







论文链接:https://arxiv.org/pdf/2110.06161.pdf
论文代码:https://github.com/jackyjsy/SAM-SLR-v2
摘要
- 手语通常以快速而精细的手势、身体姿势甚至面部表情的动作来展示。
- 当前的手语识别(SLR)方法通常通过深度神经网络提取特征,由于数据有限且噪声大,容易出现过拟合问题。
- 近年来,基于骨骼的动作识别由于其主体不变性和背景不变性的特性而受到越来越多的关注,而基于骨骼的SLR由于缺乏手部注释,仍处于探索阶段。
- 一些研究人员尝试使用离线手部姿势跟踪器来获取手部关键点,并通过循环神经网络帮助识别手语。然而,它们都还没有超过基于rgb的方法。
- 本文提出了一种新型的带有全局合成模型(Global Ensemble Model,GEM)的骨架感知多模式框架(Skeleton Aware Multi-modal Framework),用于独立的手语识别(SAM-SLR-v2),来提高识别率。
- 具体来说,我们提出了一个手语图卷积利用网络(SL-GCN)来模拟骨架关键点的嵌入动态和可分离时空卷积
网络(SSTCN)来利用骨架特征。 - 基于骨骼的预测被提议的后期融合GEM与其他RGB和深度模式融合,以提供全局信息,并做出可靠的SLR预测。
- 在三个isolated SLR 数据集上的实验证明了我们的建议SAM-SLR-v2框架非常有效,实现了最先进的性能和显著的效果。
1. 简介
-
在这项工作中,我们关注的是isolated SLR任务。我们提出了一个骨架感知的多模态SLR框架集成模型(SAM-SLR-v2),以探索基于骨骼的SLR的潜力,并与其他模式融合RGB和RGB- d场景进一步提高识别率。
-
具体地说,我们设计了一种新的时空骨架图,利用预训练的全身姿态估计器提取全身关键点。
-
然后,我们提出了一个多流手语图卷积网络(SL-GCN)来模拟嵌入式动态。
-
为了充分利用全身关键点的信息,我们提出了一种新方法可分离时空卷积网络(SSTCN)研究全身骨骼特征。
-
此外,对动作识别的研究表明,来自不同模式的数据可以相互补充,提供潜在相关性的知识,并进一步提高最终的性能。
-
尽管我们可以简单地将所有模式的预测相加以获得更高的准确性,但我们希望有一种方法能够以数据驱动的方式为每个模式调整最佳权重。因此,我们提出了一种全局集成模型(Global Ensemble Model,GEM)来自动学习多模态集成,提高整体识别率。
-
主要贡献可以概括如下:
(1)使用预训练的全身姿态估计器和graph reduction,构建了全新的2D和3D的骨架图来进行SLR,无需额外的注释工作。
(2)提出了一种新的SL-GCN来建模骨架图中的运动。据我们所知,这是利用2D/3D全身骨骼图来解决SLR任务的第一次成功超越了基于rgb的方法的尝试。
(3)提出了一种新的SSTCN来进一步挖掘全身骨骼特征。与传统的三维卷积算法相比,该算法的精度有明显提高。
(4)提出了一个集成模型GEM的基于RGB和RGB-D的SLR,可以从七种模式中学习权重,并在三个isolated SLR数据集上获得最先进的性能,具有显著的性能优势。
-
与我们的SAM-SLR版本相比,我们做了以下改进:
(1)引入了一种新的模式Keypoint3D,它考虑空间中的三维坐标并处理遮挡问题。提高了RGB-D集成的整体识别率。
(2)提出了一种新的基于学习的后期融合集成方法GEM,该方法在多模态集成中获得了更高的识别率,并且节省了权重调优的工作量。
(3)AUTSL数据集的测试标签已经发布,因此我们将性能从验证集更新到测试集。
(4)除了挑战数据集(AUTSL),我们还报告了我们在另外两个大规模数据集上的性能(即SLR500和WLASL2000)与最先进的方法进行比较。
(5)我们更新了我们的数据,提供了更多的模型细节,分析了集成灵敏度,并讨论了具有挑战性的情况,这些可能会启发未来SLR的研究.
2. 方法
2.1 SAM-SLR-v2框架概述
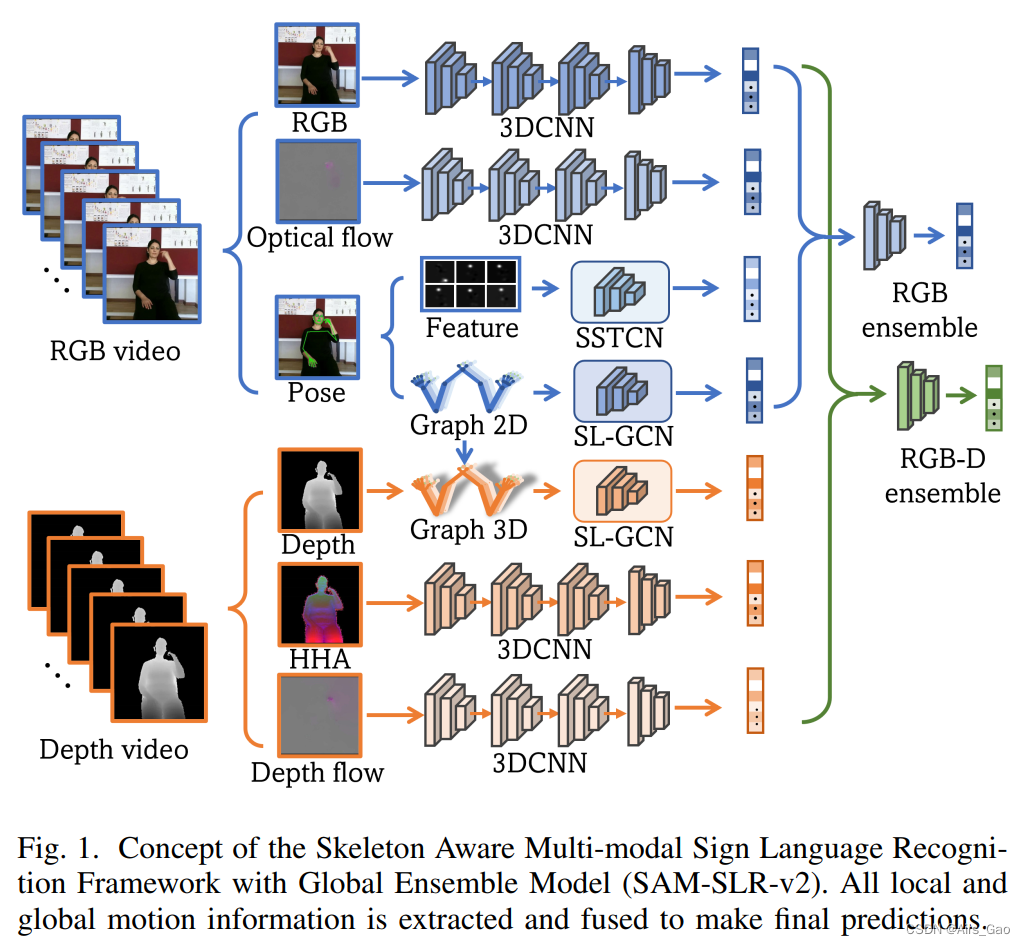
- SAM-SLR-v2整体框架如图1所示。
- 在提出的框架中考虑了从RGB和深度视频处理的七种模式。
- 采用SL-GCN、SSTCN和3DCNN三种不同的体系结构从七种模态中提取特征,并独立地对手语进行预测。
- 后期融合集成模型(即GEM)从所有模式中进行预测,并在RGB和RGB- d情景中输出最终预测。
2.2 SL-GCN for Skeleton Keypoints
(1)Graph Construction and Reduction.
-
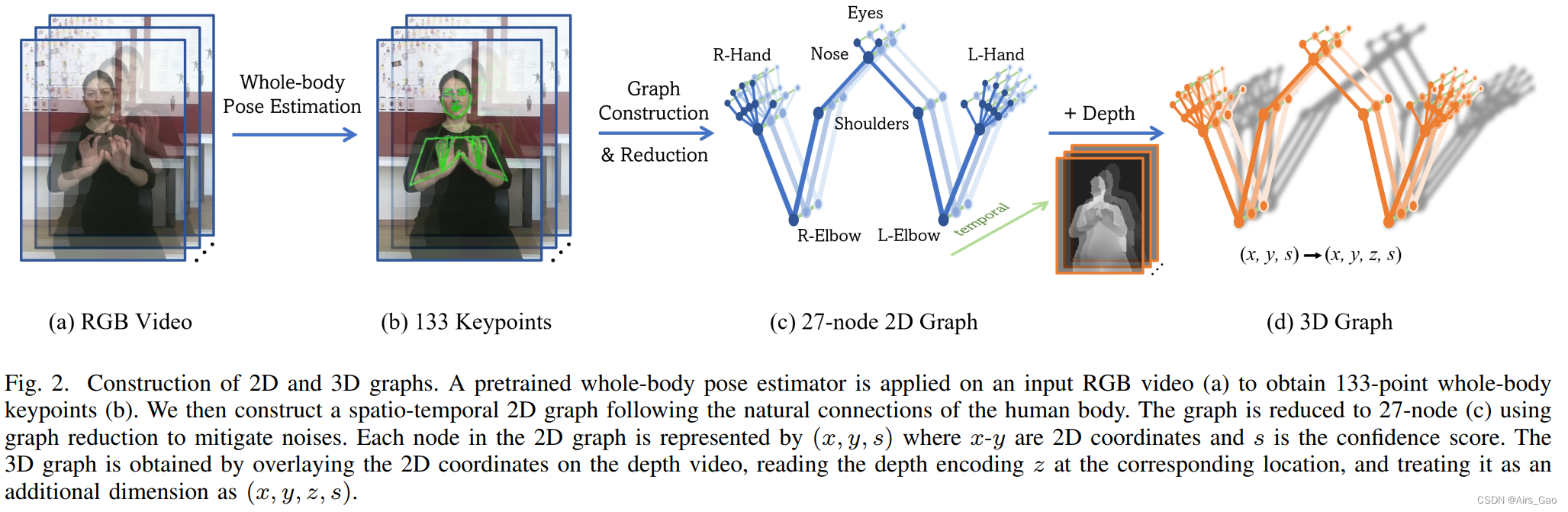
由于手势在表演手语中起着至关重要的作用,我们使用一个经过全身注释预处理的姿势估计器来预测全身关键点,其中包括脸、身体、手和脚的133个landmarks。
-
然后根据人体的自然连接,将每对相邻的关键点连接起来,构建出一个spatial 2D graph。
-
通过在时间维度中连接所有节点自身,该图进一步扩展为spatio-temporal graph。
-
节点(包括133个全身节点)的数学表达为:
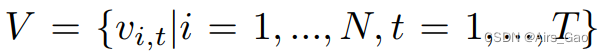
-
它们的邻接矩阵(adjacent matrix)A定义为:
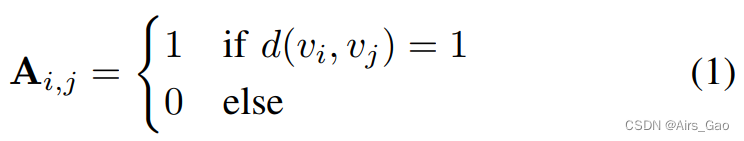
-
然而,与基于骨骼的动作识别中使用的约17个节点的图相比,全身骨骼图包含过多的节点和边缘,引入了高水平的意外噪声。
-
此外,如果两个节点之间的距离太远(即节点之间有很多节点),探究它们之间的相互作用是不准确的。
-
我们的实验表明,简单地使用全身骨架图会导致较低的准确性。
-
因此,根据我们对GCN激活视频和可视化的观察,我们对全身骨架图进行了graph reduction ,将133个节点裁剪到27个节点。
-
得到的图由上半身的七个节点(鼻子、眼睛、肩膀和肘部)和每只手的十个节点组成,如图2©所示。
-
graph reduction导致更快的模型收敛和显著提高识别率。
-
2D graph中的每个节点用(x;y;s)其中x-y为2D坐标,s为置信度分数。
-
当深度信息可用时,我们通过在关键点位置x-y处读取相应的深度z来构造一个3D图,并将其作为一个附加维度(x;y;z;s),如图2(d)所示。
(2)Graph Convolution
- 我们采用spatio-temporal graph convolution with spatial partitioning strategy和空间划分策略来捕获全身骨架图中嵌入的动态。
- 将spatial graph convolution实现为:

其中,A表示体内连接的邻接矩阵,I表示自连接的单位矩阵,D表示(A + I)的对角度,W为卷积的可训练权值。 - 为了执行temporal graph convolution,我们在时间维上实现一个标准的二维卷积,其内核大小为k_t×1作为感受野。
- 在解耦GCN层,为了进一步提高模型容量,将提取的特征分成G组,每组都有其可训练的邻接矩阵A。然后我们将所有组的输出连接到一起作为输出特征。
(3)Multi-stream SL-GCN.
- 我们发现对于手语识别,1st-order coordinates (joints), 2nd-order vector (bone vector), and their motion vectors也值得研究,如图3(a)所示。
- 根据人体的自然连接,我们生成从起始关节到结束关节的骨向量。因此,bone stream用tree graph表示,其中nose作为根节点。数学上,起始和结束关节可以表示为:
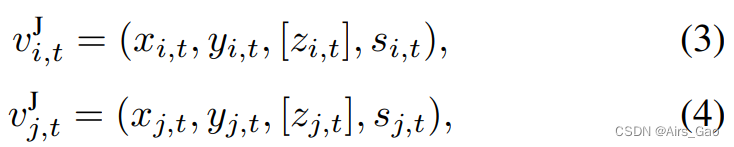
其中(x,y,[z],s)表示二维坐标、可选深度和置信度得分。 - 骨向量vB由公式4减去公式3得到
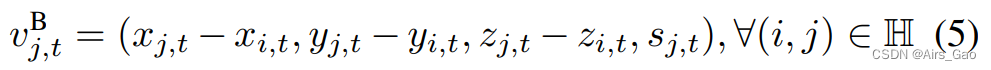
其中H组包含人体所有的自然连接。 - 运动流是通过减去相邻帧之间的差来获得的。关节运动向量vJM 和骨骼运动向量vJM表示为:
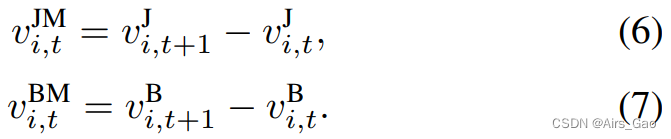
- 我们分别训练每个流,将它们的预测乘以指定的权重,并将结果相加作为最终的预测。
(4)SL-GCN Structure
- 提出的SL-GCN的结构如图3(b)所示。
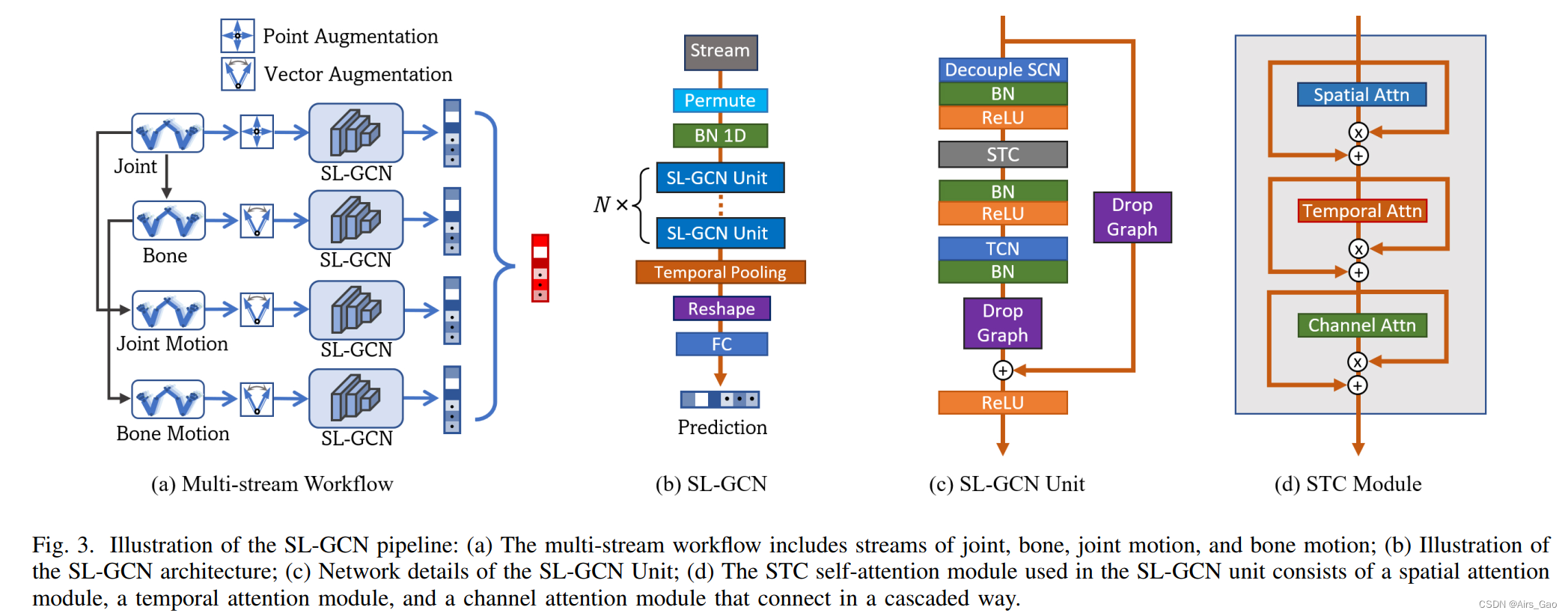
- 输入流在输入到N个SL-GCN单元实例进行时空图卷积之前进行排列(permuted)和归一化处理(normalized )。
- 然后对结果特征的时间维度应用average pooling。
- 结果被重塑(reshaped )并输入一个fully connected layer进行分类。
- 提出的SL-GCN单元如图3©所示。
- 我们发现深度图模型在视频分类任务中更容易过拟合,而普通的dropout层在GCNs中效果很差。
- 提出用一个解耦的空间卷积层(DecoupleSCN)来构造基本的SL-GCN单元,以缓解过拟合。
- 我们还引入了STC(空间、时间和通道)自注意机制。图3(d), STC模块由空间注意、时间注意和通道注意模块级联组成。
- 在实验中,我们在提出的SL-GCN中使用了N = 10个这样的SL-GCN单元。
2.3 SSTCN for Skeleton Features
- 我们提出了一个SSTCN模型,除了利用关键点坐标外,还利用全身特征。
- 从ResNet2+1D中可以了解到,通过将网络分解为时间部分和空间部分,可以进一步提高动作识别模型的性能。
- 因此,我们将SSTCN模型分为四个阶段,从不同的维度处理特征。
- pipeline如图4所示:
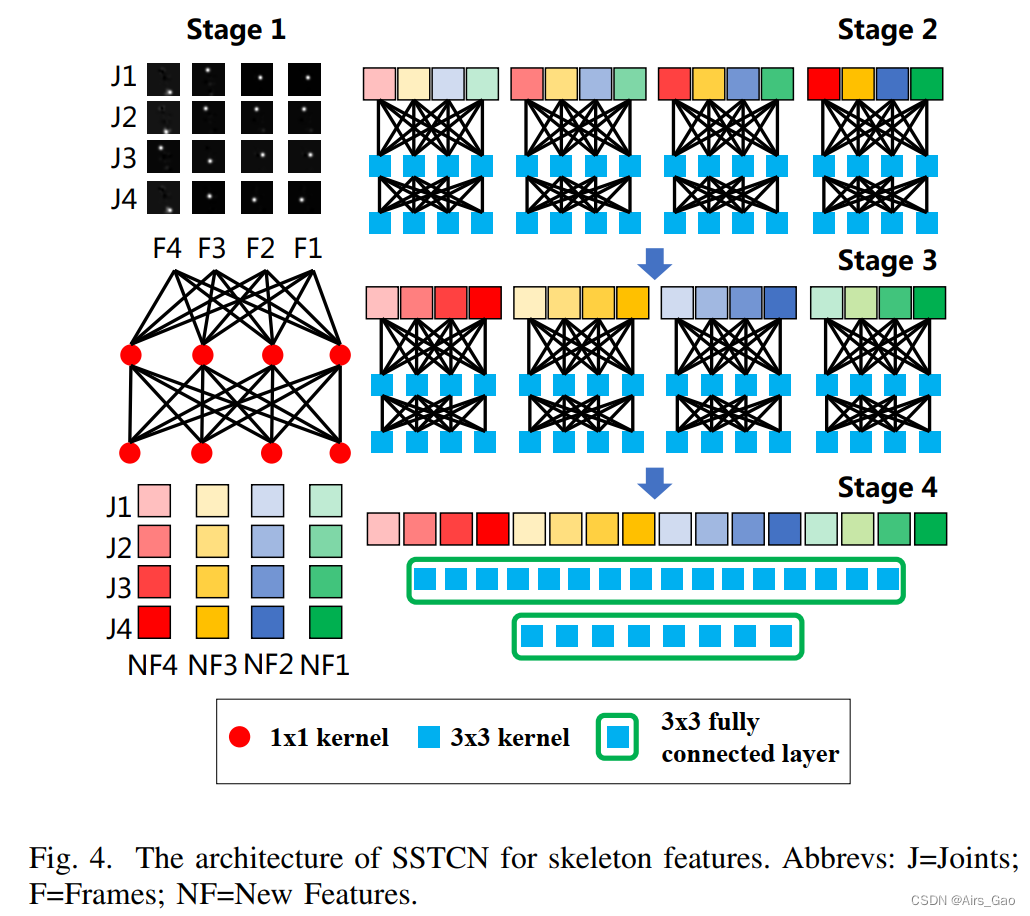
- 我们保存了33个关键点的特征,其中1个鼻子关键点,4个嘴巴关键点,6个上半身关键点,和姿势估计器argmax运算前的22个手关键点。
- 然后我们在每个视频中统一采样60帧进行SSTCN识别。保存的特征调整为24 × 24使用最大池化。
- 我们用二维可分离卷积层处理输入特征,减少了参数,易于收敛。
- 我们使用标签平滑( label smoothing )技术来避免过拟合。在数学上,标签平滑被定义为
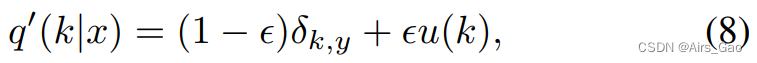
- 交叉熵损失(cross-entropy loss)被修正为:
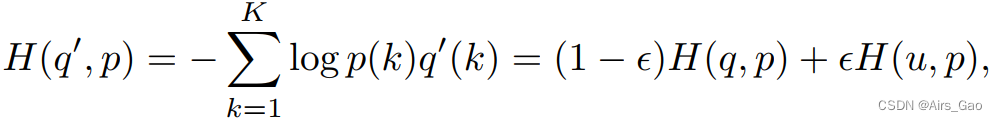
- 为了进一步提高性能,我们将所有激活替换为Swish激活函数
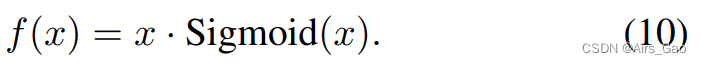
2.4 3DCNN Baselines for the Other Modalities
- 从其他方式(即,RGB帧、光流、HHA和深度流),我们使用3D cnn构建了一个简单而有效的基线。
- 我们选择ResNet2+1D在kinetics数据集上预训练的18个变体作为我们的backbone。
- 此外,为了进一步提高精度,我们在最大的SLR数据集(RGB帧的SLR500)上对模型进行了预训练。预训练使最终精度提高了约1%,提高了模型的收敛性。
- 采用公式10中描述的Swish激活。
- 为了减轻过拟合,我们应用了公式8的标签平滑技术,并应用了公式9的交叉熵损失。
2.5 Multi-modal Late-fusion Ensemble
(1)Model-free Late Fusion
- 在SAM-SLR版本,我们使用了一个简单的后期融合方法来融合来自所有模式的预测。具体地说,对于所有模式,我们保存了softmax之前最后一个完全连接层的预测。手动为所有模式分配权重,并将它们相加作为最终预测:
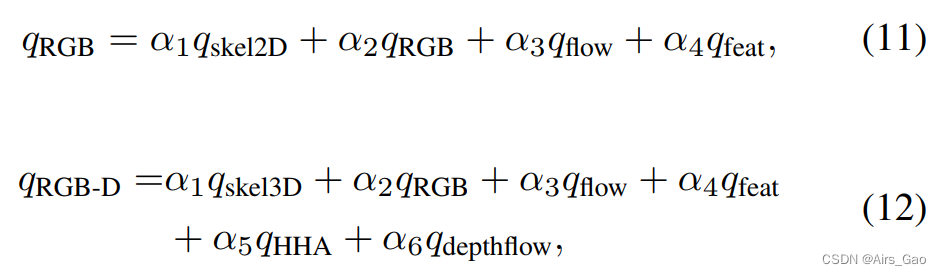
- 选择α ={1,0.9,0.4,0.4} for RGB,α = {1.0,0.9,0.4,0.4,0.4,0.1} for RGB-D 。
- 对于没有验证和测试分割的其他数据集,我们保持这些权重不变,无需进一步进行硬调优。
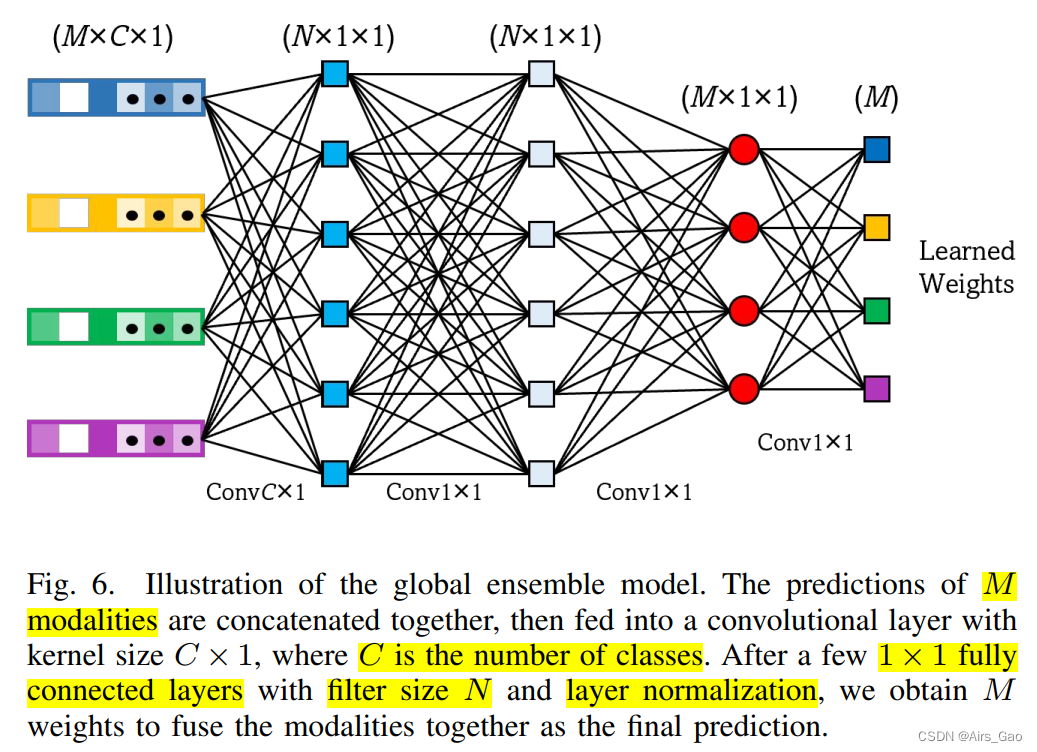
(2)Global Ensemble Model
- 由于寻找融合的最佳权重是耗时的,我们提出了一个基于学习的全局集成模型(GEM)来自动融合所有的模态,如图6所示:
- 整个过程可以描述为:
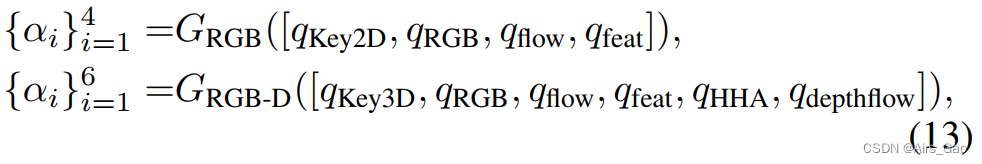
其中q表示每个模态的结果,G表示GEM的预测过程,[·]表示拼接操作。 - 模型的第一层使用global convolution有效地对模态进行下采样,第一层核为C × 1。
- 然后我们用1 × 1全连通层来预测所有模式的最终权重。
- 最后的权重分别与输入相乘,并将加权的模式相加为最终的预测。
3. 实验
3.1 数据集
- AUTSL数据集是土耳其SLR数据集,使用Kinect V2传感器采集。
- 据统计,来自20个背景的43名签名者使用了226种不同的手语。
- 该数据集包含38336个视频,分为训练、验证和测试子集。
- 我们在实验中使用了他们目前发布的平衡测试集,并报告了top-1和top-5的识别率。
-
SLR500数据集是一个用于isolated SLR的平衡中文手语数据集(有时也称为CSL isol.),包含500个单词,50个signers。
-
所有50名signers将每个单词表演5次,所以总共有125000个视频。
-
该数据集是在一个受控制的实验室环境中捕获的,具有纯色背景。
-
前36名签名者用于培训,后14名签名者用于测试。
- WLASL2000数据集是一种美国手语(American Sign Language,ASL),词汇量为2000个单词。
- 收集自119名signers表演的网络视频。
- 它包含21,083个记录条件不受约束的样本。
- 该数据集是不平衡的,每个视频的平均样本远低于上述两个数据集。
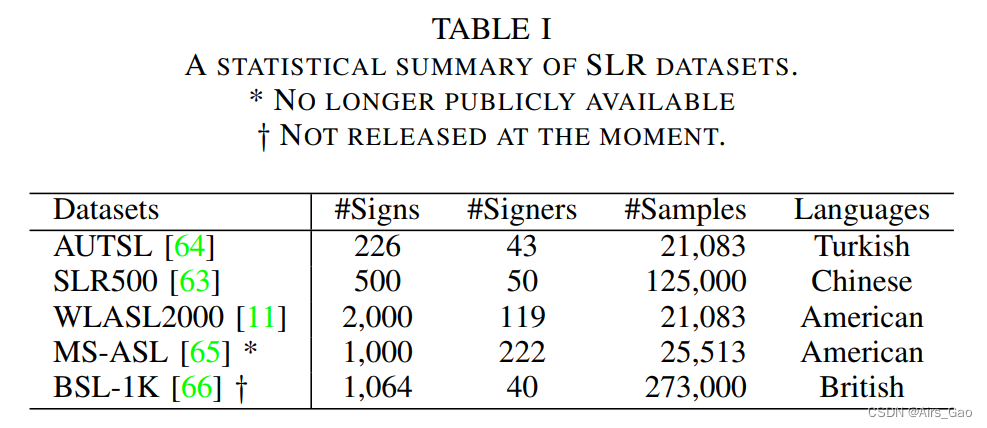
包括其它手语数据集如表1所示:
3.2 Multi-stream SL-GCN性能
- 表II报告了所提出的多流SL-GCN的top-1和top-5识别率。
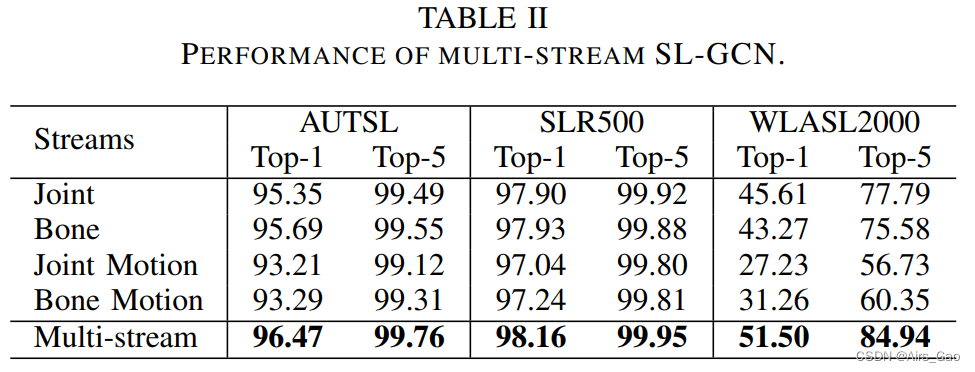
- 四种流中,joint stream的精度最好。
- 多流方法进一步提高了整体精度,这表明我们提出的全身骨架图和多流SL-GCN是非常有效的。
- 表IV显示SL-GCN(关键点2D和3D)在所有单模态方法中表现最好。
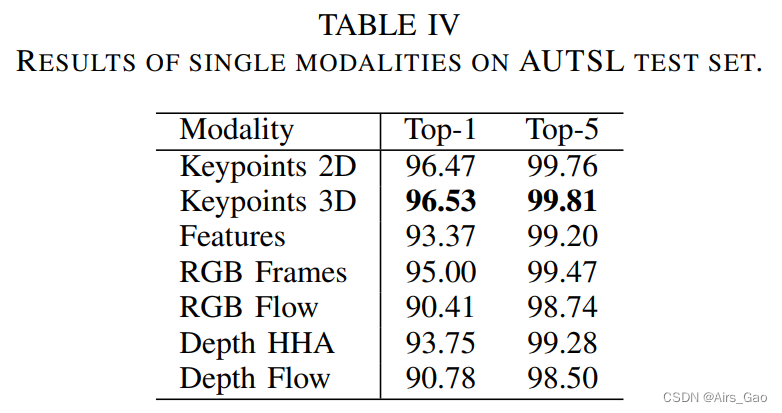
- 由于骨架图的复杂性较低,基于图的方法与大容量方法相比具有重量轻、推理速度快的优点。
- 表III介绍了对拟建SL-GCN的消融研究。
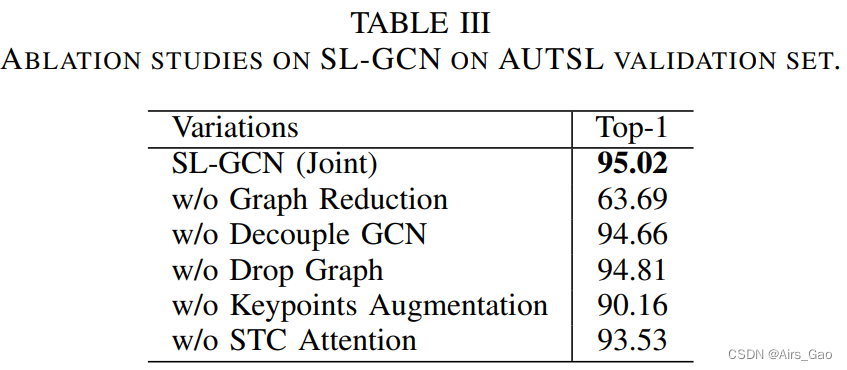
- 我们发现图形约简技术对识别率的贡献最大。
- 由于标注数据的局限性,模型容易过拟合,因此数据增强技术在学习嵌入式动态中也很重要。
- 此外,我们发现DropGraph模块、解耦GCN模块和STC注意机制都有助于最终的性能。
3.3 Multi-modal Performance on AUTSL Dataset
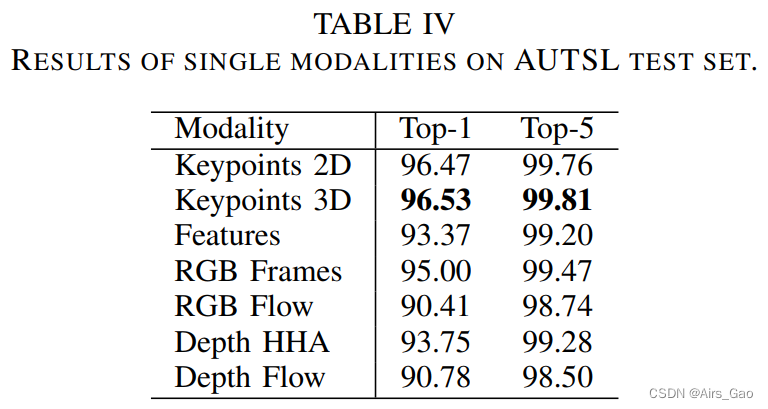
- 所有单模态方法在AUTSL平衡试验集上的结果见表IV。
3.4 Multi-modal Performance on SLR500 Dataset
- isolated Chinese sign language dataset (SLR500) 的性能见表VII:
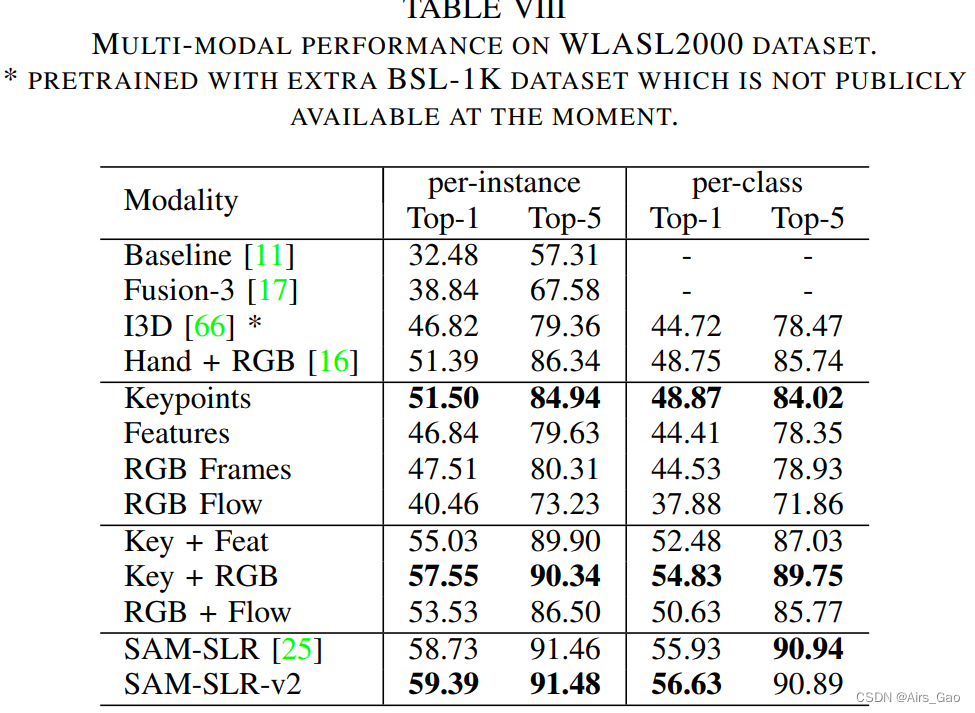
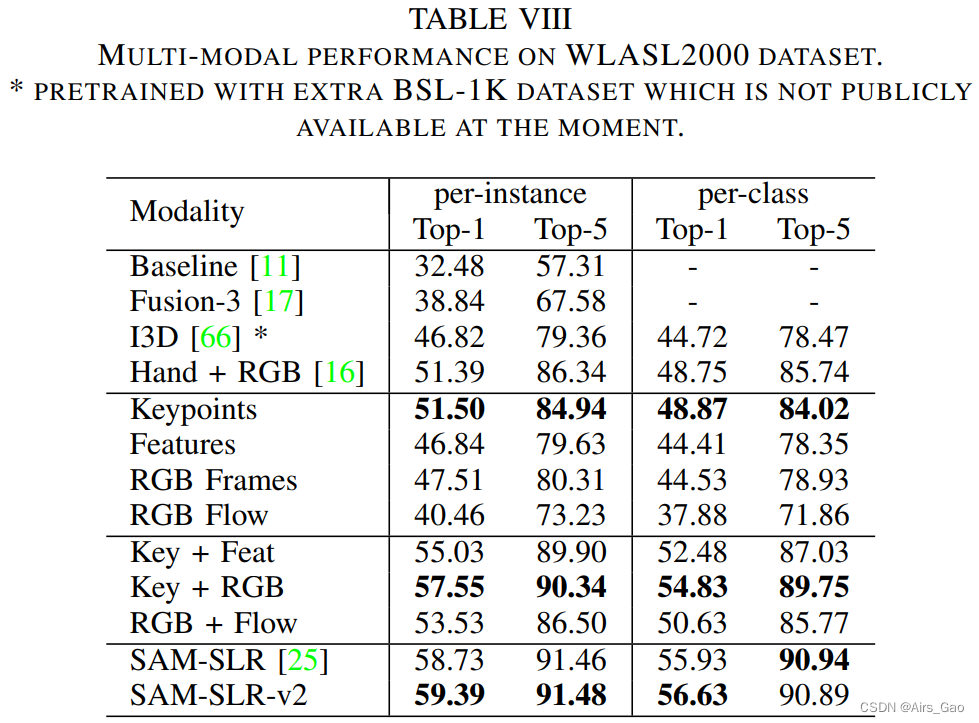
3.5 Multi-modal Performance on WLASL2000
- 由于数据集不是平衡的,我们报告了每个实例的准确性和每个类的准确性。
- 如表VIII所示,关键点模态在所有单模态方法中表现最好(51.50% /实例),因为它对背景的独立性和抗噪声。
3.6 挑战案例和模型局限性
- 图8显示了来自AUTSL数据集的一些具有挑战性的手语识别案例。

- 离线全身姿态估计器可能会由于屏幕外或遮挡而失败,特别是手指,这是姿态估计方法的一个常见问题。然而,手指在表达手势中起着至关重要的作用。其中一些失败可以通过基于rgb的特性来纠正。这就是为什么多模态集成能显著提高识别率的原因。
- 此外,相同的符号可能由不同的签名者执行的非常不同(例如,签名者可以用他们的左手,右手,或双手来完成相同的光泽)。
- 因此,镜像增强在模型训练中非常重要,但需要从更多签名者收集更多的数据。
- 最后,相反的标志可能在视觉上是相似的在单一帧(例如,重vs轻)。要区分这些迹象,需要对时空动力学进行精细的建模。
- 我们发现,基于骨骼的方法是比基于rgb的方法更明智的选择。


















 2177
2177

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









