






关联比赛: 2021第二届云原生编程挑战赛2:实现一个柔性集群调度机制
参赛心得
历时快两个月的第二届云原生编程挑战赛结束了,作为第一次参赛的萌新,拿下了28名的成绩,与第一名差了19万分,因为赛制时间太长,加上期间学业有各种事以及国庆摆烂,没能拿到前十。到最终也不知道差到那19万分哪儿了。这里将我们的思路做一个分享。期待top10大佬的分享!
题目解析
题目背景就不再赘述,这里我们直接看测试过程:
测试过程:
1. PTS 作为压测请求客户端向 Gateway(Consumer) 发起 HTTP 请求,Gateway(Consumer) 加载用户实现的负载均衡算法选择一个 Provider,Provider 处理请求,返回结果。
2. 每个 Provider 的服务能力 (处理请求的速率) 都会动态变化。
3. 三个 Provider 的每个 Provider 的处理能力会随机变动以模拟超售场景
4. 三个 Provider 任意一个的处理能力都小于总请求量
5. 三个 Provider 的会有一定比例的请求处理超时(5000ms)
6. 三个 Provider 的每个 Provider 会随机离线(本次比赛不依赖 Nacos 的健康检查机制,也即是无地址更新通知)
7. 评测分为预热和正式评测两部分,预热部分不计算成绩,正式评测部分计算成绩。
8. 正式评测阶段,PTS 以固定 RPS 请求数模式向 Gateway 发送请求,1分钟后停止;
9. 以 PTS 统计的成功请求数和最大 TPS 作为排名依据。成功请求数越大,排名越靠前。成功数相同的情况下,按照最大 TPS 排名。
解析:
从1可以看出,我们要实现的是Gateway层,在Gateway层实现负载均衡算法。
从2可以看出,我们需要动态维护Provider在一段时间内的信息,并且在这个基础上进行预测。
从3可以看出,我们不能给每个Provider的权重设置为一定。需要动态更新。
从4可以看出,需要给三个Provider负载均衡,以吃下更大的请求量。
从5可以看出,必须处理超时的请求,否则会大幅影响成绩。
对于第6点,我们设计了离线检测,但是对我们的成绩并没有提升。
从7可以看出,我们可以利用预热时间,获取一些有用的信息,设置为参数,然后进入下一个节点。
8、9是成绩评测机制。成功的请求越多,成绩越高。
解题思路
针对以上信息,我们设计了以下策略:
快速失败策略
作用:请求在多久没有完成之后(设这个时间为t)就认为其失败,不再等待返回信息,然后进行重试,可以大幅增加请求处理的数量(测试中有很多执行时间为5000ms的消息干扰,不加快速失败策略只有几万分)。
我们进行了以下尝试:
1、基于历史日志进行一元线性回归预测t值(已失效)。
2、线上基于队列进行一元线性回归预测t值(效果不好)。
3、线上利用近期请求的平均执行时间预测t值(效果最好)。
在A榜阶段,我们解析了日志,然后发现请求量和请求时间是一个线性的关系。处理的步骤如下图所示:
图1 数据处理前
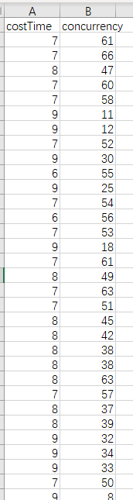
图2 数据处理后
然后对这个数据进行一元回归分析:
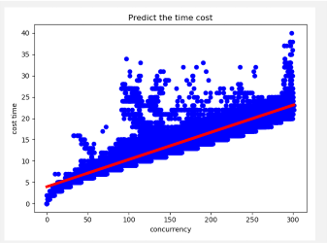
图3 一元回归预测
最终将一元回归得出的方程带入超时时间,通过当前的并发量和方程预测请求应该在多长时间内结束,然后将这个时间放宽作为我们的超时时间,这个策略在一段时间内让我们得成绩有所上升。
但是好景不长,没过多久出题方改了评测机制,三个provider出现性能大幅差异以及不再线性,加上后面还会不提供日志,于是我们舍弃了这个思路。
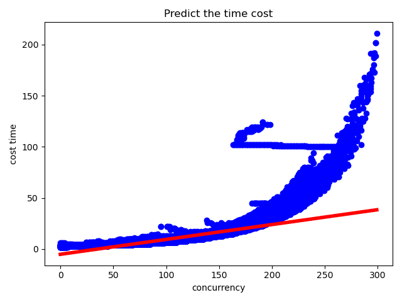
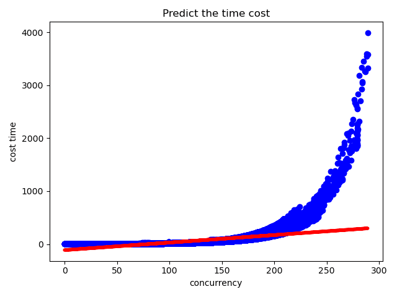
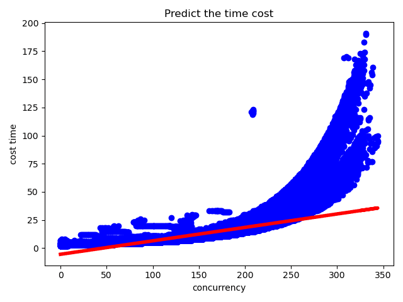
图4-6 改了评测机制后的一元回归
于是我们对每个Provider维护一个队列,队列中存放一个对象,对象包含最近0.1ms的请求的耗时,当前的并发数等信息。然后利用这个队列中的信息进行预测:
1.线上一元线性回归预测
将一元回归的代码整合进代码中,每来一条请求,就利用队列中的近100条信息进行一元回归预测,然后再加上一点时间,从微分的思想上来说,这样也是可以得到一个较好的预测的,但是耗时太长,导致成功的请求数反而有所下降。
2.平均时间预测
我们计算出当前维护的队列中所有的请求的平均耗时,然后将其加上一点点,作为预测的超时时间,作为我们的最终策略。
负载均衡策略
负载均衡策略我们几乎尝试了所有的负载算法,以及自己尝试了很多负载均衡算法。比如:
定义:
weight : 计算中的生产者的权重
originWeight :计算前生产者的权重,每次分发前更新一次(因为测评机制3):min = 10 , middle = 15 , max = 20
totalWeight : 三个生产者的总权重
P : 选中概率
memory : 剩余内存
CPU : 剩余CPU占比
avgTime : 最近0.1ms中的消息的平均处理时间
select : 最终选中的处理请求的生产者
active : 当前活跃数
算法:
1.加权轮询算法
weight = originWeight * memory * CPU * (-Math.log (avgTime) + 9)
P(select) = P(weight / totalWeight)
2.最小连接数算法(最优)
if (count (min(active)) == 1) select = min(active)
else select = Max(weight) in Min(active)
3.加权最小连接数算法
weight = originWeight * memory * cpu * (-Math.log(avgTime) + 9)
select = Min (weight / active)
4.最大空余线程数比例算法
Select = Max((maxActive – active) / maxActive )
5.最大空余线程数算法
Select = Max(maxActive – active)
最终最优的算法是最小连接数算法,我们在使用最小连接数算法前进行了一个判断,如果该provider已经被限流,则不参与本次选举。
限流策略
不限流的话性能比较差的provider会直接被压垮,并且有很多的5000ms的超时请求,所以必须在provider端实现限流。实现的限流类似于限流算法中的计数器算法,就是定义一个最大线程数,定义一个超时时间timeout以及当前活跃的线程数active,当active小于等于max时就不处理正常执行,大于max时等待timeout长的时间,等待里面的请求自动超时,在这期间如果有请求结束,则唤醒一个新请求,如果在这段时间里有请求没有结束,就让正在活跃的请求全部失败。
服务离线策略(未生效)
在官方的赛题说明中,提到三个生产者会随机离线,然后就设计了这个离线策略,但是奇怪的是并没有生效。策略是:如果一个服务上一次成功执行请求的时间距离现在特别长,就让其在一段时间之内不再执行,过一段时间之后再给它恢复正常。如上图所示,如果一个服务上一次请求的时间距离现在很近(比如为500ms),那么就判定该服务正常,让其正常执行,如果一个服务上一次请求成功的时间离现在大于500ms,就将它上一次请求成功的时间设置为当前时间往后的第500ms,在这之后500ms内,服务这个服务不再参加选举。这个离线的时间我们也做过一版动态的,比如第一次离线就让其离线50ms,第二次就让其离线100ms,第三次让其离线150ms。但是无论怎么调整判断离线时间和离线时间的数值,都对成绩没有提升效果。
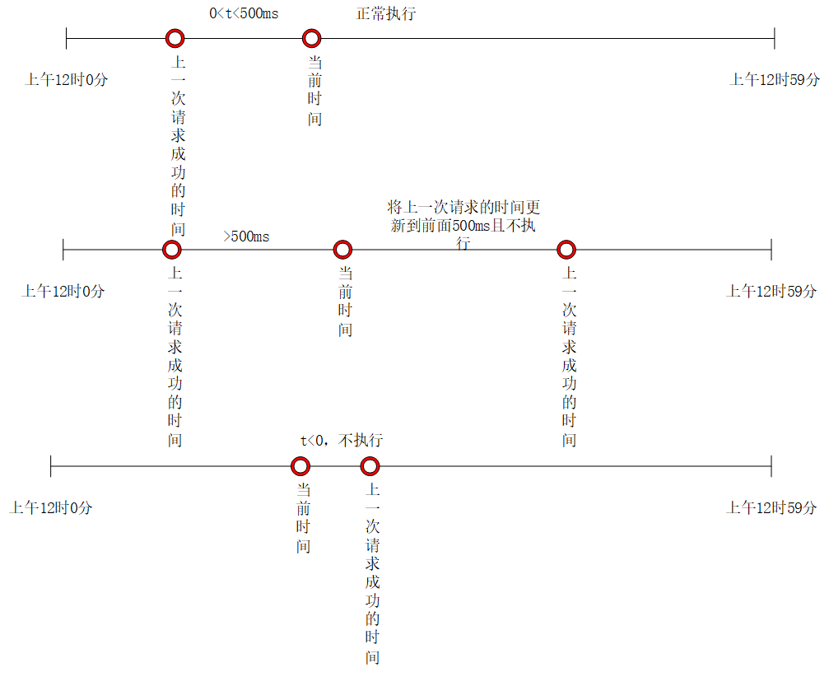
图7 服务离线策略
利用预热时间探测最佳并发量
在测试时有一分钟的预热时间,我们利用其1分钟探测出服务的最佳并发量。因为服务性能可能会动态变动,所以我们这里可能做得不是很好,期待大佬的帖子。
探测的思路是:
定义变量:
每秒钟成功的请求数successCountPerSecond
当前限流的并发数: max
每秒钟最大成功请求数: bestSuccessCountPerSecond
最佳并发量: bestConcurrency
我们在一个定时器中执行以下代码:

图8 探测最佳并发量
最后快到1分钟时,不再执行这段代码,并将限流的数量设置为探测出来的max。
历时快两个月,最终成绩28名,明年继续努力!
仓库地址:
https://gitee.com/bestanswer/pullbased-cluster
查看更多内容,欢迎访问天池技术圈官方地址:参赛心得和思路分享:2021第二届云原生编程挑战赛2: 实现一个柔性集群调度机制_天池技术圈-阿里云天池















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









