










目录
一、双列集合的介绍
不同于单列集合,双列集合顾名思义是有两个元素的,说是元素,又有点不大准确。就有有一对键值对,就是有一个标志的值和这个标志的值所对应的值。也就是在算法中我们常说的标志数组吧。它和单列集合一样都是储存数据的容器
HashMap:无序,不重复,无索引
LinkedHashMap:有序,不重复,无索引
TreeMap:
综上所述Map是不重复的,但是这里的不重复是键不能重复,但是值是可以重复的。
二、Map的使用
1:Map中常见的API
V put(k key,V value) 添加元素
V remove(Object key) 根据键删除所对应的元素
void clear() 清空所有的键值对元素
boolean containsKey(Object key) 判断集合是否包含指定的键
boolean containsValue(Object value) 判断集合是否包含指定的值
boolean isEmpty() 判断集合是否为空
int size() 集合的长度也就是集合中的键值对个数这里对于一些细节的方法我会详细说说,其他没说的方法就按照类型操作即可。
(1)put方法
对于put方法的返回值,如果添加的数据的键再Map容器中以及存在了,那么新添加的数据就会覆盖,而返回值就是被覆盖的键所对应的值。如果并没有覆盖,返回值就是null。
package article;
import java.util.Arrays;
import java.lang.reflect.Array;
import java.util.*;
public class so {
public static void main(String[] args) {
Map<String,String> s=new HashMap<>();
String v1=s.put("jkjk", "123");
System.out.println(v1);
s.put("opo", "234");
s.put("yyyy", "");
String v2=s.put("opo", "[[[[");
System.out.println(v2);
System.out.println(s);
}
}

(2)remove方法
remove方法删除,其中接受的参数是你想要删除的所对应的键,同时它也会有返回值,返回值就是你所删除的对应的值。
package article;
import java.util.Arrays;
import java.lang.reflect.Array;
import java.util.*;
public class so {
public static void main(String[] args) {
Map<String,String> s=new HashMap<>();
String v1=s.put("jkjk", "123");
s.put("opo", "234");
s.put("yyyy", "");
String v2=s.put("opo", "[[[[");
System.out.println(s);
String v3=s.remove("opo");
System.out.println(v3);
System.out.println(s);
}
}

2:Map的遍历
(1)通过键找值的方式遍历
package article;
import java.util.Arrays;
import java.lang.reflect.Array;
import java.util.*;
public class so {
public static void main(String[] args) {
Map<String,String> s=new HashMap<>();
String v1=s.put("jkjk", "123");
s.put("opo", "234");
s.put("yyyy", "");
String v2=s.put("opo", "[[[[");
System.out.println(s);
Set<String> ss=s.keySet();//获取到键并放入ss集合
for(String k:ss) {
String value=s.get(k);//通过键获取值
System.out.println("键="+k+",值="+value);
}
}
}

(2)通过键值对对象遍历
这种遍历方式是将键值对当做一个整体进行遍历,每次获取每个键值对对象中的键和值。
package article;
import java.util.Arrays;
import java.lang.reflect.Array;
import java.util.*;
public class so {
public static void main(String[] args) {
Map<String,String> s=new HashMap<>();
String v1=s.put("jkjk", "123");
s.put("opo", "234");
s.put("yyyy", "");
String v2=s.put("opo", "[[[[");
Set<Map.Entry<String,String> > ss=s.entrySet();//获取键值对对象,并将其放入集合中
for(Map.Entry<String, String> oo:ss) {
String key=oo.getKey();//获取键值对对象中的键
String value=oo.getValue();//获取键值对对象中的值
System.out.println("键="+key+" 值="+value);
}
}
}
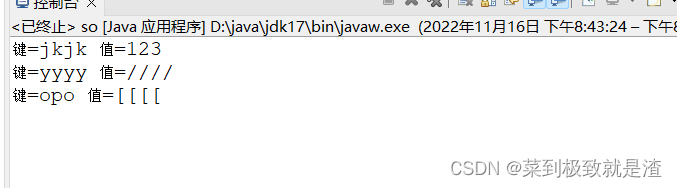
(3)Lambda表达式遍历
package article;
import java.util.Arrays;
import java.util.function.BiConsumer;
import java.lang.reflect.Array;
import java.util.*;
public class so {
public static void main(String[] args) {
Map<String,String> s=new HashMap<>();
String v1=s.put("jkjk", "123");
s.put("opo", "234");
s.put("yyyy", "");
String v2=s.put("opo", "[[[[");
s.forEach(new BiConsumer<String,String>(){
@Override
public void accept(String key, String value) {
// TODO 自动生成的方法存根
System.out.println("键="+key+" 值="+value);
}
});
System.out.println("Lamda表达式再简化");
s.forEach((String t, String u)-> {
// TODO 自动生成的方法存根
System.out.println("键="+t+" 值="+u);
}
);
}
}

三、双列集合的使用
1:HashMap
HashMap也HashSet一样,都是基于哈希表的结构,特点都是无序,不重复,无索引。
并且以来HashCode方法和equals方法保证键的唯一。如果键存储的是自定义对象,需要重写HashCode和equals方法,如果是值存储自定义对象,则不需要重写HashCode和equals方法。
具体我们可以举两个例子感受下
(1)定义一个学生对象,键存学生对象,值存储籍贯,姓名和年龄相同视为同一学生
package article;
import java.util.Objects;
public class student {
String name;
int age;
public student(String name,int age) {
this.age=age;
this.name=name;
}
public void setname(String name) {
this.name=name;
}
public void setage(int age) {
this.age=age;
}
public String getname() {
return name;
}
public int getage() {
return age;
}
@Override
public int hashCode() {
return Objects.hash(age, name);
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
student other = (student) obj;
return age == other.age && Objects.equals(name, other.name);
}
}
package article;
import java.util.Arrays;
import java.util.function.BiConsumer;
import java.lang.reflect.Array;
import java.util.*;
public class so {
public static void main(String[] args) {
Map<student,String> s=new HashMap<>();
student s1=new student("张三",10);
student s2=new student("王五",20);
student s3=new student("赵烈",30);
student s4=new student("王五",20);
s.put(s1,"安徽");
s.put(s2, "江苏");
s.put(s3, "浙江");
s.put(s4, "天津");
Set<Map.Entry<student,String>> ss=s.entrySet();
for(Map.Entry<student, String> gg:ss) {
student key=gg.getKey();
String value=gg.getValue();
System.out.println("键中的名字="+key.getname()+"键中的年龄="+key.getage()+" 值中的籍贯="+value);
}
}
}

(2)ABCD四个景点,现在有80人,每个人只能去其中一个景点,统计每个景点去的人数,并输出去的人数最多的景点。
package article;
import java.util.Arrays;
import java.util.function.BiConsumer;
import java.lang.reflect.Array;
import java.util.*;
public class so {
public static void main(String[] args) {
//80人去的景点,我们用随机数来搞
Random r=new Random();
String[] a= {"A","B","C","D"};
ArrayList<String> s=new ArrayList<>();//存储的是80每个人去的景点
for(int i=0;i<80;i++) {
int index=r.nextInt(4);
s.add(a[index]);
}
//现在每个人去的景点已经添加到s链表中
Map<String,Integer> h=new HashMap<>();
for(String place:s) {
if(h.containsKey(place)) {
//地方已经存在
int count=h.get(place);
count++;
h.put(place, count);
}
else {
//第一个人去
h.put(place,1);
}
}
int ma=0;
//遍历输出
Set<Map.Entry<String,Integer>> gg=h.entrySet();
for(Map.Entry<String, Integer> oo:gg) {
String key=oo.getKey();
int value=oo.getValue();
if(ma<value) {
ma=value;
}
System.out.println("去"+key+"的人数="+value);
}
//求最大人数
System.out.println("最大人数="+ma);
}
}

2:LinkedHashMap
LinkedHashMap特点:有序,不重复,无索引。
注意不重复是键不可重复,值是可以重复的。同时它的底层实现结构是哈希表和双向链表。
package article;
import java.util.Arrays;
import java.util.Map.Entry;
import java.util.function.BiConsumer;
import java.lang.reflect.Array;
import java.util.*;
public class so {
public static void main(String[] args) {
Map<String,Integer> s=new LinkedHashMap<>();
s.put("909", 100);
s.put("sd", 1);
s.put(">>>>", 100);
Set<Map.Entry<String, Integer>> ss=s.entrySet();
for(Entry<String, Integer> oo:ss) {
String key=oo.getKey();
int value=oo.getValue();
System.out.println("键="+key+" 值="+value);
}
}
}

3:TreeMap
TreeMap的特点:可排序,不重复,无索引。默认按照键的从小到大进行排序,也可按照自己定义的规则进行排序。对于它的排序与TreeSet也是一样的,有两种方法进行排序。一种是使用比较器进行排序,一种是使用Comparable接口进行排序。
(1)Comparable接口排序
这里的this表示当前添加进去的,o表示的是已经存在的。我这里是先按照年龄从小到大,年龄一样按照名字从小到大排序。大家不理解就记住this在前表示是升序(从小到大)
package article;
import java.util.Objects;
public class student implements Comparable<student>{
String name;
int age;
public student(String name,int age) {
this.age=age;
this.name=name;
}
public void setname(String name) {
this.name=name;
}
public void setage(int age) {
this.age=age;
}
public String getname() {
return name;
}
public int getage() {
return age;
}
@Override
public int compareTo(student o) {
// TODO 自动生成的方法存根
int t=this.age-o.age;
if(t==0) {
return this.name.compareTo(o.name);
}
return t;
}
}
package article;
import java.util.Arrays;
import java.util.Map.Entry;
import java.util.function.BiConsumer;
import java.lang.reflect.Array;
import java.util.*;
public class so {
public static void main(String[] args) {
Map<student,String> s=new TreeMap<>();
student s1=new student("abc",19);
student s2=new student("bnc",19);
student s3=new student("acc",19);
student s4=new student("adddd",19);
student s5=new student("nzbs",20);
student s6=new student("qqss",3);
student s7=new student("poojs",30);
s.put(s1,"安徽");
s.put(s2, "安徽");
s.put(s3, "天津");
s.put(s4, "浙江");
s.put(s5, "安徽");
s.put(s6, "天津");
s.put(s7, "浙江");
Set<Map.Entry<student, String>> ss=s.entrySet();
for(Map.Entry<student, String> oo:ss) {
student key=oo.getKey();
String value=oo.getValue();
System.out.println("键中名字="+key.getname()+" 键中年龄="+key.getage()+" 值="+value);
}
}
}

(2)Comparator比较器排序
这里我将排序规则修改了下,按照年龄从大到小排序,如果年龄相同,则按照名字从大到小进行排序。这里大家不理解,就可以这样理解o1在前就是升序,o2在前就是降序。(嗯,死记硬背吧,哈哈哈)
package article;
import java.util.Arrays;
import java.util.Map.Entry;
import java.util.function.BiConsumer;
import java.lang.reflect.Array;
import java.util.*;
public class so {
public static void main(String[] args) {
Map<student,String> s=new TreeMap<>(new Comparator<student>() {
@Override
public int compare(student o1, student o2) {
// TODO 自动生成的方法存根
int t=o2.age-o1.age;
if(t==0) {
return o2.name.compareTo(o1.name);
}
return t;
}
});
student s1=new student("abc",19);
student s2=new student("bnc",19);
student s3=new student("acc",19);
student s4=new student("adddd",19);
student s5=new student("nzbs",20);
student s6=new student("qqss",3);
student s7=new student("poojs",30);
s.put(s1,"安徽");
s.put(s2, "安徽");
s.put(s3, "天津");
s.put(s4, "浙江");
s.put(s5, "安徽");
s.put(s6, "天津");
s.put(s7, "浙江");
Set<Map.Entry<student, String>> ss=s.entrySet();
for(Map.Entry<student, String> oo:ss) {
student key=oo.getKey();
String value=oo.getValue();
System.out.println("键中名字="+key.getname()+" 键中年龄="+key.getage()+" 值="+value);
}
}
}
提醒大家,排序排序,这里的排序都是按照键来排序,千万不要扯到值上了。
















 1079
1079











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











