的json
{
"job": {
"content": [
{
"reader": {
"name": "oraclereader", --从oracle读取数据
"parameter": {
"column": ["*"], --你要抽取的字段
"connection": [
{
"jdbcUrl": ["jdbc:oracle:thin:@//192.168.68.42:1521/orcl"],
--jdbc:oracle:thin:@//192.168.68.42:1521/orcl 连接oracle的方式 /orcl为数据库名
"table": ["emp"] --要读取的表名
}
],
"password": "123456", --密码
"username": "scott" --用户名
"where": "" --where为过滤条件 可以省略
}
},
"writer": {
"name": "mysqlwriter", --将数据写入mysql
"parameter": {
"column": ["*"],
--你要更新数据的字段 字段属性 顺序 数量要和oracle相同
"connection": [
{
"jdbcUrl": "jdbc:mysql://192.168.232.67:3306/sys",
--连接mysql的方式 sys为数据库名
"table": ["mydept"] --表名
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8138
8138











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









