







大模型在数据仓库领域应用的一些探索
从2024年下半年开始,大模型的应用生态迅速爆发,第一个给我带来震撼的是Cursor,意图识别的准确率做到了相当高的水平;第二个就是春节期间的DeepSeek,第一次让我看到了本地部署和微调的可能性。这篇文章简要介绍下大模型在“数据仓库”领域的一些常见应用方式,以及我自己使用的一些心得体会。
|0x00 辅助编码
代表作是Cursor/WindSurf等工具,原本我们认为辅助编码是节约一些重复性的工作,比如建表/写注释,但实际上手后发现,实际上绝大多数的需求,Cursor都能够快速帮我们实现。
举个实际例子:
(1)将需求转换为文字描述:以下是需求内容,读取xx表;
(2)撰写统计需求:by日维度,统计访问PV、GMV、支付订单数、支付UV;
(3)补充一些实现细节:例如订单标签的获取方式参考xxx,需要生成表结构和执行sql;
(4)执行,Cursor会根据我们的需求内容和xx表,自动生成好数据。
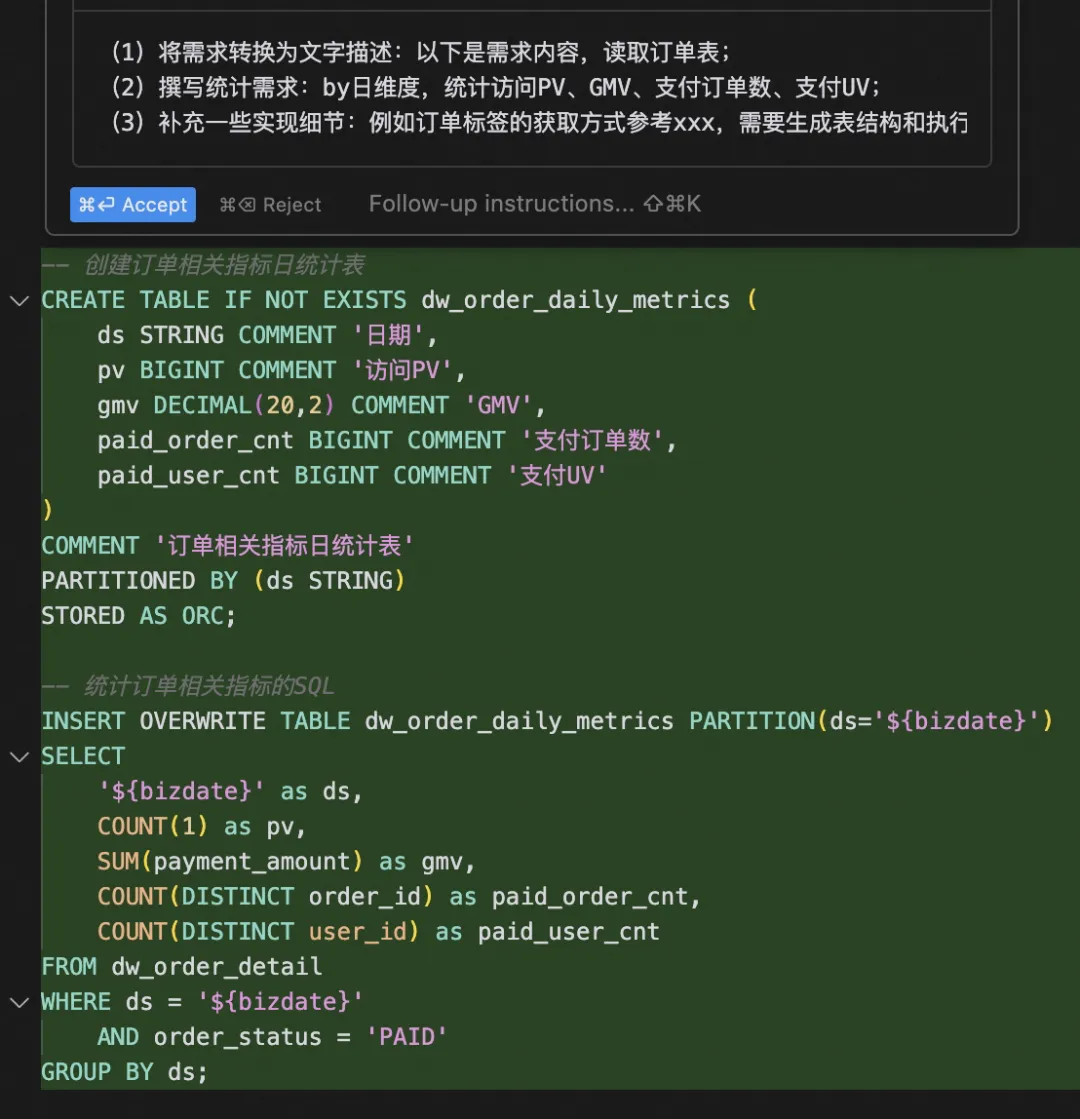
实际上,如果我们能把之前的一些实现sql,给到Cursor做参考,基本上不需要做二次修改,就能直接使用写好的结果。
在日常工作中使用下来,保守估计开发效率能够提升30%以上,如果业务方给到的需求比较规范,50%+也不是什么问题。主要提升的点在于,我不需要动脑子,只需要当个纯粹的复制粘贴工具人即可,如果大模型写错了,就一直追问,它会自动改正。
但使用这类工具有如下几个问题:
(1)数据安全问题,敏感数据有泄露风险;
(2)部分时候代码也会写错,不能完全信任;
(3)依赖比较规范的团队文档库,如果本身数据就有歧义,大模型也解决不了。
因此,DeepSeek出现后,我非常开心,因为有了规避数据安全的手段,也有了微调的可能性。这对我们做研发的冲击非常大。
|0x01 业务提数
ChatGPT3.5版本诞生时,我们就想到了能不能让大模型来提数,给不懂sql的业务使用,本身我们就有比较完善数据仓库体系,这个能力并不难实现。
核心实现的思路是:用户输入一句话,大模型识别出用户输入的信息里需要获取的指标、自动化SQL生成,然后将SQL丢到执行引擎中,最后反馈执行的结果。
但很快,我们发现这种方式也有弊端,因为我们面向的用户并不是专业的技术人员,而且同样一件事情,不同人理解和说出来的内容可能完全不同,这就导致语义识别非常难,而且用户也无法判断输出结果是不是准确的。比如什么是“新客”?如果没有事先的定义,搞错的概率相当高。
因此,这个路径很快就发展成了,要么问一些固定的套路化问题,要么用户需要有自己辨别数据是否准确的能力。总之,提数是一件很个性化,但又有明确对错结论的事情,我们在产品功能设计上,倾向于将准确性的问题让用户自己判断,这在一定程度上限制了工具的推广。
因此,如果一个业务非常新,或者新加入的员工很多,那么这个工具还是比较有用;但如果是比较成熟的业务,或者是人员高度稳定的团队,这个能力就比较鸡肋了,大家都有比较高效的提数方法,比如搭建数据门户。
|0x02 自助分析
这个方向可以简单概括为:“能否用一句话生成分析结论”。
早起我们都认为,大模型所具备的推理能力,实际上是能够替代数据分析师的职责,比如分析下昨天北极星指标的波动原因,让大模型分维度下钻拆解后,告诉我影响的主要因素是什么。
但实际上,这只能解决一些比较常规的分析问题,因为常规问题大家平时接触的多,解决的思路也相对固定,所以是一种“解决重复劳动”的方式来实现。比如异动归因、赛道洞察、潜力评估、流失预测等,本质还是需要我们根据已有的业务经验,来设计和实现,需要提前定义好指标拆解路径和输出文案一类的工作。
所以,未来低端的研发和BI一样,都会被大模型替代掉,但高端的提供解决方法的岗位,还是需要的。
但如果我们有足够多的token,可以让大模型直接读取我们的原始数据来分析我想要考虑的问题,这种解决的效率更高,也更适合“自助分析”这个场景。因为一旦能够读到明细数据,大模型再进行推理,往往能解读出我们思考之外的一些答案,也算是某种程度上的“集思广益”上了。
之前做尝试的时候,消耗token需要收费,现在有了DeepSeek,人人都能够进行尝试,真的是“开源”能够促进行业蓬勃发展了。
|0xFF 文档撰写
这是一个大家都比较熟知,但实际上可能都比较忽略的应用,因为在数据开发的方向,不仅仅写代码比较重要,给写好的代码加上读得懂的注释,同样重要。
同理,像代码纠错、代码改写、修改注释、生成模板等编码工具的提效,也已经陆续的在开发工具中应用了起来。目前看对效率提升在5%左右,等待未来上线更多功能和提升准确率,效率提升的会更多。
最近有个新闻,Facebook开始尝试用大模型完成绝大多数的业务逻辑撰写,然后在2月10号就启动了大规模裁员,真的是纯纯的资本家。如果所有业务逻辑都用大模型实现,那么文档撰写这种事情也就不需要了。
除了写文档之外,做对外答疑类的事情,大模型算是非常擅长的方向了,很多需要人介入的场景,大模型就能做替代。我们之前经常吐槽的印度客服问题,或许在这一轮技术革命里就能完成替代。
| 总结
这一轮AI革命正在爆发中,从趋势看,未来大部分程序员是真的要被淘汰了。好消息是,整理好底层数据和文档,保证准确率,依然是“刚需”,未来数仓仍有就业的一席之地;坏消息是,业务一旦成熟,这部分同样只需要一点运维的成本。
因此,未来的前景,作为数仓工程师,还是要卷业务理解。因为,把所有人推到赚钱的第一线,满足资本家增长的需要,这种社会规则依然没变。

















 4837
4837

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









