







命名实体识别系列:
一、隐马尔科夫模型(HMM)
二、最大熵模型(ME)
三、条件随机场(CRF)
四、实体级/词级别评估(precision, recall, f1-value)
CRF、HMM、ME对比
CRF效果最好,其次是ME,再次是HMM模型。 这是因为CRF利用到了最多的上下文关系,分析了更多的特征,ME模型次之,然而HMM模型每个隐含状态只依赖于前一个状态,对于上下文的利用十分不足,导致效果最差。相应的CRF运行时间最长,其次是ME,HMM运行时间最短
实现思路
因为词级别的评价较为简单,在这里仅以实体级别的评价为例子
命名实体识别的评价指标及计算公式
准确率 = 正确预测的样本数量/预测中所有样本的数量
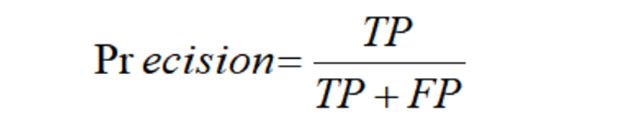
召回率 = 正确预测的样本数量/标准结果中所有样本的数量
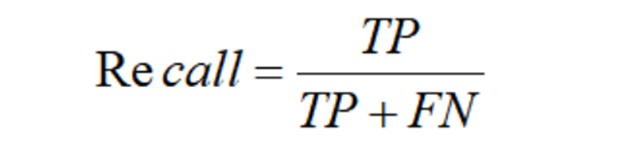
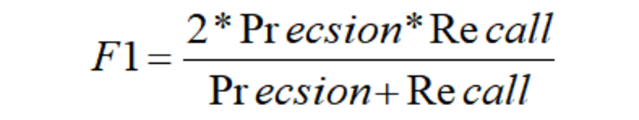
流程图如下所示(针对实体级别):
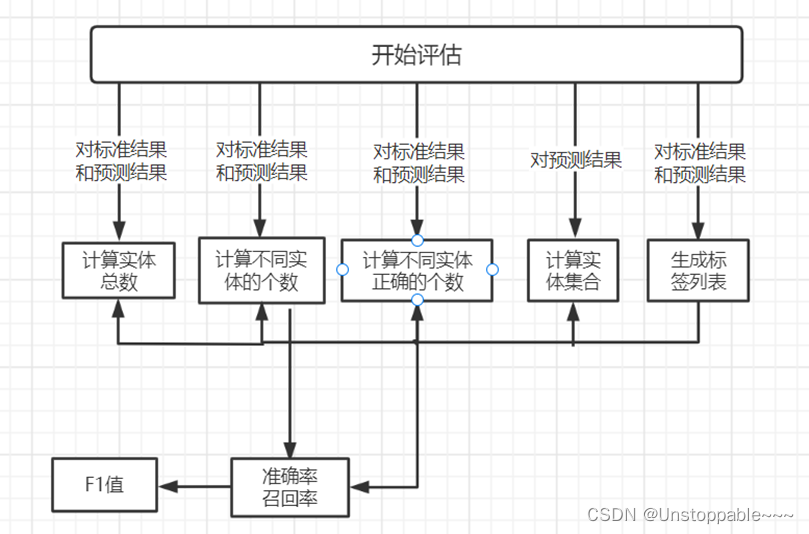
基本步骤(实体级别):
- 分别计算标准结果和预测结果的实体个数、各个实体的个数以及预测正确的各个实体个数。
- 根据公式,准确率为正确的各个实体个数/预测结果的各个实体个数,召回率为准确率为正确的各个实体个数/标准结果的各个实体个数,F1为2pr/p+r
- 计算加权均值:对每个指标(p,r,f1)进行计算,将所有的实体的指标乘该类实体的个数求和再除以实体的总个数,得到加权均值的结果。
类函数(实体级别):
1.cal_precision(self): 计算每类实体的准确率
2.cal_recall(self):计算每类实体的召回率
3.cal_f1(self):计算每类实体的f1值
4.report_scores(self):将测评结果以表格的形式打印出来
5._cal_wighted_average(self):计算各个值的加权平均数
6.count_entity_dict(self, tag_list): 计算tag_list中每个实体对应的个数,可以输入predict_tags或std_tags并输出其实体的个数
5. count_correct_entity(self):计算每种实体被正确预测的个数
实体包括:address、book、company、game、government、movie、name、organization、position、scene(10个)
6. count_entity(self, tag_list):计算tag_list中所有实体的总个数
外部函数:
7. flatten_lists(lists): 将列表的列表拼成一个列表
结果分析:
词级别的测试结果远好于实体级别,究其原因,在于词级别只要正确产生了一个实体中的部分词,都将其记为正确,无论整个实体是否正确。在计算时相对正确的比例远大于实体级别的结果(在实体级别中,只要实体中有一个预测错误,整个实体就算是错误),实体级别的测评结果更能反映此次实体标注的性能。
代码实现
词级别的评价
from collections import Counter
class Metrics(object):
"""用于评价模型,计算每个标签的精确率,召回率,F1分数"""
def __init__(self, golden_tags, predict_tags, remove_O=False):
# [[t1, t2], [t3, t4]...] --> [t1, t2, t3, t4...]
self.golden_tags = flatten_lists(golden_tags) #将已知标签和预测的标签拼成列表
self.predict_tags = flatten_lists(predict_tags)
if remove_O: # 将O标记移除,只关心实体标记
self._remove_Otags()
# 辅助计算的变量
self.tagset = set(self.golden_tags) #标签集合(不重复)
self.correct_tags_number = self.count_correct_tags() #某个tag预测正确的次数
self.predict_tags_counter = Counter(self.predict_tags) #预测标签各个标签的个数
self.golden_tags_counter = Counter(self.golden_tags) #源文件标签各个标签的个数
# 计算精确率
self.precision_scores = self.cal_precision()
# 计算召回率
self.recall_scores = self.cal_recall()
# 计算F1分数
self.f1_scores = self.cal_f1()
def cal_precision(self):
#计算每个tag的准确率吧
precision_scores = {}
for tag in self.tagset:
#correct_tags_number为tag计算正确的次数 predict_tags_counter所有predict_tag的个数
precision_scores[tag] = self.correct_tags_number.get(tag, 0) / \
max(1e-10, self.predict_tags_counter[tag])
return precision_scores
def cal_recall(self):
#计算每个tag的召回率
recall_scores = {}
for tag in self.tagset:
#correct_tags_number为tag计算正确的次数 golden_tags_counter为tag出现的总次数
recall_scores[tag] = self.correct_tags_number.get(tag, 0) / \
max(1e-10, self.golden_tags_counter[tag])
return recall_scores
def cal_f1(self):
f1_scores = {}
for tag in self.tagset:
p, r = self.precision_scores[tag], self.recall_scores[tag]
f1_scores[tag] = 2 * p * r / (p + r + 1e-10) # 加上一个特别小的数,防止分母为0
return f1_scores
def report_scores(self):
"""将结果用表格的形式打印出来,像这个样子:
precision recall f1-score support
B-LOC 0.775 0.757 0.766 1084
I-LOC 0.601 0.631 0.616 325
B-MISC 0.698 0.499 0.582 339
I-MISC 0.644 0.567 0.603 557
B-ORG 0.795 0.801 0.798 1400
I-ORG 0.831 0.773 0.801 1104
B-PER 0.812 0.876 0.843 735
I-PER 0.873 0.931 0.901 634
avg/total 0.779 0.764 0.770 6178
"""
# 打印表头
header_format = '{:>9s} {:>9} {:>9} {:>9} {:>9}'
header = ['precision', 'recall', 'f1-score', 'support']
print(header_format.format('', *header))
row_format = '{:>9s} {:>9.4f} {:>9.4f} {:>9.4f} {:>9}'
# 打印每个标签的 精确率、召回率、f1分数
for tag in self.tagset:
print(row_format.format(
tag,
self.precision_scores[tag],
self.recall_scores[tag],
self.f1_scores[tag],
self.golden_tags_counter[tag]
))
# 计算并打印平均值
avg_metrics = self._cal_weighted_average()
print(row_format.format(
'avg/total',
avg_metrics['precision'],
avg_metrics['recall'],
avg_metrics['f1_score'],
len(self.golden_tags)
))
def count_correct_tags(self):
"""计算每种标签预测正确的个数(对应精确率、召回率计算公式上的tp),用于后面精确率以及召回率的计算"""
correct_dict = {}
for gold_tag, predict_tag in zip(self.golden_tags, self.predict_tags): #zip()用于将数据打包成元组
if gold_tag == predict_tag: #每当匹配的情况就将correct_dict[gold_tag]加一
if gold_tag not in correct_dict: #若该标签不在已知标签字典中,将其加入
correct_dict[gold_tag] = 1
else:
correct_dict[gold_tag] += 1
return correct_dict
def _cal_weighted_average(self):
weighted_average = {}
total = len(self.golden_tags) #标准标签的总数
# 计算weighted precisions:
weighted_average['precision'] = 0.
weighted_average['recall'] = 0.
weighted_average['f1_score'] = 0.
for tag in self.tagset:
size = self.golden_tags_counter[tag] #标准文件各个标签的个数
weighted_average['precision'] += self.precision_scores[tag] * size
weighted_average['recall'] += self.recall_scores[tag] * size
weighted_average['f1_score'] += self.f1_scores[tag] * size
for metric in weighted_average.keys():
weighted_average[metric] /= total
return weighted_average
def _remove_Otags(self):
length = len(self.golden_tags)
O_tag_indices = [i for i in range(length)
if self.golden_tags[i] == 'O']
self.golden_tags = [tag for i, tag in enumerate(self.golden_tags)
if i not in O_tag_indices]
self.predict_tags = [tag for i, tag in enumerate(self.predict_tags)
if i not in O_tag_indices]
print("原总标记数为{},移除了{}个O标记,占比{:.2f}%".format(
length,
len(O_tag_indices),
len(O_tag_indices) / length * 100
))
def report_confusion_matrix(self):
"""计算混淆矩阵"""
print("\nConfusion Matrix:")
tag_list = list(self.tagset)
# 初始化混淆矩阵 matrix[i][j]表示第i个tag被模型预测成第j个tag的次数
tags_size = len(tag_list)
matrix = []
for i in range(tags_size):
matrix.append([0] * tags_size)
# 遍历tags列表
for golden_tag, predict_tag in zip(self.golden_tags, self.predict_tags):
try:
row = tag_list.index(golden_tag)
col = tag_list.index(predict_tag)
matrix[row][col] += 1
except ValueError: # 有极少数标记没有出现在golden_tags,但出现在predict_tags,跳过这些标记
continue
# 输出矩阵
row_format_ = '{:>7} ' * (tags_size + 1)
print(row_format_.format("", *tag_list))
for i, row in enumerate(matrix):
print(row_format_.format(tag_list[i], *row))
def flatten_lists(lists):
"""
将列表的列表拼成一个列表
:param lists:
:return:
"""
flatten_list = []
for l in lists:
if type(l) == list:
flatten_list += l
else:
flatten_list.append(l)
return flatten_list
实体机级别的评价‘
class Metrics(object):
"""用于实体级别评价模型,计算每个标签的精确率,召回率,F1分数"""
def __init__(self, std_tags, predict_tags):
"""
初始化对照文件中的标签列表、预测文件的标签列表、以及
:param std_tags:
:param predict_tags:
"""
#将按句的标签列表转化成按字的标签列表 如 [[t1, t2], [t3, t4]...] --> [t1, t2, t3, t4...]
self.std_tags = flatten_lists(std_tags) #将已知标签和预测的标签拼成列表
self.predict_tags = flatten_lists(predict_tags)
#计数器
self.std_entity_counter = self.count_entity_dict(self.std_tags) #标准结果的各实体个数
self.predict_entity_counter = self.count_entity_dict(self.predict_tags) #预测结果的各实体个数
print("标准各实体个数", self.std_entity_counter)
print("预测各实体个数", self.predict_entity_counter)
self.std_entity_number = self.count_entity(self.std_tags) #标准结果的实体总个数
# self.predict_entity_number = self.count_entity(self.predict_tags) #预测结果的实体总个数
print("标准实体数", self.std_entity_number)
# print("预测实体数", self.predict_entity_number)
self.corrent_entity_number = self.count_correct_entity()
print("正确的实体", self.corrent_entity_number)
self.entity_set = set(self.std_entity_counter)
print("实体集合", self.entity_set)
# 计算精确率
self.precision_scores = self.cal_precision()
print("各个实体的准确率", self.precision_scores)
# 计算召回率
self.recall_scores = self.cal_recall()
print("各个实体的召回率", self.recall_scores)
# 计算F1分数
self.f1_scores = self.cal_f1()
print("各个实体的f1值", self.f1_scores)
# 计算加权均值
self.wighted_average = self._cal_wighted_average()
print("各项指标的加权均值", self.wighted_average)
def cal_precision(self):
#计算每类实体的准确率
precision_scores = {}
#某实体正确的个数 / 预测中某实体所有的个数
for entity in self.entity_set: #这里计算结果可能有问题
precision_scores[entity] = self.corrent_entity_number.get(entity, 0) / max(1e-10, self.predict_entity_counter[entity])
return precision_scores
def cal_recall(self):
#计算每类尸体的召回率
recall_scores ={}
for entity in self.entity_set:
recall_scores[entity] = self.corrent_entity_number.get(entity, 0) / max(1e-10, self.std_entity_counter[entity])
return recall_scores
def cal_f1(self):
#计算f1值
f1_scores = {}
for entity in self.entity_set:
p, r = self.precision_scores[entity], self.recall_scores[entity]
f1_scores[entity] = 2 * p * r / (p + r + 1e-10)
return f1_scores
def report_scores(self):
"""
将结果用表格的形式打印出来
:return:
"""
# 打印表头
header_format = '{:>9s} {:>9} {:>9} {:>9} {:>9}'
header = ['precision', 'recall', 'f1-score', 'support']
print(header_format.format('', *header))
row_format = '{:>9s} {:>9.4f} {:>9.4f} {:>9.4f} {:>9}'
# 打印每个实体的p, r, f
for entity in self.entity_set:
print(row_format.format(
entity,
self.precision_scores[entity],
self.recall_scores[entity],
self.f1_scores[entity],
self.std_entity_counter[entity] #这部分是support的值
))
#计算并打印平均值
avg_metrics = self._cal_wighted_average()
print(row_format.format(
'avg/total',
avg_metrics['precision'],
avg_metrics['recall'],
avg_metrics['f1_score'],
self.std_entity_number
))
def _cal_wighted_average(self):
#计算加权均值
weighted_average = {}
total = self.std_entity_number #标准实体的总数
#计算weighted precisions:
weighted_average['precision'] = 0.
weighted_average['recall'] = 0.
weighted_average['f1_score'] = 0.
for entity in self.entity_set:
size = self.std_entity_counter[entity] #标准结果各个实体的个数
weighted_average['precision'] += self.precision_scores[entity] * size
weighted_average['recall'] += self.recall_scores[entity] * size
weighted_average['f1_score'] += self.f1_scores[entity] * size
for metric in weighted_average.keys():
weighted_average[metric] /= total
return weighted_average
#以下注释掉的代码为将B-company E-book这种BMSE格式符合情况但标签前后不一致,不计入预测结果的实体数中
# def count_entity_dict(self, tag_list):
# """
# 计算每个实体对应的个数,注意BME、BE、S结构才为实体,其余均不计入,B-company和E-book也不计入
# :param tag_list:
# :return:
# """
# enti_dict = {}
# flag = 0 # 初始状态设置为0
# B_word = '' #初始状态B设为空
# for tag in tag_list:
# if 'B-' in tag and flag == 0: #当B-出现时,将状态变为1
# flag = 1
# B_word = tag[2:]
# if 'M-' in tag and flag == 1:
# M_word = tag[2:]
# if M_word != B_word: #当M和B标签不同时,不为实体将B_word设为空
# B_word = ''
# flag = 0
# if 'E-' in tag and flag == 1: #E前有B则可以判定为一个实体
# flag = 0 #状态回归初始
# E_word = tag[2:]
# tag = tag[2:]
# if E_word == B_word:
# if tag not in enti_dict:
# enti_dict[tag] = 1
# else:
# enti_dict[tag] += 1
# B_word = ''
# if 'S-' in tag: #当S-出现,直接加一
# B_word = ''
# flag = 0
# tag = tag[2:]
# if tag not in enti_dict:
# enti_dict[tag] = 1
# else:
# enti_dict[tag] += 1
# if 'O' in tag: #出现O-时,将状态设为0 B_word设为0
# B_word = ''
# flag = 0
# return enti_dict
def count_entity_dict(self, tag_list):
"""
计算每个实体对应的个数,注意BME、BE、S结构才为实体,其余均不计入 B-company E-company算实体
:param tag_list:
:return:
"""
enti_dict = {}
flag = 0 # 初始状态设置为0
for tag in tag_list:
if 'B-' in tag and flag == 0: #当B-出现时,将状态变为1
flag = 1
if 'E-' in tag and flag == 1: #E前有B则可以判定为一个实体
flag = 0 #状态回归初始
tag = tag[2:]
if tag not in enti_dict:
enti_dict[tag] = 1
else:
enti_dict[tag] += 1
if 'S-' in tag: #当S-出现,直接加一
flag = 0
tag = tag[2:]
if tag not in enti_dict:
enti_dict[tag] = 1
else:
enti_dict[tag] += 1
if tag == 'O': #出现O-时,将状态设为0 B_word设为0
flag = 0
return enti_dict
def count_correct_entity(self):
"""
计算每种实体被正确预测的个数
address、book、company、game、government、movie、name、organization、position、scene
:return:
"""
correct_enti_dict = {}
flag = 0 #初始状态,表示等待下一个开始状态
for std_tag, predict_tag in zip(self.std_tags, self.predict_tags): #zip()用于将数据打包成元组
if 'B-' in std_tag and std_tag == predict_tag and flag == 0: #当以B-开头且标签相等时
flag = 1 #表示已经有B
if 'M-' in std_tag and std_tag == predict_tag and flag == 1: #M前已经有过B
flag = 1
if 'E-' in std_tag and std_tag == predict_tag and flag == 1:
flag = 0 #状态重新调整回初始值
std_tag = std_tag[2:]
if std_tag not in correct_enti_dict:
correct_enti_dict[std_tag] = 1
else:
correct_enti_dict[std_tag] += 1
if 'S-' in std_tag and std_tag == predict_tag and flag == 0:
std_tag = std_tag[2:]
if std_tag not in correct_enti_dict:
correct_enti_dict[std_tag] = 1
else:
correct_enti_dict[std_tag] += 1
if std_tag != predict_tag:
flag = 0
return correct_enti_dict
def count_entity(self, tag_list):
"""
计算标准列表中的实体个数,因为标准结果中无错误分类,所以实体的个数可以直接计算为E标签和S标签数目之和
:return:
"""
entity_count = 0 #记录实体数量
for tag in tag_list: #遍历所有标签
if 'E-' in tag:
entity_count += 1
if 'S-' in tag:
entity_count += 1
return entity_count
def flatten_lists(lists):
"""
将列表的列表拼成一个列表
:param lists:
:return:
"""
flatten_list = []
for l in lists:
if type(l) == list:
flatten_list += l
else:
flatten_list.append(l)
return flatten_list
# metrics = Metrics(test_tag_lists, pred_tag_lists)
# metrics.report_scores()

















 3286
3286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









