







Execution Ordering
Out-Of-Order Execution
为了提高性能,程序指令的执行顺序可能被编译器或者硬件改变,比如:
- Optimize the compiler to minimize repeated execution intervals
- Example: Routine that increases by 1 repeat 100 times -> increases by 100 at a time
- When a single process (HW thread) processes the instructions in some parallel rather than sequentially
另外,指令还可能会被预取执行,因此,不同顺序的指令可能同时执行:
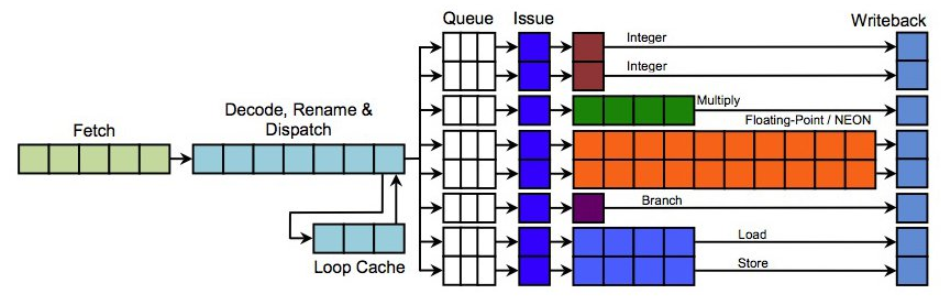
- 比如有五种处理类型(Integer, Multiply, Floating-Point/NENO, Branch, Load/Store),被不同的指令引入;那么,由于他们分属于不同的单元处理,所以,是可以在同一时间被处理的。不过,他们的完成时间是各不相同的。integer操作的处理时间是最短的,所以最先完成。
- 即便是相同的处理类型,如果处理器有多个issue handler的话,也是可以并行处理的
Memory Ordering
Out-Of-Order Memory
也是为了提高性能,cpu或者设备访问内存空间的顺序也可能被编译器或者硬件改变,比如:
- Optimized to minimize iterations by the compiler
- Example) Repeat 100 times to store 1 to address A -> Store 1 to address A once
- Architecture optimizes by using output buffers to reorder memory access
- Example) Collect and process access to addresses belonging to the cache line if possible
Example 1)
- If address A and address B are on the same cache line, they should be grouped together if possible (figure below)
- I tried to save in the order A, X, and B, but it was changed to the order A, B, and X
- Since there are no operations between A, X, and B addresses, the architecture does not know the dependency, so the order can be changed.

Example 2)
当使用设备的地址寄存器和数据寄存器来读取设备内容时,我本来想,
- 向设备地址寄存器写入地址(store操作)
- 从设备数据寄存器读取数据(load操作)
不过,cpu可能并不知道这个store和load之间是有依赖关系的,这个order是可能被改变的。
Compiler Barrier
Compiler Barrier 用于防止编译器省略、简化或改变代码执行顺序等优化措施。
- C Functions
- barrier()
- barrier() restricts previous and subsequent memory accesses from being reordered by the compiler's optimizations.
- barrier()
- Compiler Directives
- __volatile__
- Use __volatile__ to limit the compiler's optimization
- When used before a variable
- Limit optimization for the use of variables.
- It prevents the compiler from placing variables in registers for speedup.
- Limit optimization for the use of variables.
- When used before function
- Limit all optiomization in the function.
- __volatile__
- READ_ONCE() or WRITE_ONCE()
- Use volatile internally. In the case of the DEC alpha architecture, it also includes an architecture barrier.
- This is fine for single-threaded code, but it prevents optimizations that can be problematic in code with concurrency.
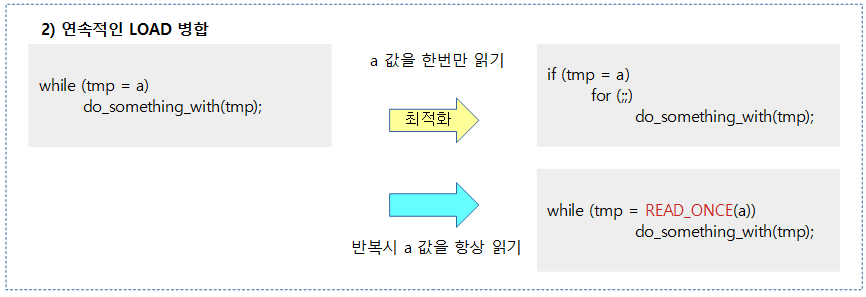
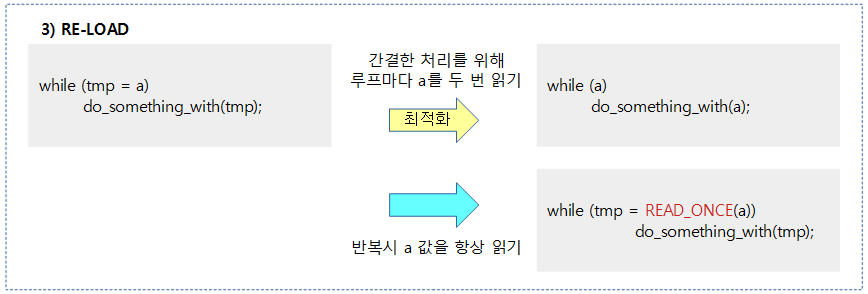
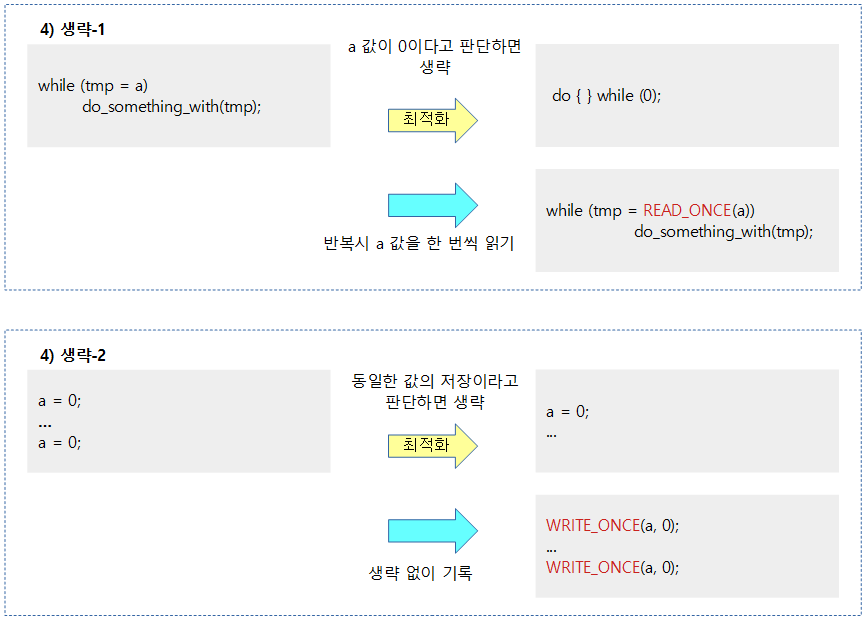
When you need a compiler barrier


Dependency Barriers
LOAD-LOAD
- The compiler does not support control (if) dependencies between LOAD operations, so it can be predicted by optimization, so the order between the two LOADs cannot be guaranteed.
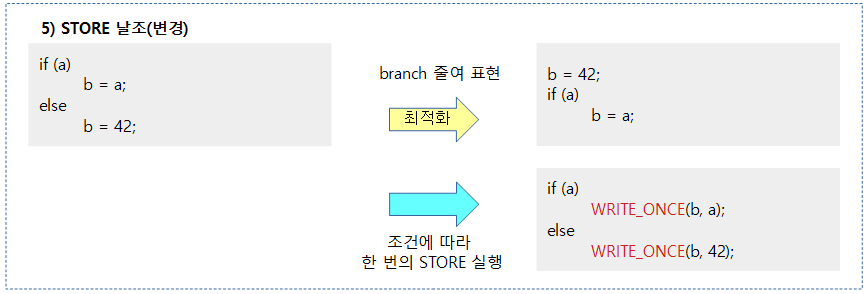
STORE
- STORE operations are not performed predictably by the compiler, so they ensure order with other LOADs and STOREs. Still, it doesn't work as a conditional dependency barrier.
Architecture Memory Barrier
内存屏障分几个level:inner-shareable、outer-shareable、full-system等。不同level的作用范围不同,对性能的影响也不同:
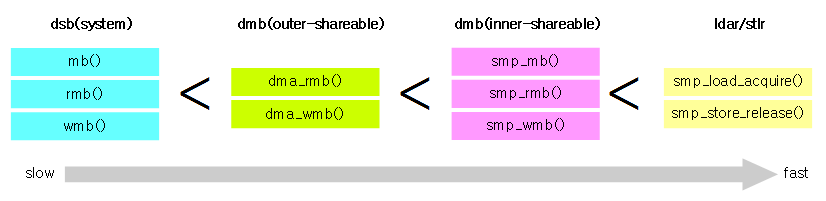
Mandatory barrier
It prevents the architecture from omitting, abbreviating, or changing the order of access when accessing shared memory. It provides four basic types of APIs:
- mb()
- General Memory Barrier Type
- Based on the command, the order of the previous Load/Store operation and the subsequent Load/Store operation is guaranteed.
- Implementation according to architecture
- dsb, sync, mfence, …
- On ARM, the dsb() command is used to perform some additional synchronization in addition to the write buffer flush.
- In the case of ARM64, the dsb(sy) command is used to perform some additional synchronization in addition to the write buffer flush.
- rmb()
- Read Memory Barrier Type
- Based on this command, the order of the previous load operation and the subsequent load operation (Ordering) is guaranteed.
- wmb()
- write memory barrier type
- Based on this command, the order of the previous store operation and the subsequent store operation is guaranteed.
- read_barrier_depends()
- Data Dependency Barrier Types
- If the value read by the Load operation is passed as a result and used for the next Load operation, the order between the atomic Load operations is guaranteed.
- It is a little faster than rmb().
- ARM, ARM64, and most architectures do not require any code because they check for simple data dependencies inside them, but only the DEC alpha architecture implements this code.
In addition, there are two implicit one-way barrier types: (More on that later.)
- ACQUIRE operations
- The one-way barrier guarantees the memory manipulation order after the ACQUIRE operation.
- It is used in LOCK operations and smp_load_acquire() and smp_cond_acquire().
- smp_load_acquire()
- Based on this command, the order of subsequent Read/Write operations is guaranteed.
- RELEASE operations
- A one-way barrier guarantees the memory manipulation order before the RELEASE operation.
- UNLOCK operations and smp_store_release().
- smp_store_release()
- Based on this command, the order of the previous Read/Write operations is guaranteed.
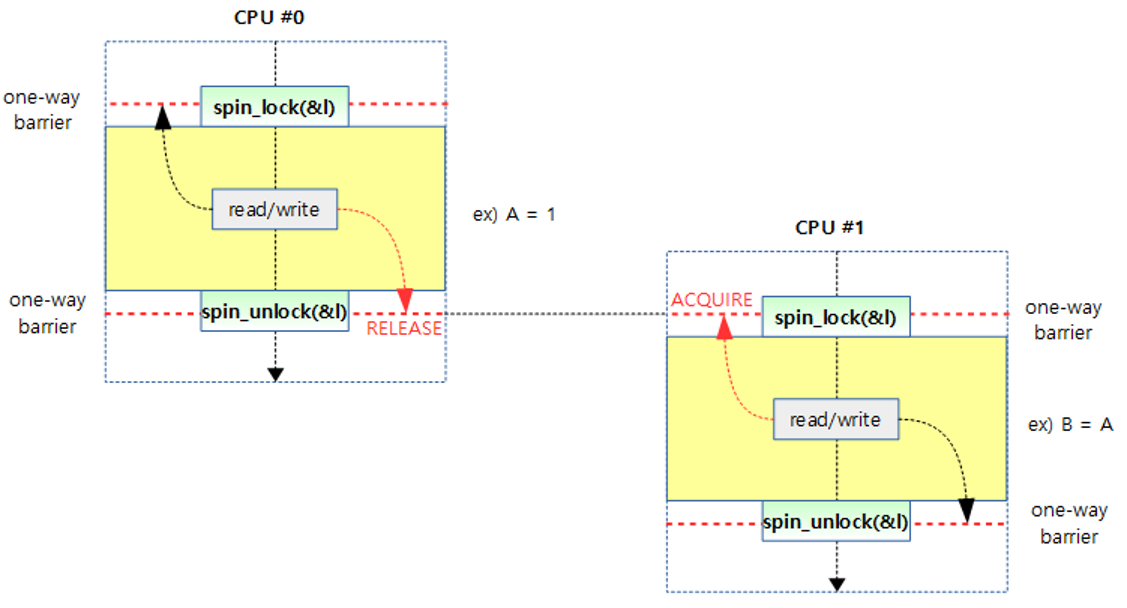
The following figure shows how the ACQUIRE and RELEASE operations are implemented in a spinlock.
- Since the A value is not reordered after RELEASE, it can be seen that the A value is safely stored in B.
Device Support Barrier
For devices, we added commands to Kernel v3.19-rc1 that can be shared to the Outer Share region, which is lighter than RMB() and WMB() and heavier than SMP-enabled barriers.
- dma_rmb()
- It is the same as rmb(), but it is a shared memory that not only the CPU but also devices in the outer area access.
- dma_wmb()
- WMB(), but it is a shared memory that not only the CPU but also the device accesses.
SMP Support Barrier
In the inner share area of the SMP system, the following functions are used to ensure memory consistency between cores and devices that use cache consistency together.
- smp_mb()
- Based on this command, the order of the previous Read/Write operation and the subsequent Read/Write operation is guaranteed.
- smp_rmb()
- Based on this command, the order of the previous Read operation and the subsequent Read operation is guaranteed.
- smp_wmb()
- Based on this command, the order of the previous write operation and the subsequent write operation is guaranteed.
ldar/stlr指令
The following figure shows the difference between a two-way barrier and a one-way barrier in the ARMv8 architecture.
- When implementing lock() and unlock(), you can use a one-way barrier pair to improve performance rather than using two two-way barriers.
- ARMv7 does not support these commands, so it is implemented using the existing smp_mb() command.
- In ARMv8, two of these one-way barrior commands are composed into a pair.
- smp_load_acquire to LDAR, a one-way barrier()
- smp_store_release to the unidirectional barrier STLR ()

Barriers of ARMv7 & ARMv8
- Three insts: DMB, DSB, ISB
DMB(Data Memory Barrier)
- The following two arguments can be used in combination to separate memory access before and after the DMB command as a data memory barrier.
- shareablity domain
- ish: inner-shareable
- osh: outer-shareable
- sy: system-shareable
- access types
- ld: load
- st: store
- shareablity domain
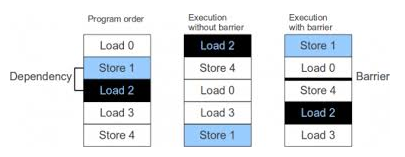
- Wait for all delayed load/store to complete (flush).
- Example) For the sake of efficiency, you can change the order of R,W,R,W,W,W → R,W,R,W,W to prevent this.
DSB(Data Synchronization Barrier, called DWB)
- It is much slower than DMB because it stops and waits for additional commands to run until the following items (including what DMB commands do) are completed. The use of arguments is the same as that of DMB.
- Instruction Cache and Data Cache Operations
- Branch predictor cache flush
- Handling of Deferred Load/Store Commands <- What DMB Commands Do
- TLB cache manipulation completed
ISB(Instruction Synchronization Barrier)
- The moment an ISB command is activated, the next command will follow in due to the pipeline, and it will discard all of them. (Pipeline Flush) Due to the Out of order execution function, there is a possibility that the command fetched after it will be executed first, which may cause problems. In a routine where the priority of the two commands must be clearly distinguished, an ISB is executed between the two commands to clearly ensure the order in which the two commands are executed.
- ARMv7 supports ISBs, but other architectures may not support ISBs. In this case, to achieve an effect similar to emptying the pipeline, you can use commands such as nop or mov a0 or a0 to ensure that there is no problem at the moment when the execution of the command changes. It also induces dependency in the order of memory references, so that certain routines have no choice but to be executed in-order.
- Usage Case
- Real-time code changes
- If the cached command is re-executed after the code part is changed, the problem will occur, so the ISB should be used in this case as well. (JIT behaves as it changes commands)
- MMU on/off
- ISB commands are also used at the time of MMU switching.
- Out of Order Execution: If the CPU is using a parallel pipeline that supports Out of Order Execution (supported from the ARMv6 architecture, but most products are available from ARMv7), this is to prevent the next command from being executed first and the address reference may be a problem before or after the MMU state changes.
- Real-time code changes
Code Analysis
Armv8
include/asm-generic/barrier.h
#define smp_mb() __smp_mb()
#define smp_rmb() __smp_rmb()
#define smp_wmb() __smp_wmb()
arch/arm64/include/asm/barrier.h
#define __smp_mb() dmb(ish)
#define __smp_rmb() dmb(ishld)
#define __smp_wmb() dmb(ishst)
#define mb() dsb(sy)
#define rmb() dsb(ld)
#define wmb() dsb(st)
#define dma_mb() dmb(osh)
#define dma_rmb() dmb(oshld)
#define dma_wmb() dmb(oshst)
#define sev() asm volatile("sev" : : : "memory")
#define wfe() asm volatile("wfe" : : : "memory")
#define wfi() asm volatile("wfi" : : : "memory")
#define isb() asm volatile("isb" : : : "memory")
#define dmb(opt) asm volatile("dmb " #opt : : : "memory")
#define dsb(opt) asm volatile("dsb " #opt : : : "memory")
The instructions for each ARM architecture were compared as shown in the following figure.

smp_load_acquire()
include/asm-generic/barrier.h
#ifndef smp_load_acquire
#define smp_load_acquire(p) __smp_load_acquire(p)
#endif
arch/arm64/include/asm/barrier.h
#define __smp_load_acquire(p) \
({ \
union { __unqual_scalar_typeof(*p) __val; char __c[1]; } __u; \
typeof(p) __p = (p); \
compiletime_assert_atomic_type(*p); \
kasan_check_read(__p, sizeof(*p)); \
switch (sizeof(*p)) { \
case 1: \
asm volatile ("ldarb %w0, %1" \
: "=r" (*(__u8 *)__u.__c) \
: "Q" (*__p) : "memory"); \
break; \
case 2: \
asm volatile ("ldarh %w0, %1" \
: "=r" (*(__u16 *)__u.__c) \
: "Q" (*__p) : "memory"); \
break; \
case 4: \
asm volatile ("ldar %w0, %1" \
: "=r" (*(__u32 *)__u.__c) \
: "Q" (*__p) : "memory"); \
break; \
case 8: \
asm volatile ("ldar %0, %1" \
: "=r" (*(__u64 *)__u.__c) \
: "Q" (*__p) : "memory"); \
break; \
} \
(typeof(*p))__u.__val; \
})
smp_store_release()
include/asm-generic/barrier.h
#ifndef smp_store_release
#define smp_store_release(p, v) __smp_store_release(p, v)
#endif
arch/arm64/include/asm/barrier.h
#define __smp_store_release(p, v) \
do { \
typeof(p) __p = (p); \
union { __unqual_scalar_typeof(*p) __val; char __c[1]; } __u = \
{ .__val = (__force __unqual_scalar_typeof(*p)) (v) }; \
compiletime_assert_atomic_type(*p); \
kasan_check_write(__p, sizeof(*p)); \
switch (sizeof(*p)) { \
case 1: \
asm volatile ("stlrb %w1, %0" \
: "=Q" (*__p) \
: "r" (*(__u8 *)__u.__c) \
: "memory"); \
break; \
case 2: \
asm volatile ("stlrh %w1, %0" \
: "=Q" (*__p) \
: "r" (*(__u16 *)__u.__c) \
: "memory"); \
break; \
case 4: \
asm volatile ("stlr %w1, %0" \
: "=Q" (*__p) \
: "r" (*(__u32 *)__u.__c) \
: "memory"); \
break; \
case 8: \
asm volatile ("stlr %1, %0" \
: "=Q" (*__p) \
: "r" (*(__u64 *)__u.__c) \
: "memory"); \
break; \
} \
} while (0)

















 2232
2232

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









