







安装python
1、到官网下载选择对应版本进行安装:https://www.python.org/downloads/release/python-364/

如果使用压缩包的话还需要配置环境变量,安装包见下图

2、安装完后,在cmd命令行下输入python,若出现如图信息则表示安装成功

安装scrapy
1、https://www.lfd.uci.edu/~gohlke/pythonlibs/ 是一个windows的编译好的Python第三方库,我们下载好对应自己Python版本的库即可。分别搜索pip、lxml、twisted、scrapy,找到对应版本下载,以lxml为例:

lxml-4.1.1-cp36-cp36m-win_adm64.whl,表示lxml的版本为3.6,对应的python版本为3.6-64bit。如果不知道python版本的见上一步。
安装命令:pip install lxml
其他的安装以此类推,出现successfully则表示安装成功。
安装pywin32
1、scrapy安装成功后,还要安装pywin32,地址:https://sourceforge.net/projects/pywin32/files/pywin32/Build%20220/傻瓜式安装即可。
至此准备工作差不多了,我们来进行一个简单实例。
实例
网络爬虫的第一步就是根据URL,获取网页的HTML信息。在Python3中,可以使用urllib.request和requests进行网页爬取。
- urllib库是python内置的,无需我们额外安装,只要安装了Python就可以使用这个库。
- requests库是第三方库,需要我们自己安装。
requests库的github地址:https://github.com/requests/requests
如果使用压缩包,则进入setup.py文件层,执行命令python setup.py install;
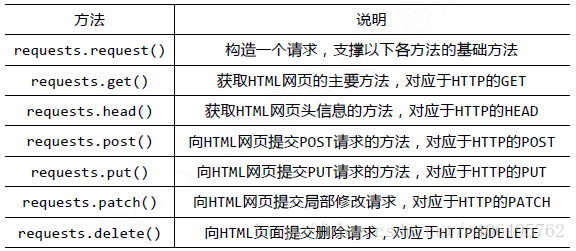
requests库的基础方法如下:
例子:
# -*- coding:UTF-8 -*-
import requests
if __name__ == '__main__':
target = 'http://gitbook.cn/'
req = requests.get(url=target)
print(req.text)至此,一个简单的入门例子就完成了~
参考:
http://blog.csdn.net/c406495762/article/details/60156205
http://blog.csdn.net/c406495762/article/details/78123502















 60万+
60万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









