







【北上广深杭等大厂面试|高频AI算法题】机器学习篇…本篇介绍介绍决策树算法的ID3和C4.5???附代码(二)
【北上广深杭等大厂面试|高频AI算法题】机器学习篇…本篇介绍介绍决策树算法的ID3和C4.5???附代码(二)
文章目录
欢迎宝子们点赞、关注、收藏!欢迎宝子们批评指正!
祝所有的硕博生都能遇到好的导师!好的审稿人!好的同门!顺利毕业!
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文:
可访问艾思科蓝官网,浏览即将召开的学术会议列表。会议详细信息可参考:https://ais.cn/u/mmmiUz
决策树算法详解:ID3 和 C4.5
决策树是一种基于树形结构的分类算法,用于根据特征的属性值对样本进行分类。决策树的构建是通过选择不同特征作为“节点”来完成的,每个节点表示一个特征,每个分支代表该特征的一个值,最终的叶子节点代表分类结果。ID3(Iterative Dichotomiser 3)和C4.5是决策树算法的两种经典变种,它们在构建决策树的过程中有一些不同的选择标准和方法。
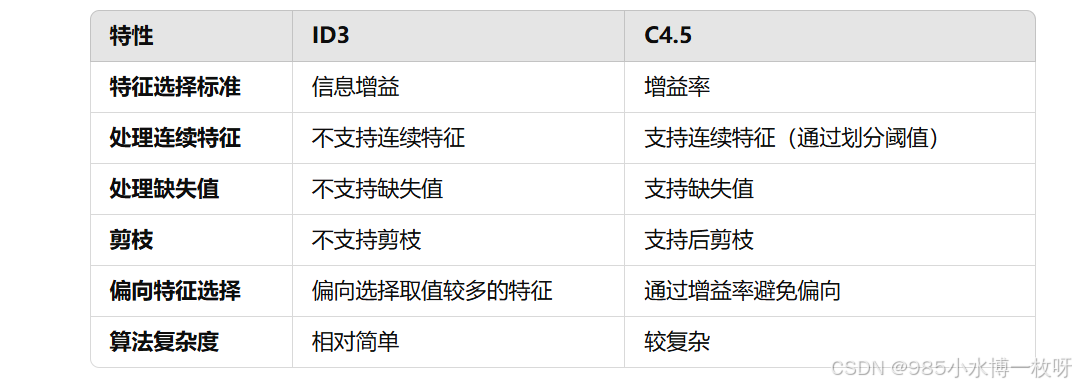
3. ID3与C4.5的比较
4. Python实现(以C4.5为例)
- 虽然
scikit-learn中并没有直接实现C4.5算法,但它实现了一个决策树算法——DecisionTreeClassifier,其背后的实现是CART(Classification And Regression Trees)。
下面是一个简单的例子,展示如何使用scikit-learn来训练决策树:
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
from sklearn.tree import export_text
# 加载鸢尾花数据集
data = load_iris()
X = data.data
y = data.target
# 拆分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建决策树模型
model = DecisionTreeClassifier(criterion='entropy') # 使用信息增益作为分裂准则(ID3)
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 计算精度
accuracy = accuracy_score(y_test, y_pred)
print(f"模型精度:{accuracy:.2f}")
# 打印决策树
tree_rules = export_text(model, feature_names=data.feature_names)
print(tree_rules)
总结
- ID3算法通过信息增益来选择最佳特征,虽然简单易懂,但它存在偏向选择取值多特征的问题。
- C4.5改进了ID3算法,采用增益率作为特征选择标准,支持连续特征和缺失值,并通过剪枝技术减少过拟合,具有更强的实用性。
- ID3和C4.5都是经典的决策树算法,它们为后续的决策树算法(如CART、C5.0等)奠定了基础。
2025年生成式人工智能与数字媒体国际学术会议(GADM 2025)
- 2025 International Conference on Generative Artificial Intelligence and Digital Media
- 大会官网:www.icgadm.org
- 大会时间:2025年3月14-17日
- 大会地点:中国-大理
- 审核周期:5-7个工作日
- 收录检索:EI Compendex, Scopus


















 646
646

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











