







 文章介绍了一种名为CyberDemo的新方法,通过在模拟器中增强人类演示,学习处理复杂任务的机器人模仿策略。通过数据增强和模拟器到现实世界的策略转移,CyberDemo在无需大量真实世界数据的情况下,显著提高了机器人操作任务的成功率和泛化能力。
文章介绍了一种名为CyberDemo的新方法,通过在模拟器中增强人类演示,学习处理复杂任务的机器人模仿策略。通过数据增强和模拟器到现实世界的策略转移,CyberDemo在无需大量真实世界数据的情况下,显著提高了机器人操作任务的成功率和泛化能力。
CyberDemo: Augmenting Simulated Human Demonstration for Real-World Dexterous Manipulation解读
论文链接:https://arxiv.org/abs/2402.14795
论文代码:https://cyber-demo.github.io/
论文单位:加州大学圣迭戈分校,南加州大学
论文出处:2024 arxiv
摘要
- 我们介绍了CyberDemo,这是一种机器人模仿学习的新方法,利用模拟人类演示来完成现实世界的任务。
- 通过在模拟环境中整合广泛的数据增强,CyberDemo在转移到现实世界时,处理各种物理和视觉条件,优于传统的域内真实世界演示。
- 尽管在数据收集方面价格低廉且方便,但就各种任务的成功率而言,CyberDemo优于基准方法,并且在以前未见过的对象上表现出通用性。
- 例如,它可以旋转新的tetra-valve和penta-valve,尽管人类只演示了tri-valves。
- 我们的研究证明了模拟人类演示在现实世界灵巧操作任务中的巨大潜力。
1. 简介
- 模仿学习是一种很有前途的机器人操作方法,它有助于从人类示范中获得复杂的技能。
- 然而,这种方法的有效性严重依赖于高质量示范数据的可用性,这通常需要大量的人力来收集数据。
- 在使用多指灵巧手进行操作的情况下,这一挑战进一步扩大,因为任务的复杂性需要非常详细和精确的演示。
- 在模仿学习中,域内演示(In-domain demonstration) 是指直接从部署环境中收集数据,通常用于机器人操作任务。
- 一般认为,解决特定任务的最有效方法是直接从真实的机器人那里收集该任务的演示。这种信念一直被奉为 gold standard,但我们希望挑战它。
- 我们认为,在模拟中收集对于现实世界的人类示范任务,它可以产生更好的结果,不仅因为它不需要真实的硬件,可以远程并行执行,而且还因为它有可能通过仅使用模拟器的数据增强来提高最终任务的性能。这允许生成比初始演示集大数百倍的数据集。
- 然而,虽然现有的研究使用生成的数据集在模拟中训练域内策略,但将策略转移到现实世界的sim2real挑战仍然是一个未解决的问题。
- 在本文中,我们研究了如何利用模拟的人类演示来完成现实世界的机器人操作任务。
- 我们介绍了CyberDemo,这是一个新颖的框架,旨在利用模拟的人类演示,从视觉观察中学习机器人模仿。
- 我们首先通过在模拟环境中使用低成本设备的远程操作收集适量的人类演示数据。
- 然后,CyberDemo将广泛的数据增强纳入原始的人类演示。增强集涵盖了数据收集过程中未遇到的广泛的视觉和物理条件,从而增强了训练策略对这些变化的鲁棒性。这些增强技术在设计时也考虑了下游sim2real传输。
- 我们采用独特的curriculum learning strategy在增强数据集上训练策略,然后使用一些现实世界的演示(3分钟的轨迹)对其进行微调,促进有效地转移到现实世界的条件。
- 虽然仅在真实世界演示中训练的策略可能会受到光照条件、物体几何形状和物体初始姿态的变化的影响,但我们的策略能够在不需要额外人力的情况下处理这些问题。
- 我们的系统利用低成本的运动捕捉设备进行远程操作(即RealSense相机),并且需要最少的人力(即30分钟的演示轨迹),可以学习强大的模仿学习策略。
- 尽管CyberDemo价格低廉,而且需要的人力也很少,但它仍然可以在真实的机器人上取得更好的性能。
- 与预先训练的策略相比,例如R3M在现实世界的演示中进行了微调,CyberDemo在准静态拾取和放置任务上的成功率高出35%,在非准静态旋转任务上的成功率高出20%。
- 在泛化测试中,虽然基线方法在测试过程中难以处理看不见的物体,但我们的方法可以旋转新的四阀和五阀,成功率为42.5%,即使人类演示仅覆盖三阀(图1第二行)。我们的方法还可以处理明显的光干扰(图1的最后一列)。
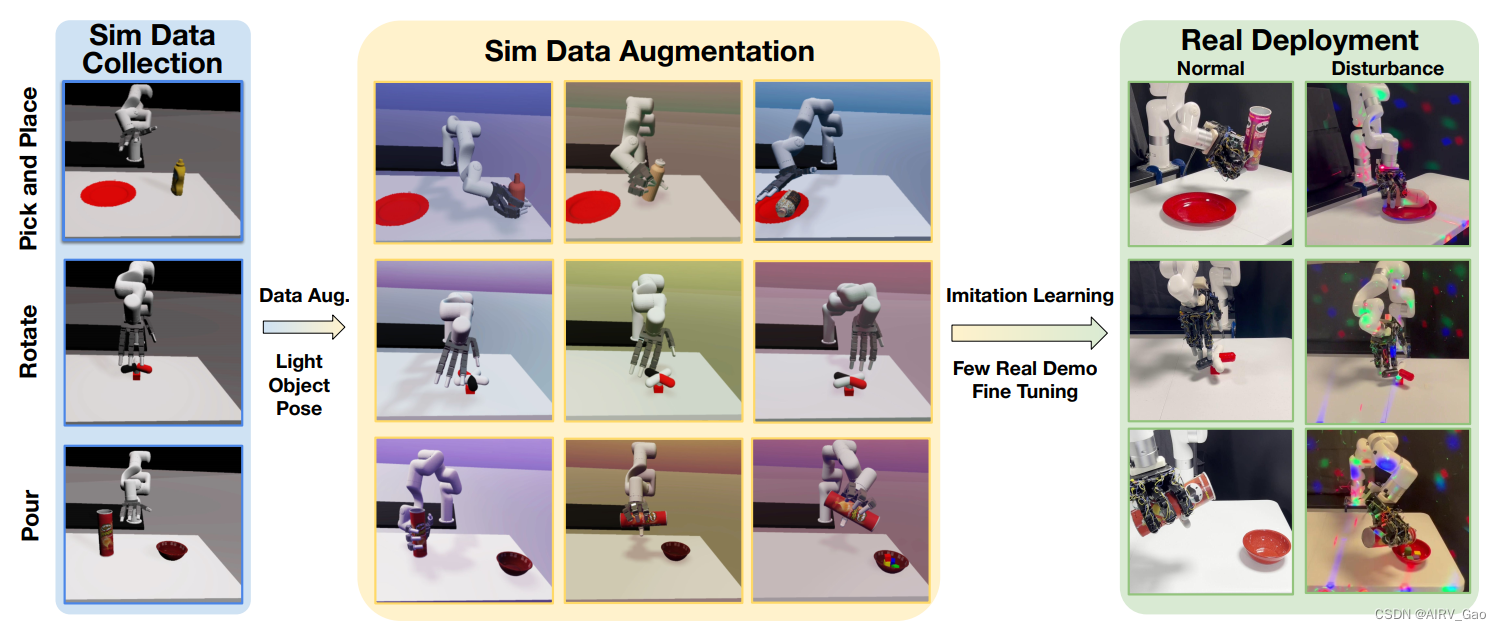
图1. 我们提出了CyberDemo,这是一种新颖的管道,通过使用仿真数据来学习现实世界的灵巧操作。首先,我们在模拟环境(蓝色区域)中收集人类样本,然后在模拟器(黄色区域)中进行大量数据增强。然后,在增强数据上进行训练并在少量真实数据上进行微调的模仿学习模型可以部署在真实机器人上。 - 在我们的消融研究中,我们观察到数据增强的使用,加上模拟器中演示次数的增加,与实际演示中的等效增加相比,可以获得更好的性能。
2. Related Work
2.1 Data for Learning Robot Manipulation
- 模仿学习已被证明是一种有效的机器人操作方法,可以通过一系列演示进行策略训练。
- 许多工作都集中在使用预编程策略,替代数据源如语言和人类视频或广泛的现实世界机器人远程操作构建大型数据集。然而,这些工作主要针对平行夹持器。收集高自由度灵巧手的大规模演示数据集仍然是一个重大挑战。
- 同时,数据扩充通过增加数据分布的多样性,为提高策略泛化提供了可行的策略。
- 先前的研究将增强应用于低层次视觉空间,如颜色抖动、模糊和裁剪,而最近的研究则提出使用生成模型进行语义感知的数据增强。
- 然而,这些增强操作在图像层面,而不是基于物理现实。
- CyberDemo使用物理模拟器将数据扩展到轨迹级别,考虑到视觉和物理变化。
- 我们利用模拟器的便利性来收集机器人演示,并采用sim2real方法将这些演示转移到配备多指人形手的灵巧机器人上。
- 我们的研究强调了一个通用框架,利用模拟演示来进行现实世界的机器人操作。
2.2 机器人的预训练视觉表征
- 大规模自监督学习的最新进展使得视觉表征的发展对下游机器人任务有利。
- 一些研究集中在非机器人数据集上进行预训练,如ImageNet和Ego4D,并利用静态表示进行下游机器人控制。
- 其他研究集中在机器人数据集上的预训练视觉表示,使用依赖于动作的动作监督自学习目标,或利用视频的时间一致性作为学习目标。这些研究主要是为了学习有效训练基于视觉的机器人操作的特征。
- 除了在离线数据集上训练视觉表示,一些研究人员还探索了用于强化学习的奖励函数的学习。
- 与之前的研究不同,我们的工作使用模拟数据进行预训练而不是使用自监督学习进行表征学习。这不仅增强了图像表征的学习,而且通过使用动作信息将任务先验纳入神经网络。
- 通过在模拟环境中进行预训练,操作策略可以更好地推广到具有新几何形状和接触模式的新对象。
2.3 Sim2Real Transfer
- 将技能从模拟场景转移到现实场景的挑战,即sim2real迁移,一直是机器人学习的关键焦点。
- 有些方法利用系统辨识来建立真实系统的数学模型,并辨识物理参数。
- 领域随机化不是校准现实世界的动态,而是生成具有随机属性的模拟环境,并在所有这些环境中训练模型函数。随后的研究表明,随机化参数的选择可以自动化。然而,由于学习鲁棒策略需要大量的样本,领域随机化通常用于涉及数百万交互样本的强化学习。
- 领域自适应(DA) 是一套迁移学习策略,旨在调整模拟与真实之间的数据分布。常见的技术包括领域对抗训练和使用生成模型使模拟图像与真实图像相似。这些数据分析方法大多侧重于弥合视觉差距。然而,解决dynamics gap的挑战仍然很大。
- 对于具有高自由度驱动和复杂交互模式的灵巧机器人手来说,sim2real差距变得更加明显。
- 在这项工作中,我们将领域随机化的概念扩展到模拟器中收集的人类演示,并专注于数据增强技术,该技术可以有效地利用模拟转移到真实的机器人上。
- 我们证明,尽管sim2real存在差距,但在模拟器中收集人类演示可能有显着的好处,而不是仅仅依赖于真实数据。
3. CyberDemo
- 在CyberDemo中,我们首先通过远程操作在模拟器中收集相同任务的人类演示。
- 利用模拟器的采样功能和oracle状态信息,我们以各种方式增强模拟演示,增加它的视觉、运动学、几何多样性,从而丰富了模拟数据集。
- 利用这个增强的数据集,我们训练了一个具有自动课程学习和动作聚合的操作策略。
3.1 收集人体遥操作数据
- 对于本工作中的每个灵巧操作任务,我们在模拟和现实环境中收集了使用远程操作的人类演示。
- 对于真实世界的数据,我们使用Anyteleop中引用的低成本远程操作系统。这种基于视觉的远程操作系统只需要一个摄像头来捕捉人类的手部动作作为输入,然后将其转换为机器人手臂和灵巧手的实时运动命令。我们以30Hz的速率记录每帧的观察(RGB图像、机器人本体感觉)和动作(机器人末端执行器的6D笛卡尔速度、手指关节位置控制目标)。在这项工作中,我们只收集了真实机器人上每个任务三分钟的机器人轨迹。
- 对于模拟中的数据,我们在SAPIEN模拟器中构建真实世界的任务环境,以复制真实场景中使用的表和对象。值得注意的是,对于远距操作,不像强化学习设置那样需要奖励设计和观察空间,使得在模拟器中设置新任务的过程相对简单。我们采用相同的远程操作系统Anyteleop来收集模拟器中的人类演示。
3.2 在模拟器中增强人类演示
- 与现实世界的数据收集不同,我们仅限于记录物理传感器的观察结果,如相机RGB图像和机器人本体感觉,模拟系统使我们能够记录虚拟环境中的真实状态和联系信息。
- 与现实世界的数据相比,模拟的这种独特优势为模拟演示提供了更全面的数据格式。
- 因此,我们可以利用这些模拟演示的演示重播技术,这在真实世界的数据中是不可行的。
- 在模拟器中开发数据增强技术时,必须记住,最终目标是将训练好的策略部署到真实的机器人中。因此,增强功能应侧重于在现实世界中可能遇到的视觉和动态变化。
- 此外,我们的目标是将操作策略推广到数据收集过程中没有遇到的新对象。例如,在图3中仅收集有关三阀的数据时操作四阀。
- 具体来说,我们选择增加照明条件、相机视图和物体纹理,以增强策略对视觉变化的鲁棒性。
- 此外,我们修改了物体的几何形状以及机器人和物体的初始姿态,以提高策略对动态变化的鲁棒性。
(1)随机化摄像机视图。在演示收集和最终评估之间精确地对齐摄像机视图,更不用说在模拟和现实之间了,这构成了重大挑战。为了解决这个问题,我们在训练过程中随机化相机姿势,并重播模拟器的内部状态,以从新的相机视图呈现图像序列。与标准的图像增强技术(如裁剪和移动)不同,我们的方法以物理逼真的方式尊重透视投影。
(2)随机光和纹理。为了促进sim2real传输并提高策略对视觉变化的鲁棒性,我们随机化了灯光和物体的视觉属性(图3,右下)。光属性包括方向、颜色、阴影特性和环境光照。物体属性包括镜面、粗糙度、金属量和纹理。与相机视图随机化类似,我们可以简单地重放模拟状态以呈现新的图像序列。
(3)添加不同的对象。在这种方法中,我们用新对象替换了原始演示中被操纵的对象(图3右上)。然而,直接重放相同的轨迹是行不通的,因为物体的形状不同。相反,我们用高斯噪声扰动原始演示的动作序列以产生新的轨迹。这些轨迹提供了合理的操纵策略,但与最初的略有不同。通过在模拟器中进行高性价比的采样,我们可以枚举摄动直到成功。需要注意的是,这种技术在现实世界的演示中是可行的。
(4)随机化目标姿态。强化学习中提高泛化能力的一种常见方法是在重置过程中随机化对象姿态。然而,通过增强模仿学习数据来实现类似的结果就不那么直观了。我们提出了灵敏度感知的运动学增强(Sensitivity-Aware Kinematics Augmentation) 来随机化人体演示的物体姿态。这种方法不是在原始轨迹之前添加新的轨迹,而是修改原始演示中每一步的动作,以适应对象姿态的变化。该方法包括两个步骤:(i)将整个轨迹划分为若干段,计算每个段的灵敏度;(ii)根据灵敏度修改末端执行器位姿轨迹,计算新动作。
3.3 学习Sim2Real策略
- 给定一个增强模拟数据集,我们训练了一个视觉操作策略,该策略以图像和机器人本体感觉作为输入来预测机器人的动作。
- 在人类远程操作演示中,机器人的动作既不是摩拉维亚式的,也不是时间相关的。
- 为了解决这个问题,我们的策略被训练为预测动作块而不是每一步的动作,使用ACT (action Chunking with Transformers)。这种方法产生了更平滑的轨迹,减少了复合误差。
- 尽管我们的数据增强功能能够适应不同的视觉和动态条件,但机器人控制器仍然存在类似的差距。这种差距在我们的任务中变得更具挑战性,其中末端执行器是高自由度多手指灵巧的手。这种控制器间隙会严重影响非准静态任务,如旋转阀门,如图1第二行所示。
- 为了缩小这个差距,我们使用一小组真实世界的演示(3分钟的轨迹)来微调我们的网络。然而,由于人类样本的数据收集模式在模拟和现实之间存在差异,对真实数据进行直接微调有过拟合的风险。
- 为了确保更平滑的sim2real传输,我们采用了几种技术,这些技术分别为:
(1)自动课程学习(Automatic Curriculum Learning)。课程学习和数据增强技术经常一起使用,以提供更顺畅的训练过程。遵循先前强化学习工作中的课程设计思想,我们设计了一种适用于我们的模仿学习情境的课程学习策略。在训练之前,我们将第3.2节中的增强分为四个级别,以增加复杂性,如图2所示。
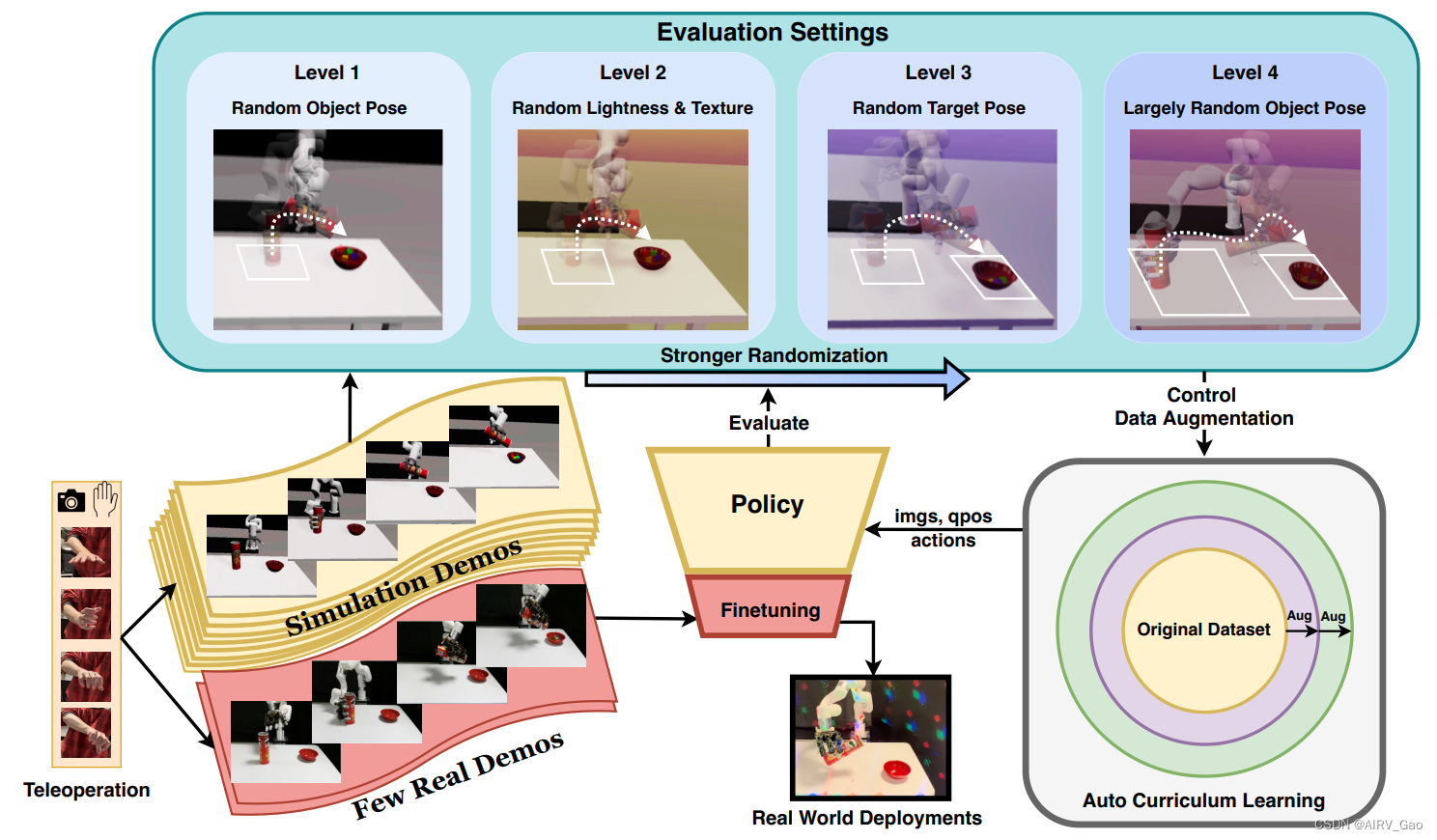
图2. CyberDemo Pipeline. (1)首先,我们通过基于视觉的远程操作收集模拟和真实演示。(2)在此之后,我们在模拟数据上训练策略,并结合提出的数据增强技术。(3)在训练过程中,我们应用automatic curriculum learning,根据任务表现逐步增强随机性尺度。(4)最后,在将策略部署到现实世界之前,使用一些实际演示对其进行微调。
(2)小运动的动作聚合(Action Aggregation for Small Motion)。人类的演示通常包括噪音,特别是在灵巧的手操作时。例如,在演示轨迹中可能发生轻微的震动和无意的停止,潜在地破坏了训练过程。为了解决这个问题,我们将以小动作为特征的步骤聚合在一起,将这些动作合并为单个动作。在实践中,我们为末端执行器和手指运动设置阈值,以辨别给定的运动是否符合小的条件。通过聚合过程,我们可以消除人类动作中的小操作噪声,使模仿学习策略能够从状态-动作轨迹中提取有意义的信息。
















 699
699











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









