






关联比赛: 第三届数据库大赛创新上云性能挑战赛--高性能分析型查询引擎赛道
序
人到中年,总有些迫不得已,世事无常,总让人黯然叹息;三十出头的年龄,代码已逐渐远去;可十年相伴一路甚欢,如今发量尚茂又暮暮朝朝
走吧,去参加一场比赛,去结交一群朋友,用一段意义非凡的经历,来点缀这若即若离的青春
所以,我们来了,带着键盘来了
自负、自卑、自信,狂妄、绝望、希望,比赛如一段浓缩的人生,充满坎坷和悲欢
抽象,蕴含着无限的想象,我们始于宏观,终于微观,惑于表象,解于本质;最终觅得友谊、知识、名次,绚烂中带着充实~
一个多月深夜的缠绵,加上两天威斯汀里的撒欢
比赛若即若离,相聚心跳不已
此刻尘埃落定,生活又回到了以前的样子
但历经磨炼的内心,仿佛多了一些无法平息的涟漪
我看不太清那是什么,但我知道,它在影响着我
用一次自我总结,为我的人生画上一个逗号
用一篇技术分享,为这场比赛敲上一个换行
哈哈,皮一下,字里行间,非常的ADB
队伍元数据
队名:shield
Slogan:
岁月如歌,青春似酒,进可强攻,退可防守
四海升平,三千闲愁,一码在手,夫复何求
攻守兼备,Shield代表着我们对生活的态度~
队员:
陈林江,男,满帮集团文艺码农,跑得比Cpu快,活得比显卡“烧”;
平平淡淡,以一持万,懵懵懂懂,有恃无恐
杜云霞,女, 税友集团测试经理,心细,腿长;
潇潇洒洒,以梦为马;跌跌撞撞,乘风破浪
吴小刚,男, 就职于成都钛数智能科技有限公司;擅长编码、种植以及家电维修;
羞羞涩涩,以耕为乐;忙忙碌碌,全力以赴
赛题思考
在大方向上,和大家一样,看到赛题的第一眼,就想到了分区存储的经典方案,就这么一见钟情了;(事实证明,最优的方案也确实是分区存储,从一见钟情,到从一而终,大方向上非常的丝滑)
PMEM对我来说是一个新东西,也是一个黑盒子,但是使用方式上和传统的磁盘是一样的,所以在代码调用层面应该是玩不出太多花样;顺序读写、随机读写,结合nio、mmap,需要先对PMEM摸个底;想一想事情还是挺多了,要不流程跑通之后再考虑吧……
Cpu密集型线程和io线程肯定是要分开,读、解析、写,三组异步线程;查询的权重显然没有load重,文件一定要顺序写,查询的时候随机读,脑袋一拍,就这么决定了
看到赛题之后,其实没思考太多,毕竟实践出真知,先按照经验和直觉,确定大方向,其他的慢慢优化吧
初赛
从体量上来看,赛题本身是很轻的,没太多复杂的逻辑,已经记不得是花了多少时间了,反正时间不长,就撸出了第一个版本,20秒左右;和往常一样,充分发挥了快男的能力,再一次同时体验了第一名和最后一名的滋味,毕竟,这样的机会,一次错过,就真的错过了
接下来就开始对磁盘的情况进行摸底,统计了一大堆后面用到了或者没有用到的数据;
申请内存耗时太长的问题,是初赛的噩梦,一直无法得到解决,这导致白花花的内存,就这么放着,不敢多用,把数据直接落盘的方案居然比不落盘,放内存的方案更快,这让我再一次被PMEM的性能所震惊,骗子,都是骗子,不是说PMEM比内存会慢一点吗,这不科学啊;当然回过头来看,当时自己挺傻的,PMEM只比内存慢一点点,所以单线程申请内存,自然没有多线程写PMEM快。
就这么一直走走停停,耗时是越来越短,代码却越来越乱;不知从哪一年开始,我不太爱刮胡须了,也许也是从那一年开始,我对代码没有了洁癖;
初赛快结束时,ADB赛道已经卷起了千层浪,大家突飞猛进的分数,让我猜到了些什么,咨询了一下导师,初赛代码不会进行review,所以带着一丝的罪恶感,我也丢弃了一部分数据(好吧,我承认,其实是大部分),无耻地在初赛排到了第一的位置。
复赛
复赛就多了一个持久化的逻辑,由于程序结构设计上还算过得去,所以大概花了几个小时的时间,就把复赛的流程跑通了,五六十秒的样子;
自以为是的我居然自豪地给队友显摆这个成绩:“初赛不丢数据要八九秒多,复赛数据量是初赛的6.6倍,所以耗时五六十秒左右,多么的浑然天成,这个赛题没啥意思,成绩都可以进行线性推算的,不出意外这个成绩就能排前三了”;
噗嗤,当初天真的样子在现在看起来就像一个涉世未深的孩子,喃喃地说到要和小学的同桌在一起一辈子;
后来一细想就知道自己草率了,初赛cpu是瓶颈了,复赛cpu翻倍了,如果复赛IO仍然不是瓶颈,那么复赛load阶段至少是能到9*6.6/2=26.4,算上重启的6秒,再加上查询的10秒(1024的分区),那得是42秒左右啊;难道io到瓶颈了,掐指一算,不可能啊;赶紧看一下cpu使用情况,将近40%的idle,赶紧增大相关线程数,成绩只是略有提升,idle降得很厉害,显然是线程太多,内卷了;
当时整个人都不好了,感觉有些迷茫,感觉曾经高傲的自己被赛题狠狠地摔在了地上,然后用力地摩擦,感觉有些力不从心,感觉不知从何做起;
大概有连续四五个晚上,都是在做一些没有意义的参数调整,总希望着奇迹会出现,可出现的,只有老婆的呵斥,和女儿的哭闹。
这一切都源于我当时所面临的问题点已经超出了我的认知范围;自己一直都知道增加分区数会导致load变慢,但是从来没有去深思过本质是什么,只想着一味的去逃避,总觉得大家都有这个问题。
周末的时候,我会去锦城湖边躺一躺,湖边的微风散走了热浪,辽阔的视野可以让我把数据结构在天空中进行抽象;湖边的别墅是一个一个的数据块,湖里的小船是我搬运数据的流水线;睁开眼清清楚楚,闭上眼又零零乱乱;
一遍又一遍,我随手翻着各种计算机底层的文章,似懂非懂,若有所悟;我开始重新去深入了解cpu缓存,去了解cpu的执行原理,相关概念都已经透彻了,我和答案之间就隔着一层薄薄的纸,迟迟未被捅开
直到有一天,我在锦城湖的别墅门前,看到了一个和尚,是的,一个很富有的和尚
那一下午,我满脑子里都是和尚:和尚挑水,和尚搬砖,和尚送货…
脑海里那一个个Bling Bling的脑门向我闪耀着智慧的光芒,我贪婪地接受着瞎想给我带来的馈赠;突然间一道闪电,一切尘埃落定;
和尚没了,方案有了;缓冲区在时间维度上的使用率问题、分区时缓存失效的问题,就这么有了标准的答案;
由于潮汐刷盘现象及其严重,四组线程之间不是你等我就是我等你,为何不减少整体线程数?想办法让大家都不要等待,减少忙时的竞争和闲时的磨洋工,让整体效益更高。
完美,这像极了我想要招一个全栈工程师的想法;
于是乎,结合潮汐刷盘的现象,条件性线程共享+线程援助的概念应运而生。
耗时刷刷地降低,有一种运筹帷幄的感觉。
缓冲区大小与刷盘块大小之间的矛盾,是横在我面前的最后一座大山,深夜时路边的共享单车,给了我灵感;
当时由于做完了线程共享的优化,脑子里面全是共享,路边hello和美团的调度车人员,正在把自行车往货车上搬,货车要去好几个地点,才能将车厢装满;这像极了我程序里面小块copy到大块的逻辑,哎,要是这些单车都是放在一起的多好啊,一次性就可以把车装满了。 对啊,要是这些满了的缓冲区是在一起的,那我不用copy我就能获取到大块了啊!!!
Unsafe+reflect,连续的缓冲区串成一串,结合一个按照内存地址排序的优先队列,大块来了,0 copy;
接着再利用一下潮汐刷盘的现象,优先队列可以不要了,所有缓冲区都满了后,按内存地址排个序,得到一块绝对连续的大内存,刷盘的时候想怎么拆就怎么拆;
方案很简单,但是探索的过程却很艰难,这像极了生活,我们拼命地挣扎着,只为简单地活着;
最终方案
作为一个懒人,我直接以答辩的ppt作为核心素材,讲一下最终的程序方案
这一页和技术没关系,大家看看就行
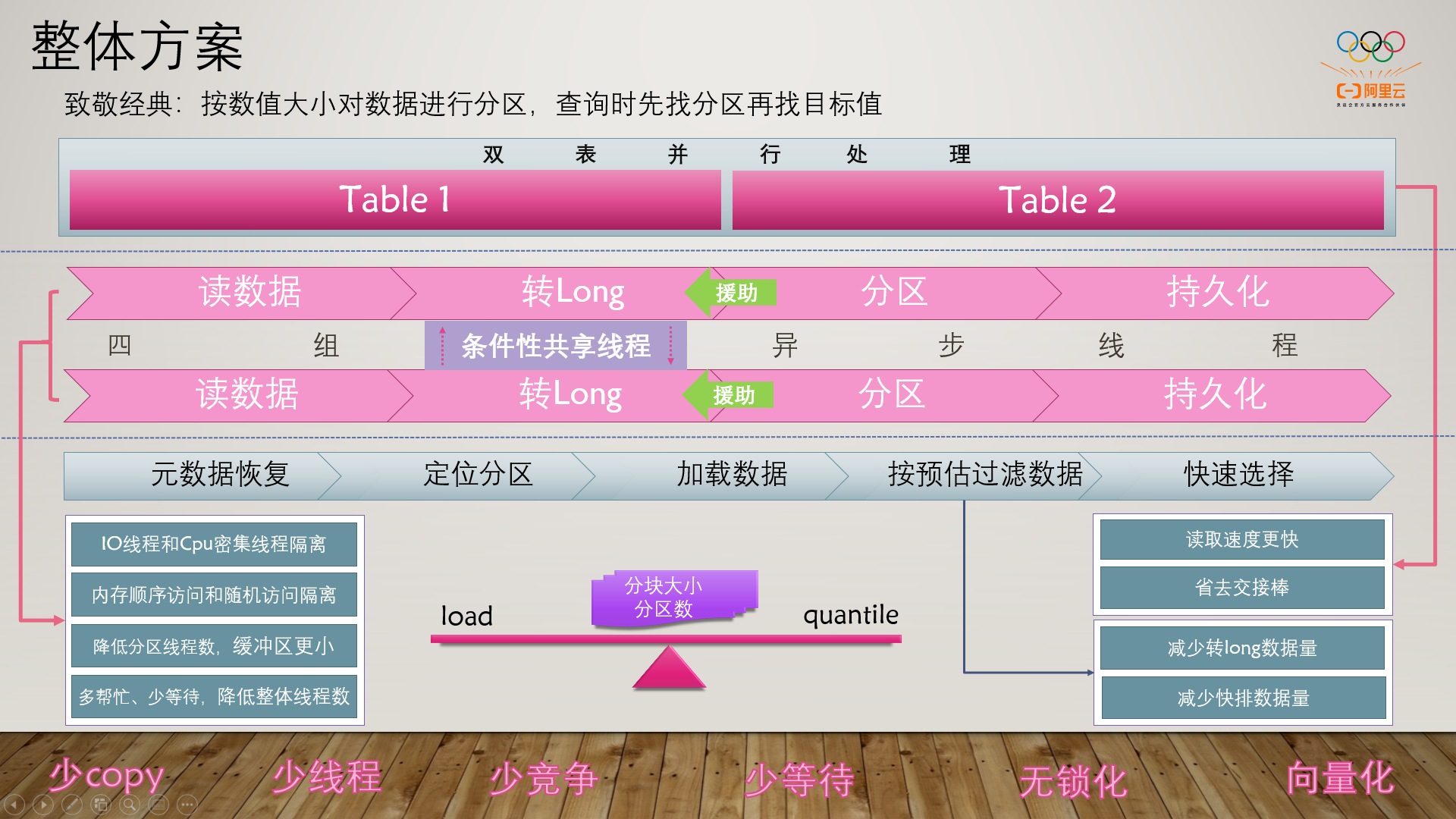
大方向上,使用了分区存储的经典方案,由于持久化盘双文件读取速度更快,所以进行了双表并行处理;
逻辑上分成了读、转long、分区、写盘四个异步环节;转long和分区分开,可以大幅减小缓冲区大小;有效降低初始化成本;因为为了无锁话,分区的线程和分区缓冲区是一一对应的,传统方式,4个解析线程意味着要四组分区缓冲区,换成2组转long+2组分区,就只需要2组缓冲区了;
由于线程过多会影响cpu效益,所以引入了条件性共享线程以及线程援助的概念,这样在整体线程较小的情况下(为了cpu效益),也能保证cpu的使用率;
然后通过分区的数量、缓冲区的大小来做平衡,以求得一二阶段的总耗时最小化
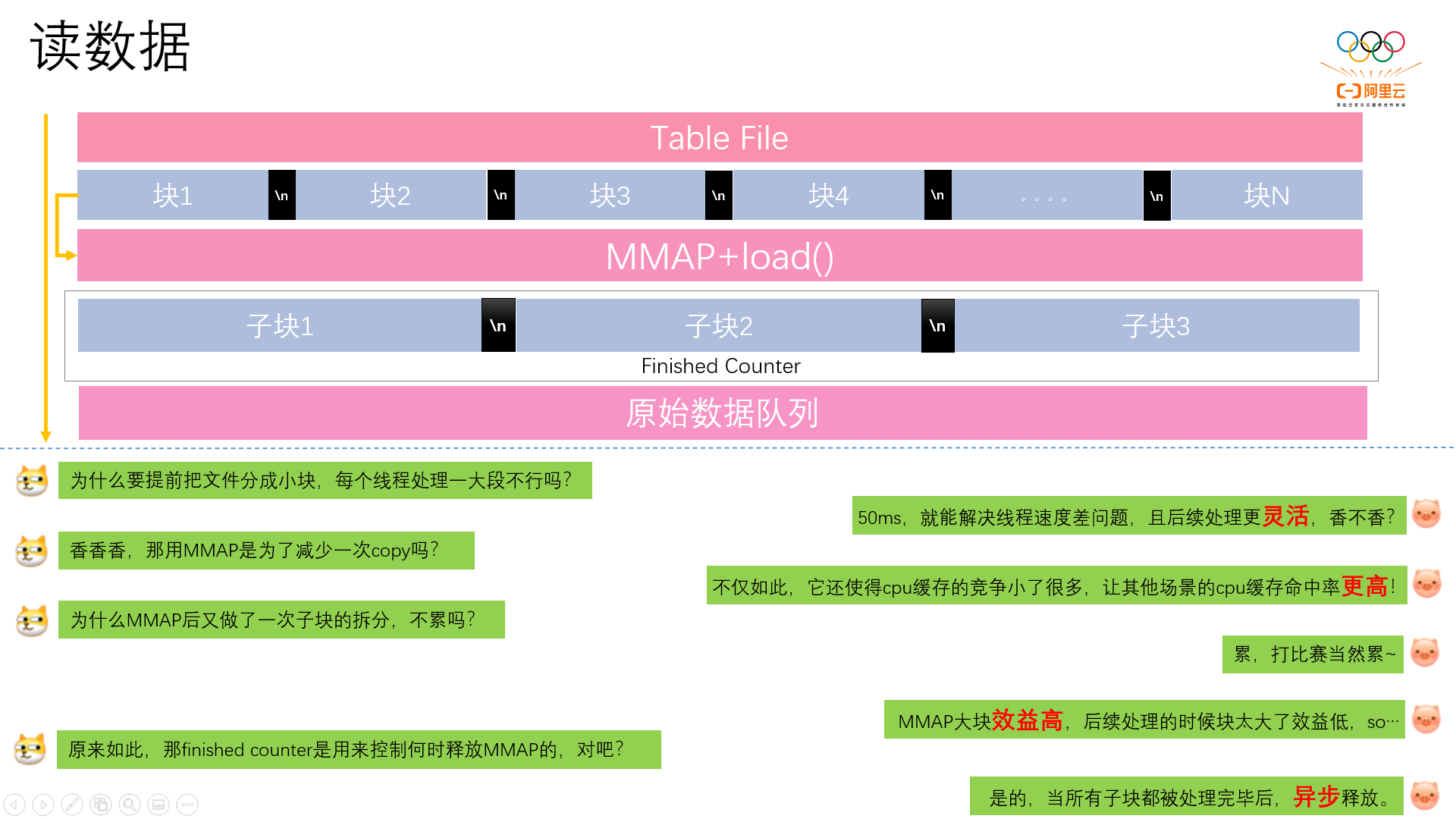
读数据时,先把文件在逻辑上分成了小块(大概几十M的样子),这样可以解决切分成大块导致的线程速度差的问题(有些线程先完成,有些后完成,导致收尾阶段读取速度达不到极致),一个逻辑块是一个独立的任务,在处理上也更加的灵活(比如我们可以在某种情况下临时增加读取线程的数量);
然后对每一块进行mmap映射,使用mmap不但可以减少一次拷贝,还可以使cpu缓存的竞争变小很多(因为cpu缓存的新陈代谢变慢了),这对后续的分区环节来说,非常的重要;
最后考虑到大块进行映射效益更高,但是对后续流程又不友好(快太大分区的时候更容易出现缓存行失效的问题),所以对映射出来的大块又进行了逻辑子块的拆分,每一个子块是后续处理的一个基本单元,最后用一个计数器来协助进行映射块的内存释放管理(所有子块都处理完毕后,异步释放mmap);
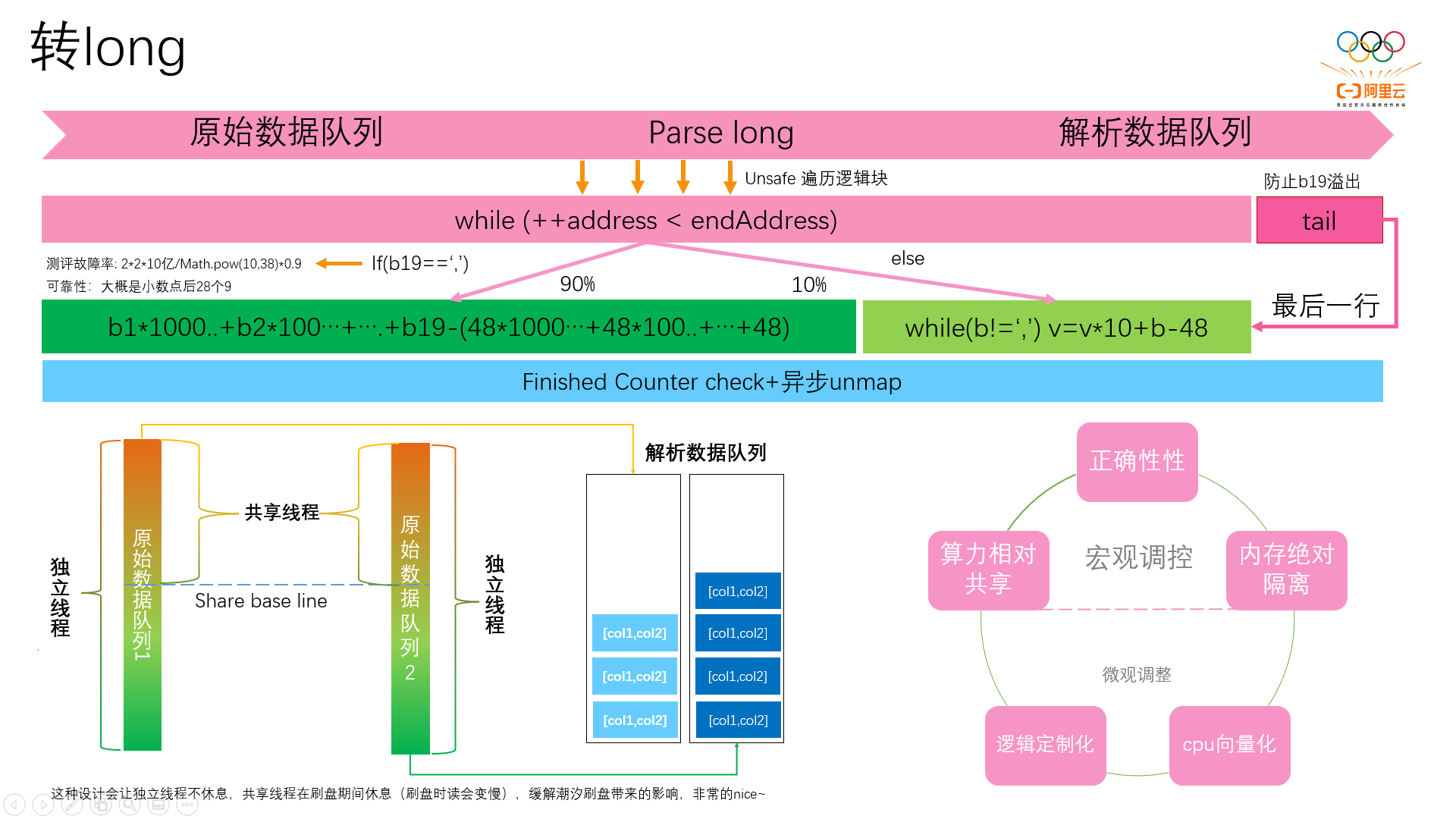
接下来是转long,遍历时候引入了差异化逻辑,如果19位后的数字是逗号或者换行,就使用对应位乘以10的n次方进行转换;这种方式没有前值依赖,有利于cpu向量化;
当然这种跳空判断的方式是有风险的,当19个字符中包含三个数字时就会出现逻辑混乱,但是通过推算,出现这种风险的概率极小;
然后每一位上减去48的逻辑提了出来,到最后统一减一个常量,这样,每一个数字解析都可以减少18次减法运算;
每一批数据会切出来一个尾巴,不走跳空判断的逻辑,以避免跳空判断时出现内存访问越界(如果在遍历的时候加上一个if判断,只在不越界的时候进行跳空判断,会导致耗时大幅增加);
在任务处理上,每张表各使用一个独立的原始数据队列和结果数据队列,且拥有一个独立线程,当原始数据队列出现较大的堆积时,共享线程会介入;
这种设计会让独立线程一直工作,共享线程在非刷盘期间工作,能够缓解潮汐刷盘对上游的读取速度带来的周期性波动影响,比直接增加转long线程效益更高
查看更多内容,欢迎访问天池技术圈官方地址:【攻略】第三届数据库大赛创新上云性能挑战赛-高性能分析型查询引擎赛道-冠军_天池技术圈-阿里云天池















 1722
1722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









